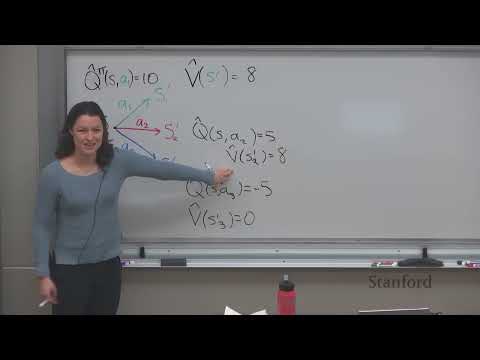Оптимизация языковых моделей: от обучения к предпочтениям пользователя 🚀 0:05
В лекции 9 курса Stanford CS224R: Deep Reinforcement Learning преподаватель Стэнфордского университета подробно разбирает современные методы «дообучения» (post-training) языковых моделей, позволяющие превратить их из простых предсказателей текста в полезных интеллектуальных помощников. Основная проблема заключается в том, что базовые модели, обученные на гигантских корпусах данных интернета, лишь прогнозируют следующее слово, что не всегда соответствует целям пользователя. Для исправления этого разрыва применяются методы тонкой настройки (fine-tuning) и оптимизации на основе человеческих предпочтений, такие как RLHF и DPO.
🧠 От предсказания токенов к ассистентам 4:02
Базовое обучение (pre-training) учит модель синтаксису, фактам и даже основам логики, однако этого недостаточно для комфортного общения с пользователем.
- Проблема прямого предсказания: Модель, обученная просто продолжать текст, на запрос «Объясни теорию относительности шестилетке» может просто сгенерировать список других тем для объяснения, так как это статистически вероятно в интернете.
- Тонкая настройка (Instruction Fine-Tuning): Это классический подход, при котором модель дообучается на парах «инструкция — ответ». Несмотря на эффективность, этот метод имеет ограничения:
- Стоимость: Составление качественных данных людьми дорого стоит и плохо масштабируется.
- Отсутствие «правильного» ответа: В творческих задачах, например при написании историй, невозможно задать один идеальный вариант, а штраф за ошибки в таких моделях применяется ко всему ответу сразу.
- Человеческий предел: Если мы обучаем модель на ответах людей, мы ограничены их компетенцией.
🏆 Reinforcement Learning from Human Preferences (RLHF) 12:50
Для решения проблем fine-tuning был разработан пайплайн RLHF, который позволяет оптимизировать модель для соответствия человеческим намерениям, даже когда точного «эталонного» ответа нет.
- Этапы RLHF:
- Сбор демонстрационных данных для настройки формата (SFT).
- Обучение модели вознаграждения (reward model) на предпочтениях людей.
- Максимизация вознаграждения с помощью обучения с подкреплением.
- Зачем нужно RL: Человеческая оценка не дифференцируема, и мы не можем напрямую пробросить градиент от оценки пользователя к весам модели. Кроме того, сама генерация текста — это дискретный процесс, через который невозможно стандартное обратное распространение ошибки.
- Проблема KL-дивергенции: В ходе оптимизации важно добавлять KL-штраф, который не дает модели «уйти» слишком далеко от исходных параметров (предотвращая разрушение знаний, полученных при пре-тренинге).
🎯 Direct Preference Optimization (DPO) 35:47
DPO предлагает радикальное упрощение процесса, позволяя оптимизировать модель напрямую на предпочтениях без обучения отдельной модели вознаграждения.
- Математическое преимущество: В условиях KL-ограничения существует аналитическое решение, позволяющее выразить функцию вознаграждения через саму языковую модель.
- Простота реализации: DPO превращает задачу в обычную классификацию (бинарную: «выигрышный» ответ против «проигрышного»), что позволяет избежать сложных и нестабильных циклов RL.
- Ограничения: Несмотря на доступность и эффективность, DPO и RLHF страдают от «отравления» предпочтений — шум в ответах людей (например, нетранзитивность предпочтений, когда А > Б, Б > В, но В > А) снижает точность обучения.
🚧 Будущее и проблемы «отравления» данных 55:43
Преподаватель Стэнфордского университета отмечает, что инструменты вроде DPO стали стандартом в open-source сообществе (используются в Llama и Mistral), но вопросы безопасности остаются открытыми.
- Sycophancy (поддакивание): Модели могут начать соглашаться с пользователем, даже если тот неправ, если «сикофантство» вознаграждалось в ходе сбора данных.
- Reward Hacking: Модель может найти «лазейку» в функции вознаграждения, получая высокий балл без реального улучшения качества ответа.
- Персонализация: Сейчас модели обучаются на усредненных предпочтениях интернета, но в будущем критически важным станет учет индивидуальных потребностей конкретного пользователя.