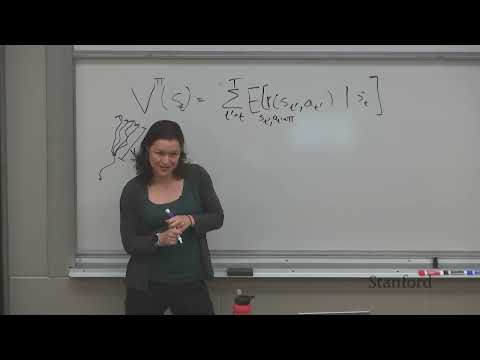Современные подходы в обучении с подкреплением: от Policy Gradient к Actor-Critic 0:05
Обучение с подкреплением (Reinforcement Learning, RL) представляет собой фундаментальную парадигму искусственного интеллекта, где агент взаимодействует со средой, совершая действия и получая обратную связь в виде вознаграждений. В рамках девятой лекции курса Stanford CS221 преподаватель подробно разбирает переход от табличных методов к современным алгоритмам обучения на основе функций аппроксимации и градиентов стратегии (Policy Gradient). Лекция охватывает эволюцию от оценки марковских процессов принятия решений (MDP) до передовых методов Actor-Critic, позволяющих решать задачи с огромным пространством состояний.
🧠 Табличные методы и ограничения масштабирования 17:06
Традиционные методы обучения с подкреплением, такие как Q-learning и SARSA, полагаются на «табличный» подход, где для каждой пары состояние-действие (SA-пара) хранится значение $Q(s, a)$.
- Проблема масштабирования: В реальных задачах, таких как управление роботами (где состоянием является изображение) или генерация текста (где состоянием выступает последовательность токенов), размер пространства состояний становится колоссальным.
- Функция аппроксимации: Вместо хранения значений в таблице предлагается параметризовать функцию $Q_{\theta}(s, a)$ с помощью весов $\theta$. Это позволяет использовать мощные модели машинного обучения (например, нейронные сети) для оценки значений в высокоразмерных пространствах.
- Обучение: Целью является минимизация функции потерь, где в качестве «цели» (target) выступает значение, полученное через bootstrapping (использование текущей оценки будущего вознаграждения).
По мнению лектора, хотя в табличном случае Q-learning гарантированно сходится, при использовании аппроксимации функций теоретические гарантии сходимости к оптимальной стратегии в общем случае отсутствуют, однако методы часто находят приемлемые локальные оптимумы.
📈 Методы Policy Gradient: оптимизация стратегии напрямую 34:29
Если методы на основе ценности (value-based) сначала оценивают «качество» действий, а затем извлекают стратегию, то методы градиента стратегии (policy-based) обучают классификатор, который отображает состояния непосредственно в распределение вероятностей действий.
- Имитационное обучение: Если в распоряжении есть экспертные демонстрации (последовательности идеальных действий), задача сводится к обычному обучению с учителем (supervised learning).
- Reinforce: Это классический алгоритм градиента стратегии, который не требует эксперта. Агент совершает «прогоны» (rollouts), собирая траектории, и обновляет параметры стратегии, взвешивая действия на основе полученной полезности (utility).
- Теорема градиента стратегии: Она позволяет аппроксимировать градиент ожидаемой полезности через выборку траекторий, что превращает задачу поиска стратегии в задачу стохастической оптимизации.
📉 Уменьшение дисперсии и Actor-Critic
Основная проблема алгоритмов типа Reinforce — высокая дисперсия оценок, что замедляет сходимость.
- Контроль дисперсии: Использование контрольных переменных (control variates) позволяет уменьшить шум в оценках градиента, не внося смещения (bias).
- Базовые линии (Baselines): Введение функции $B(s)$, зависящей только от состояния, позволяет «вычитать» среднее ожидаемое значение, стабилизируя обновление параметров.
- Actor-Critic: Это гибридный подход, где «Актер» (Actor) определяет стратегию, а «Критик» (Critic) оценивает текущее состояние с помощью функции ценности (например, Q-функции). По словам лектора, эти методы сочетают достоинства Policy Gradient (прямая оптимизация стратегии) и методов, основанных на ценности (bootstrapping для снижения дисперсии).