В лекции Стэнфордского университета по обучению с подкреплением (CS234) подробно рассматриваются методы обучения интеллектуальных агентов на основе человеческого опыта и обратной связи. Профессор разбирает эволюцию подходов от классического имитационного обучения и обратного обучения с подкреплением до современных систем, использующих отзывы человека (RLHF), которые лежат в основе настройки крупных языковых моделей. Основное внимание уделяется математическим основаниям и практическому применению алгоритмов, позволяющих ИИ эффективно сопоставлять свои действия со сложными, неявными предпочтениями людей.
🔄 Повторение пройденного: DAGGER против клонирования поведения 1:11
В начале занятия лектор проводит краткий опрос для проверки понимания пройденного материала, напоминая о ключевых различиях между базовыми методами имитационного обучения. Клонирование поведения (Behavior Cloning) позволяет успешно свести задачу обучения с подкреплением к стандартному обучению с учителем (Supervised Learning). Агент берет готовые демонстрации эксперта и пытается напрямую выучить отображение состояний в действия, не требуя при этом знания модели динамики среды.
Однако у клонирования поведения есть серьезный недостаток — уязвимость к каскадному накоплению ошибок. Когда ИИ ошибается, он сдвигается в те области распределения состояний, которые отсутствовали в обучающей выборке. Для иллюстрации этой проблемы приводится пример с гоночным треком: как только беспилотный автомобиль немного выезжает за пределы трассы, он теряется, поскольку не знает, как возвращаться назад.
Для решения этой проблемы был разработан алгоритм DAGGER. По словам профессора, ключевое отличие и одновременно главный минус DAGGER заключается в необходимости постоянного присутствия человека-эксперта в процессе обучения. Эксперт выполняет роль тренера: он просматривает траектории, пройденные агентом, и для каждого момента указывает оптимальное действие, помогая разбирать гипотетические сценарии ошибок.
📈 От ручного кодирования к языковым моделям 3:12
Эволюция технологий обучения с подкреплением за последние годы привела к тесной интеграции RL с крупными языковыми моделями (LLM). При подготовке к текущей лекции профессор провела эксперимент и попросила ChatGPT написать программу, демонстрирующую работу алгоритма RLHF (Reinforcement Learning From Human Feedback). Всего за пять секунд нейросеть сгенерировала рабочий код, использующий Q-обучение и другие компоненты для симуляции обучения на основе человеческих отзывов.
Как подчеркивает лектор, когда данный курс впервые запускался в Стэнфорде в 2017 году, подобный уровень автоматизации программирования был абсолютно невозможен. Современные успехи ИИ во многом опираются на комбинацию мощных аппроксиматоров функций (таких как архитектура Transformer) и алгоритмов RL.
В качестве анонса лектор упоминает, что на следующем занятии выступит один из аспирантов Стэнфорда — соавтор инновационного метода прямой оптимизации предпочтений (DPO, Direct Preference Optimization). Данная работа завоевала награду Best Paper Runner-Up на престижной конференции NeurIPS. Метод DPO начинает активно вытеснять или превосходить классический RLHF на множестве бенчмарков, и команда разработчиков уже готовит к публикации на arXiv новое расширение этой технологии.
🚖 Метод максимальной энтропии в обратном обучении (Max Entropy IRL) 5:40
Имитационное обучение незаменимо в сценариях, где человеку трудно формализовать и математически записать точную функцию вознаграждения. В качестве примеров таких данных лектор выделяет:
- Запись точных траекторий движений манипулятора робота при обучении захвату чашки.
- Данные электронных медицинских карт, фиксирующие реальные решения практикующих врачей при лечении пациентов.
Целью обратного обучения с подкреплением (Inverse RL) является восстановление скрытой функции вознаграждения на основе анализа этих траекторий. Это позволяет глубже понять истинные мотивы и критерии, которыми руководствуются люди при принятии решений.
