Авторегрессионные диффузионные модели: новый подход к генерации данных 0:00
В видеоролике автор канала Янник Кильчер (Yannic Kilcher) проводит подробный разбор научной статьи от исследователей Google о новом классе нейронных сетей — Autoregressive Diffusion Models (ARDM). Основная концепция исследования заключается в объединении преимуществ авторегрессионных моделей и диффузионных процессов, что позволяет генерировать данные (например, пиксели изображений) в произвольном порядке, а не только по жестко заданной схеме «слева направо».
Концепция и ключевые особенности модели 1:57
Традиционные авторегрессионные модели, такие как GPT, предсказывают токены последовательно, что накладывает ограничения на процесс генерации. В отличие от них, авторы статьи предлагают архитектуру, которая:
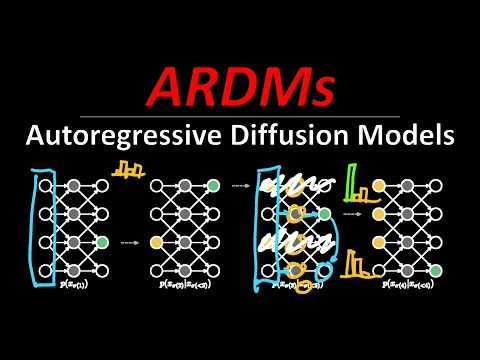
- Поддерживает любой порядок декодирования: Модель может начинать генерацию с наиболее «уверенных» для себя областей, постепенно уточняя детали.
- Обучается как BERT: В процессе обучения модель маскирует часть данных и предсказывает все пропущенные элементы одновременно, что делает архитектуру проще в реализации и обучении,.
- Масштабируемость: ARDM эффективно работают с высокоразмерными данными и позволяют адаптировать процесс генерации под заданный вычислительный бюджет.
По словам Кильчера, одной из сильных сторон модели является возможность гибкого управления скоростью: пользователь может пожертвовать качеством ради более быстрой генерации, регулируя количество шагов.
Механика работы: от маскирования к генерации 6:22
Процесс генерации в ARDM принципиально отличается от подхода GAN (которые создают изображение целиком сразу) или стандартных авторегрессионных моделей.
- Начальное состояние: На вход поступает «пустой» вектор, где все переменные не определены.
- Предсказание распределения: Нейросеть предсказывает распределение вероятностей для всех элементов выборки одновременно.
- Итеративное декодирование: Выбирается один элемент, для которого фиксируется значение (семплируется), после чего процесс повторяется для оставшихся пустых ячеек.
Как отмечает ведущий, даже при параллельном обучении в стиле BERT, процесс декодирования остается авторегрессионным из-за зависимости данных друг от друга: например, цвет одного пикселя напрямую влияет на вероятность цвета соседнего.
Технологические расширения: скорость и детализация 26:12
Авторы статьи предлагают несколько методов для ускорения и улучшения работы ARDM:
- Параллельная генерация: Возможность предсказывать несколько пикселей за один шаг, если они удалены друг от друга, что снижает общее количество итераций.
- Динамическое программирование: Использование специального алгоритма для оптимального выбора количества пикселей, декодируемых на каждом шаге, в рамках выделенного вычислительного бюджета.
- Масштабирование по глубине (Depth Upscaling): Метод, при котором модель сначала делает «грубые» предсказания (например, определяет яркость пикселя по принципу «светлый/темный»), а затем уточняет их в последующих проходах.
Однако Янник Кильчер скептически относится к этому методу, замечая, что введение этапов «грубого» предсказания фактически возвращает нас к жестко фиксированному порядку декодирования, от которого авторы изначально пытались уйти. Кроме того, этот подход лучше работает с непрерывными данными (пиксели), чем с дискретными категориальными переменными (токены текста).
Резюме и перспективы 33:18
На текущем этапе развития ARDM не являются «state-of-the-art» и пока не могут соревноваться с узкоспециализированными моделями, оптимизированными под конкретный порядок генерации,. Тем не менее, Кильчер считает предложенный подход перспективным, особенно в контексте предоставления пользователям контроля над балансом между скоростью вычислений и качеством результата.




