Новое исследование специалистов Google Brain — Уильяма Федуса, Баррета Зоффа и Ноама Шазира — перевернуло представление о масштабировании нейросетей. Разработанная ими архитектура Switch Transformer позволила создать модель с рекордным 1 триллионом параметров, при этом сохранив вычислительные затраты на уровне значительно меньших моделей.
🚀 Прорыв в масштабировании: от миллиардов к триллионам 0:00
На протяжении последних лет индустрия ИИ следовала правилу: чем больше модель, тем она лучше. Однако классические трансформеры (такие как GPT-3 с его 175 миллиардами параметров) сталкиваются с проблемой линейного роста вычислительной сложности . Если вы увеличиваете количество параметров в 10 раз, вам требуется в 10 раз больше вычислительных мощностей (FLOPS) для каждого прохода данных.
Янник Килчер подчеркивает, что Switch Transformer радикально меняет этот подход за счет внедрения «разреженности» (sparsity) . Ключевая особенность новой архитектуры заключается в том, что:
- Модель может иметь 1 триллион параметров, но для обработки одного токена используется лишь малая их часть.
- Количество операций с плавающей точкой (FLOPS) на один проход остается таким же, как у гораздо более компактных моделей .
- Это позволяет достигать высокой точности при сохранении скорости работы, сопоставимой с моделями уровня T5.
Килчер отмечает, что заявление о «триллионе параметров» во многом является маркетинговым и демонстрационным ходом . По его мнению, сам по себе этот масштаб не всегда дает лучшие результаты — модель Switch Transformer на 1 трлн параметров в некоторых тестах уступает своим более сбалансированным версиям меньшего размера (например, Switch XXL) из-за неудачных компромиссов при проектировании слоев .
🧠 Архитектура Mixture of Experts и «умный» переключатель 1:02
Switch Transformer базируется на концепции Mixture of Experts (MoE) — «смеси экспертов». В обычном трансформере каждый токен (слово или часть слова) проходит через один и тот же слой полносвязной нейронной сети (Feed-Forward Layer). В MoE этот слой заменяется набором «экспертов» — множеством параллельных слоев .
Ранее считалось, что для стабильного обучения токен нужно отправлять как минимум к двум экспертам одновременно. Switch Transformer доказывает обратное:
- Жесткая маршрутизация (Hard Routing): Система направляет токен только к одному, самому подходящему эксперту .
- Специализация: Янник приводит аналогию, где разные эксперты могут специализироваться на обработке существительных, глаголов или знаков препинания .
- Обучаемый роутер: Модель сама учится определять, какой эксперт лучше справится с конкретным токеном в данном контексте . Для этого используется специальная матрица весов маршрутизатора, работающая по принципу, похожему на механизм внимания (attention).
Такой подход позволяет увеличивать общее количество параметров в модели в 4, 8 или даже 100 раз, просто добавляя новых экспертов, при этом путь каждого отдельного токена через сеть не удлиняется .
📊 Эффективность и инженерные хитрости 4:37
Одним из главных преимуществ архитектуры является ускорение обучения. По словам автора видео, модели Switch демонстрируют колоссальный прирост эффективности по сравнению с базовой моделью T5 . Они быстрее достигают заданного уровня потерь (loss) как по времени, так и по количеству шагов обучения.
Однако работа с такими гигантами требует решения ряда инженерных проблем:
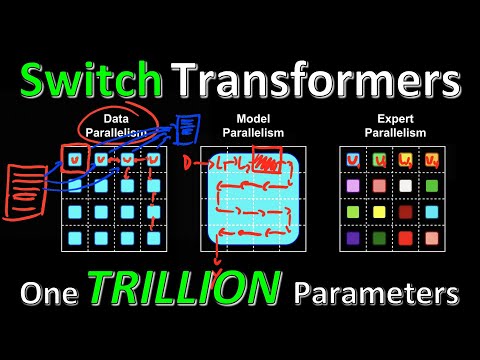
- Распределение памяти (Sharding): Модель весом в триллион параметров невозможно уместить в одну видеокарту. Google использует библиотеку Mesh TensorFlow для распределения экспертов по разным вычислительным узлам .
- Проблема переполнения: Поскольку токены распределяются независимо, может возникнуть ситуация, когда один эксперт перегружен («очередь» из токенов), а другие простаивают. Инженеры ввели понятие «пропускной способности эксперта» (capacity factor) для балансировки нагрузки .
Чтобы обучение не «разваливалось» при использовании только одного эксперта на токен, команда Google применила три ключевых приема :
- Выборочная точность (Selective Precision): Основная коммуникация между машинами идет в 16-битном формате для экономии трафика, но внутри эксперта вычисления переводятся в 32 бита для сохранения точности градиентов .
- Экспертный Dropout: К слоям экспертов применяется более высокий коэффициент выпадения нейронов (dropout), чем к остальной сети, что предотвращает переобучение в разреженных структурах .
- Масштабируемая инициализация: Исследователи обнаружили, что уменьшение стандартного масштаба начальных весов в 10 раз значительно повышает стабильность системы .
🌍 Многоязычность и дистилляция 26:47
Switch Transformer показал отличные результаты в многоязычных тестах. По данным статьи, модель превосходит плотные (dense) аналоги в каждом проверенном языке, причем прирост производительности виден в логарифмическом масштабе .
Интересным аспектом является возможность дистилляции. Огромную разреженную модель можно использовать как «учителя» для тренировки маленькой, но эффективной плотной модели .
- Google удалось сжать гигантскую модель до размеров стандартной T5.
- Такая «дистиллированная» модель работает на 30% лучше, чем если бы аналогичная T5 обучалась с нуля привычными методами .
- Это позволяет сохранить до 90-95% преимуществ огромной архитектуры в компактном форм-факторе, пригодном для широкого распространения .
Подводя итог, Янник Килчер отмечает, что Switch Transformer — это не просто погоня за цифрой в триллион, а важный шаг к созданию сверхэффективных систем, где вычислительные ресурсы расходуются только там, где они действительно необходимы.