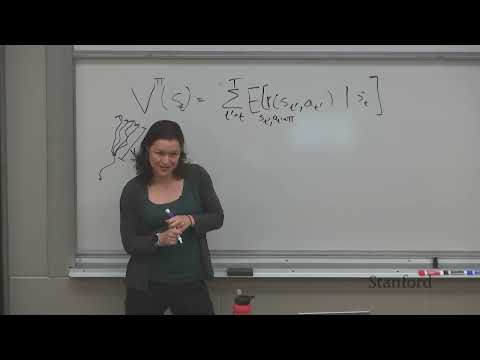
В рамках курса Стэнфордского университета CS224R Deep Reinforcement Learning прошла лекция, посвященная методам Actor-Critic. Эти алгоритмы лежат в основе современных систем управления гуманоидными роботами и обучения больших языковых моделей (LLM), таких как PPO. Лекция фокусируется на переходе от «шумных» градиентов стратегии к более стабильным методам, использующим функции ценности для оценки действий агента.
🔄 Рекап: Ограничения градиентов стратегии 0:05
Перед погружением в новые методы лектор напомнил основы онлайн-обучения с подкреплением (RL). Процесс итеративен: сбор данных текущей стратегией, обновление параметров и повторение цикла. В стандартном алгоритме Policy Gradient (PG) вероятность действий увеличивается, если они привели к награде выше среднего (базовой линии), и уменьшается в противном случае.
Однако у «чистых» градиентов стратегии есть критические недостатки:
- On-policy природа: Данные можно использовать только один раз для одного шага градиента, что крайне неэффективно по памяти и вычислениям.
- Высокая дисперсия: Оценка градиента на основе одной траектории очень зашумлена. Например, если робот сделал шаг вперед, но потом упал, PG может ошибочно «наказать» полезное действие (шаг вперед) из-за отрицательного финала всей траектории.
📊 Математический фундамент: V, Q и Advantage 4:27
Для решения проблем дисперсии вводятся функции ценности, которые оценивают «хорошесть» состояния или конкретного действия.
Основные объекты оценки:
- V-функция ($V^\pi(s)$): Ожидаемая сумма наград, если агент начинает в состоянии $s$ и далее следует стратегии $\pi$.
- Q-функция ($Q^\pi(s, a)$): Ожидаемая сумма наград, если агент в состоянии $s$ сначала совершает конкретное действие $a$, а уже потом следует стратегии $\pi$.
- Функция преимущества (Advantage, $A^\pi(s, a)$): Разница между $Q$ и $V$. Она показывает, насколько действие $a$ лучше или хуже среднего действия в данном состоянии.
$$A^\pi(s, a) = Q^\pi(s, a) - V^\pi(s)$$
Аналогия с обучением игре на барабанах 12:08
Лектор привел наглядный пример: вы хотите научиться играть на барабанах за месяц. Ваши действия: сидеть на пляже ($a_1$), смотреть ТВ ($a_2$) или практиковаться ($a_3$).
- Если ваша текущая стратегия — всегда сидеть на пляже, то ценность состояния $V$ равна 0.
- Если вы один раз выберете действие «практика», $Q(s, a_3)$ может стать равным 1 (или вероятности успеха), а преимущество $A$ будет положительным.
- Это позволяет агенту понять, что практика — выгодное отклонение от текущей ленивой стратегии.
🎭 Архитектура Actor-Critic 18:26
Методы Actor-Critic объединяют два подхода. Идея заключается в том, чтобы заменить сырую сумму наград из траектории на оценку функции преимущества.
- Actor (Актер): Нейронная сеть стратегии $\pi_\theta(a|s)$, которая выбирает действия.
- Critic (Критик): Нейронная сеть функции ценности $V_\phi(s)$, которая оценивает действия Актера.
Использование Критика позволяет Актеру получать более стабильный сигнал для обучения. Вместо того чтобы ждать конца эпизода, Актер может корректировать поведение на каждом шаге, основываясь на предсказаниях Критика о будущих наградах.
🧠 Policy Evaluation: Как обучить Критика 27:03
Главный вопрос: как заставить нейросеть точно предсказывать $V^\pi(s)$? Существует три основных подхода к формированию меток для обучения (таргетов):
1. Метод Монте-Карло (Monte Carlo) 41:05
Критик обучается предсказывать реальную сумму наград, полученную в ходе эпизода от текущего момента до конца.
- Плюс: Непредвзятая (unbiased) оценка.
- Минус: Огромная дисперсия, так как случайность в среде накапливается к концу траектории.
2. Бутстрапинг и TD-learning 44:21
Критик использует свои собственные предсказания для следующего шага в качестве цели обучения: $$Target = r_t + V(s_{t+1})$$ Это называется временной разницей (Temporal Difference).
- Плюс: Низкая дисперсия. Информация обновляется на каждом шаге.
- Минус: Предвзятость (bias) на ранних этапах обучения, пока сеть сама ошибается.
3. N-step Returns (Гибрид) 53:10
Промежуточный вариант: мы суммируем реальные награды за $n$ шагов, а затем добавляем предсказанную ценность оставшегося пути. Это позволяет балансировать между точностью и стабильностью.
📉 Дисконтирование и финальный алгоритм 56:23
В задачах с бесконечным или очень длинным горизонтом сумма наград может стремиться к бесконечности. Для этого вводится коэффициент дисконтирования $\gamma$ (обычно 0.9–0.99). Лектор пояснил это через аналогию со смертью: использование $\gamma$ эквивалентно допущению, что на каждом шаге агент может с вероятностью $1 - \gamma$ попасть в «состояние смерти» с нулевой наградой.
Полный цикл Actor-Critic: 1:00:27
- Сбор данных: Прогнать текущую стратегию в среде и собрать батч траекторий.
- Оценка ценности: Обновить веса Критика $V_\phi(s)$, используя методы MC или TD.
- Расчет преимущества: Вычислить $\hat{A}(s, a) = r + \gamma V(s') - V(s)$.
- Обновление стратегии: Сделать шаг градиента для Актера, увеличивая вероятность действий с высоким $A$.
- Повтор: Перейти к шагу 1 с новой стратегией.
Этот подход позволяет эффективно использовать данные и обучать агентов в сложных условиях, где награды могут быть редкими или отложенными во времени.