Главной математической преградой в Inverse RL выступает фундаментальная неоднозначность: одному и тому же наблюдаемому оптимальному поведению может соответствовать бесконечное множество функций вознаграждения. Более того, тривиальное нулевое вознаграждение формально совместимо вообще с любой траекторией.
Для преодоления этой неопределенности в 2008 году Брайан Зибарт и его коллеги из Университета Карнеги — Меллона предложили использовать принцип максимальной энтропии (Max Entropy IRL). В то время Зибарт исследовал поведение водителей такси в Питтсбурге. Ему требовалось понять, как таксисты неявно балансируют между факторами пройденного расстояния, плотности трафика и стоимости проезда по платным дорогам, чтобы на основе этого обучить навигационную систему оптимальному планированию маршрутов.
Принцип максимальной энтропии гласит: из всех распределений вероятностей, согласованных с имеющимися данными, следует выбирать то, которое обладает наибольшей энтропией. Иными словами, ИИ должен отдавать предпочтение распределению траекторий, которое полностью удовлетворяет ограничениям экспертных демонстраций, но при этом остается максимально случайным и непредвзятым во всем остальном.
🧮 Математические основания Макс-Энтропийного подхода 17:11
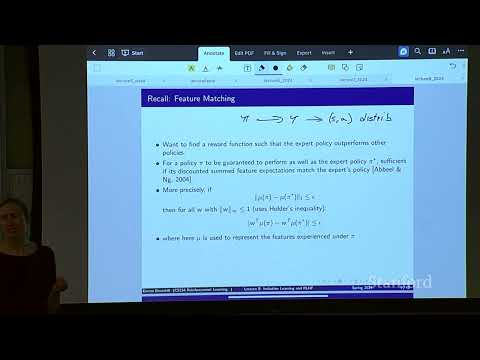
В случае линейной функции вознаграждения задача сводится к поиску такого распределения траекторий, математическое ожидание признаков (features) которого совпадает с признаками, извлеченными из демонстраций эксперта. Если две политики индуцируют одинаковое распределение по состояниям и действиям, они будут получать идентичное вознаграждение.
Чтобы определить аналитическую форму искомого распределения траекторий $\tau$, лектор использует метод множителей Лагранжа для оптимизации функции энтропии с учетом ограничений. Записав производную лагранжиана по вероятности конкретной траектории $P(\tau)$ и приравняв ее к нулю, математически доказывается, что вероятность траектории становится строго пропорциональной экспоненте от ее суммарного вознаграждения:
$$P(\tau | \phi) = \frac{1}{Z(\phi)} e^{R_\phi(\tau)}$$
где $Z(\phi)$ — это нормирующая константа (или статистическая сумма), обеспечивающая корректность распределения вероятностей, а $\phi$ — вектор настраиваемых параметров функции вознаграждения.
Данный вывод относит распределение к классу экспоненциальных семейств. Опираясь на классическую теоретическую работу Эдвина Джейнса 1957 года, исследователи осознали, что исходную задачу максимизации энтропии при заданных ограничениях можно элегантно переформулировать как задачу максимизации правдоподобия (Maximum Likelihood Estimation) наблюдаемых экспертных данных. В таком случае единственной неизвестной переменной остается вектор параметров $\phi$.
Проводя дифференцирование функции логарифмического правдоподобия по $\phi$, профессор выводит финальное уравнение для шага градиентного спуска:
$$\nabla_\phi J(\phi) = \sum_{\tau^ \in D} \nabla_\phi R_\phi(\tau^) - |D| \sum_{\tau} P(\tau | \phi) \nabla_\phi R_\phi(\tau)$$
Это означает, что для корректировки параметров вознаграждения алгоритм должен вычислять разность между признаками из экспертного датасета $D$ и ожидаемыми признаками траекторий при текущей политике агента.
