В арсенале инструментов глубокого обучения сверточные нейронные сети (CNN) занимают лидирующие позиции в задачах распознавания образов. Однако эффективность этих сетей зависит не только от самих сверток, но и от вспомогательных механизмов, таких как слои объединения (pooling layers), которые позволяют оптимизировать вычисления и повышать устойчивость детектируемых признаков.
🧱 Суть и механизмы слоев объединения 0:00
Слои объединения (pooling layers) используются в нейронных сетях для постепенного уменьшения пространственного размера представления данных. Как отмечает Эндрю Ын, это необходимо для решения двух ключевых задач :
- Ускорение вычислений: за счет сокращения объема данных в последующих слоях.
- Повышение устойчивости (robustness): слой делает систему менее чувствительной к небольшим сдвигам и искажениям признаков.
Наиболее распространенным типом является Max pooling. Принцип его работы прост: если у нас есть входной массив данных (например, 4x4), мы делим его на несколько регионов . В каждом регионе выбирается только одно — максимальное — значение.
Для вычисления выходных данных используются два основных гиперпараметра :
- Размер фильтра (f): определяет размер области (например, 2x2), из которой извлекается максимум.
- Шаг или страйд (s): определяет, на сколько позиций смещается фильтр для следующего вычисления.
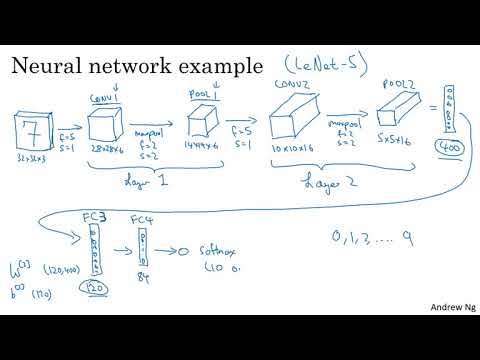
В примере Эндрю Ына при использовании фильтра $f=2$ и страйда $s=2$ входная матрица 4x4 превращается в матрицу 2x2. Это происходит потому, что фильтр «перепрыгивает» на две клетки, не перекрывая предыдущие области .
👁️ Интуиция Max Pooling: почему это работает? 2:00
Эндрю Ын предлагает наглядную интерпретацию работы Max pooling через призму детектирования признаков . Представьте, что каждое число в матрице — это активация нейрона, сигнализирующая о наличии определенного признака (например, вертикальной линии, глаза кошки или усов) .
Логика Max pooling заключается в следующем:
- Если признак обнаружен где-либо в пределах рассматриваемого квадрата (высокое число в матрице), то в итоговом уменьшенном представлении сохраняется информация о его наличии .
- Если признака нет ни в одной из точек региона, то максимальное значение останется низким .
При этом Эндрю Ын честно признает: хотя эта интуиция часто упоминается в литературе, главной причиной популярности Max pooling является его доказанная эффективность в ходе многочисленных экспериментов . По словам эксперта, вряд ли кто-то может на 100% подтвердить, что именно эта «логика детектирования» является фундаментальной причиной успеха архитектуры .
⚙️ Технические особенности и гиперпараметры 3:44
Ключевым отличием слоев объединения от сверточных слоев является отсутствие обучаемых параметров . У градиентного спуска «нет работы» в слое pooling: как только вы зафиксировали гиперпараметры (f и s), расчет становится фиксированной функцией, которую сеть просто выполняет .
- Отсутствие обучения: В процессе обратного распространения ошибки (backprop) параметры pooling-слоя не меняются .
- Работа с каналами: Если вход имеет несколько каналов (например, RGB или объемное представление признаков), операция выполняется независимо для каждого канала . То есть количество каналов на входе и на выходе всегда совпадает .
- Паддинг (padding): В отличие от сверток, в pooling-слоях дополнение нулями (padding) используется крайне редко. В подавляющем большинстве случаев $p=0$ .
- Типовые наборы: Часто используются параметры $f=2, s=2$, что приводит к двукратному уменьшению высоты и ширины изображения . Также встречается вариант $f=3, s=2$ .
⚖️ Max Pooling против Average Pooling 6:40
Существует альтернативный вид объединения — Average pooling (усредняющее объединение). Вместо поиска максимума здесь вычисляется среднее арифметическое всех значений в окне фильтра .
Несмотря на наличие альтернативы, в современных архитектурах Max pooling доминирует. По наблюдениям Эндрю Ына, Average pooling применяется гораздо реже, за одним важным исключением :