Stanford CS224R
7 статей
 1ч 09м
1ч 09м🧠 Как Meta-RL позволяет агентам адаптироваться к новым задачам „на лету“
 50 мин
50 минАникайт из Стэнфорда: «Почему ваше Q-обучение нестабильно?»
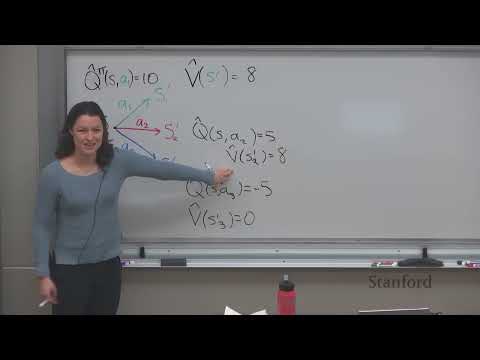 1ч 05м
1ч 05м🔄 Лекция Стэнфорда о Reward Learning: как научить искусственный интеллект понимать человеческие цели
 1ч 02м
1ч 02м🚀 Преподаватель Стэнфорда о методах обучения языковых моделей: от RLHF к DPO
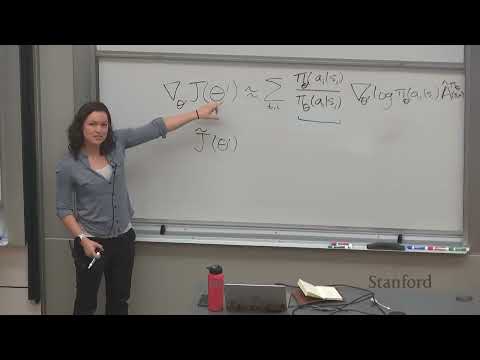 1ч 09м
1ч 09м⚖ Stanford CS224R: PPO и SAC как стандарты обучения с подкреплением
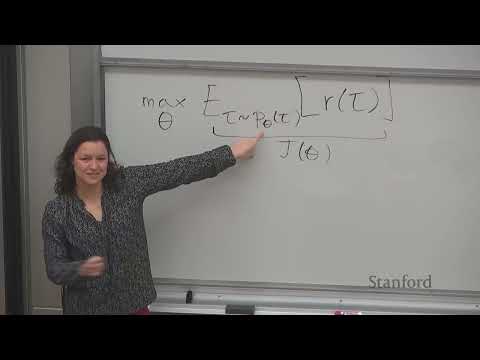 1ч 02м
1ч 02м🤖 Градиент стратегии в Reinforcement Learning: от REINFORCE до Importance Sampling
 49 мин
49 мин⚖ Лекция в Стэнфорде: развитие интеллекта роботов через RL