Если среда является табличной (tabular) и ее динамика полностью известна, то частоту посещения состояний агентом можно эффективно рассчитывать с помощью динамического программирования по времени. Полный цикл классического алгоритма выглядит следующим образом:
- Вычисление оптимальной политики агента при текущих параметрах вознаграждения $R_\phi$ (например, методом итерации ценности — Value Iteration).
- Расчет частоты посещения состояний среды (State Visitation Frequencies).
- Вычисление градиента целевой функции правдоподобия.
- Обновление вектора параметров вознаграждения $\phi$ и повторение всего процесса до сходимости.
🛑 Ограничения и развитие теории Max Entropy IRL 44:37
В ходе лекционного интерактива профессор задает вопрос: какие именно шаги описанного алгоритма критически зависят от явного знания модели динамики среды? Правильный ответ — первый и второй шаги. Для работы алгоритма Value Iteration и для точного аналитического проброса частот посещения состояний на следующий временной шаг ИИ обязан знать вероятности переходов среды.
Профессор подчеркивает, что предположение о полной известности динамики — это огромный и зачастую нереалистичный барьер для практического применения технологии. Мы практически никогда не знаем точную математическую модель среды, когда речь идет о моделировании решений практикующего врача или хирурга.
Серьезный прорыв в устранении этого ограничения совершила Челси Финн в рамках своей докторской диссертации в Стэнфорде. В публикации 2016 года она доказала, что алгоритм Max Entropy IRL можно успешно масштабировать на сложные, непрерывные пространства состояний с помощью глубоких нейросетей, полностью убрав при этом требование о предварительном знании модели динамики переходов.
При этом лектор делает важное философское замечание: Max Entropy IRL не претендует на то, чтобы найти настоящую функцию вознаграждения, заложенную в голове у человека. Алгоритм лишь подбирает математически непротиворечивую модель наград, которая наилучшим образом объясняет демонстрации, сохраняя распределение максимально нейтральным.
👥 Эволюция обратной связи: от Софи до парных предпочтений 52:19
Использование человеческого ввода для обучения ИИ имеет богатую историю. Около двадцати лет назад Андреа Томаз и Синтия Бризил из MIT представили проект под названием «Кухня Софи» (Sophie's Kitchen). Автономный агент обучался выполнять кулинарные рецепты, одновременно получая сигналы и от виртуальной кухни, и от человека, выступавшего в роли постоянного наставника. Другим примером стал фреймворк TAMER, созданный Брэдом Ноксом и Питером Стоуном в Техасском университете в Остине. С его помощью агента успешно обучали игре в Tetris, выстраивая параметрическую модель вознаграждения на лету на основе быстрых реакций человека.
Тем не менее, постоянное менторство страдает от той же проблемы, что и DAGGER: люди физически не могут сидеть перед экраном часами и размечать тысячи игровых сессий. На шкале вовлеченности человека сформировался явный компромиссный оптимум — использование парных сравнений (Pairwise Comparisons). Человеку не нужно самостоятельно придумывать идеальные демонстрации или выставлять абстрактные скалярные баллы (например, пытаться решить, заслуживает ли ответ оценку 17.3 или -7 миллиардов). Ему достаточно просто посмотреть на два готовых варианта поведения системы и выбрать, какой из них удачнее.
Исторически эта идея пришла из рекомендательных и ранжирующих систем поисковых движков, разработанных Айсоном Юэ и Торстеном Йоахимсом в Корнелле. Позже этот подход был адаптирован для робототехники и беспилотного транспорта профессором Стэнфорда Дорсой Садиг. Например, при настройке беспилотного автомобиля человеку гораздо проще выбрать левое видео, где машина корректно затормозила, чем правое видео с аварией, помогая ИИ улавливать тончайшие нюансы вождения во время града или внезапных остановок.
🎲 Модель Брэдли-Терри и социальный выбор 1:00:38
Для математического моделирования зашумленного выбора человека применяется модель Брэдли-Терри, сформулированная около 70 лет назад. Поведение человека считается стохастическим: предполагается, что в его голове есть скрытая (латентная) функция вознаграждения, но при сравнении объектов он может ошибаться. Вероятность того, что эксперт предпочтет вариант $B_i$ варианту $B_j$, описывается формулой:
$$P(B_i \succ B_j) = \frac{e^{R(B_i)}}{e^{R(B_i)} + e^{R(B_j)}}$$
Лектор приводит шуточную аналогию с пиццей: если у человека нет явных предпочтений между пиццей на толстом и тонком тесте, то скрытые награды равны, и модель выдает вероятность выбора ровно 50%. Но если человек сильно любит пиццу на толстом тесте, отношение экспонент мгновенно сдвинет вероятность выбора к 90% или 95%. Важное свойство модели Брэдли-Терри — ее транзитивность, что позволяет математически выстраивать цепочки предпочтений и ранжировать объекты.
Профессор связывает эти концепции с теорией социального выбора и вычислительной экономикой, где существуют различные определения понятия «лучшего» объекта:
- Победитель Кондорсе (Condorcet winner): объект, который в прямых парных сравнениях побеждает любой другой доступный объект с вероятностью выше 50%. Это крайне высокая планка для алгоритмов.
- Победитель Коупленда (Copeland winner): объект, который набирает наибольшее количество чистых побед в раундах против всех остальных конкурентов, то есть лидирует в среднем.
- Победитель Борда (Borda winner): объект, максимизирующий общее ожидаемое количество очков по дискретной шкале исходов.
В машинном обучении сбор таких данных организуется в формате так называемых «дуэльных бандитов». Накопленные кортежи сравнений размечаются бинарным признаком (1 — если выбран первый вариант, 0 — если второй), после чего нейросеть оптимизируется с помощью стандартной функции кросс-энтропии, выполняя задачу логистической регрессии для точной подгонки параметров функции наград.
🤖 Обучение с подкреплением на основе предпочтений (RLHF) 1:08:38
Описанный аппарат парных сравнений траекторий лег в основу статьи 2017 года по глубокому RL на основе человеческих предпочтений. В этом исследовании агента в симуляторе MuJoCo успешно обучили делать идеальный кувырок назад (backflip).
Агенту не задавали формулу кувырка математически. Вместо этого обычные люди-разметчики отсматривали короткие трехсекундные клипы анимации и кликали мышкой «лево» или «право», указывая, какое движение больше похоже на кувырок. Системе потребовалось всего около 900 бит человеческой обратной связи для построения качественной модели награды. Это на несколько порядков меньше и эффективнее объемов данных, необходимых классическим алгоритмам вроде Deep Q-Learning, которые требуют миллионов итераций вслепую.
В финальной части лекции профессор демонстрирует слайды из профильного курса по NLP, объясняя архитектуру работы ChatGPT. Весь пайплайн развертывается в три последовательных этапа:
- SFT (Supervised Fine-Tuning): первичный сбор идеальных демонстраций ответов от людей-экспертов и базовое обучение модели (фактически — клонирование поведения).
- Reward Model Training: генерация нескольких вариантов ответов на один промпт, их ранжирование людьми-асессорами и обучение нейросети-критика по модели Брэдли-Терри.
- PPO (Proximal Policy Optimization): финальная донастройка языковой модели с помощью алгоритма RL, где в качестве функции вознаграждения выступает обученная на втором шаге нейросеть.
Как заявляет лектор, с фундаментальной точки зрения современный коммерческий RLHF — это сложнейшая задача многозадачного мета-обучения с подкреплением (Meta-RL). В отличие от робота, выполняющего один изолированный кувырок, языковая модель обязана выучить универсальную функцию вознаграждения, способную корректно оценивать качество выполнения абсолютно любых, даже никогда не встречавшихся ранее в обучении текстовых заданий — например, требования сочинить оригинальную сказку про лягушек.



