В лекции Стэнфордского университета профессор Стивен Бойд подробно разбирает барьерные методы решения задач выпуклой оптимизации с ограничениями-неравенствами. Особое внимание уделяется концепции центрального пути, связи между гладкими аппроксимациями и двойственностью Лагранжа, а также парадоксальной эффективности этих алгоритмов на практике. На примерах из схемотехники и крупномасштабного линейного программирования лектор демонстрирует, как теоретические концепции трансформируются в надежные вычислительные инструменты.
🐛 Ловушка области определения и основы метода Ньютона 0:05
В начале лекции Стивен Бойд возвращается к важной практической проблеме, возникающей при реализации метода Ньютона с недопустимой начальной точкой (infeasible start Newton method). Главная ошибка, которую совершают студенты при написании кода для домашних заданий, связана с некорректным вычислением градиента и гессиана на границах области определения функции. Математически формулы для градиента (вектор, элементы которого выглядят как $1/x$) и гессиана (диагональная матрица с элементами $1/x_i^2$) продолжают вычисляться и выдавать численные значения, даже когда переменные принимают неверные знаки.
Однако для рассматриваемой задачи эти выражения теряют всякий смысл, поскольку целевая функция определена строго для положительных значений $x$. Если в процессе линейного поиска (line search) алгоритм предварительно не проверит, что шаг $x + t \cdot v$ оставляет переменную в положительной полуплоскости, вычисление невязки приведет к катастрофическим ошибкам в расчетах. Подобный сбой чрезвычайно трудно отлаживать, и программа неизбежно завершится аварийно.
Для оптимизации кода Стивен Бойд рекомендует использовать возможности разреженной линейной алгебры. Вместо стандартной библиотеки NumPy для этих целей лучше задействовать функционал SciPy. Такой подход позволит уже к концу учебной недели создать полноценный LP-солвер (сокращение от Linear Programming), способный эффективно справляться с задачами, содержащими до 10 000 переменных. Лектор отмечает, что для перехода на разреженный формат достаточно заменить функции NumPy и применить прямое разложение ККТ-матрицы с помощью LDL-транспонирования ($LDL^T$).
Опросы в аудитории показывают, что часть студентов уже успешно справилась с реализацией алгоритма, тогда как для остальных главной преградой остается именно неумение контролировать область определения функций. Профессор советует не тратить на непрерывную отладку скриптов более трех-четырех часов, если это не превращается в дело личной гордости. В конце концов, ключевая цель курса — не написание кода как таковое, а демистификация внутренних механизмов работы оптимизационных систем. Написание собственного LP-солвера с нуля — это редкое достижение, которым может похвастаться далеко не каждый специалист.
🛡️ Логарифмический барьер как сглаживание ограничений 4:09
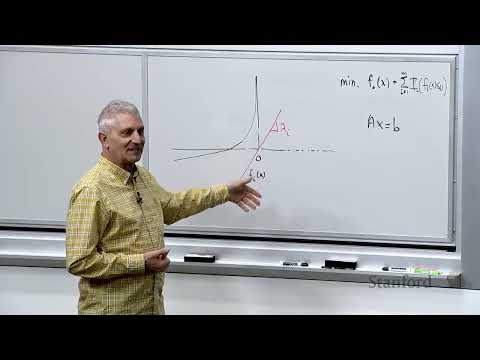
Переходя к основной теме, профессор формулирует задачу оптимизации, где все вовлеченные функции предполагаются гладкими. Если из системы убрать ограничения-неравенства, то решение сводится к классическому методу Ньютона и его вариациям. Но при наличии неравенств возникает фундаментальный вопрос: как расширить метод для их учета? Один из вариантов — перенести ограничения прямо в целевую функцию с использованием индикаторной функции $I$, которая возвращает нуль для допустимых отрицательных значений $f_i(x)$ и плюс бесконечность в противном случае.
Попытка применить метод Ньютона напрямую к такой индикаторной функции обречена на полный провал. Стивен Бойд иронизирует над гипотетическим «уличным» подходом инженеров, готовых проигнорировать отсутствие гладкости фразой «это волнует только математиков». В данном случае отсутствие непрерывности производных — это реальная вычислительная преграда, которая заблокирует работу алгоритма при малейшем выходе в недопустимую область.
В качестве метафоры лектор предлагает представить «уличного бойца», который решает проблему негладкости с помощью наждачной бумаги, просто зашлифовывая острый угол графика функции. Этот интуитивный подход материализуется в виде создания полностью гладкой аппроксимации. Идея жизнеспособна, однако стандартный метод Ньютона на такой поверхности потребует «сто газиллионов» итераций для сходимости из-за огромного значения третьей производной, поскольку функция будет крайне далека от квадратичной формы.
Счастливым решением этой проблемы становится использование специальной гладкой аппроксимации, получившей название «логарифмический барьер» (logarithmic barrier). Вместо жесткого индикатора используется функция вида:
$$- \frac{1}{t} \log(-f_i(x))$$
Графики этих функций проходят через ноль в точке $-1$, принимают небольшие отрицательные значения, а при приближении к границе допустимой области устремляются к плюс бесконечности. Такой сглаженный вариант идеально подходит для обработки методом Ньютона.
В этой формуле параметр $t$ определяет качество аппроксимации исходной задачи:
- При малых значениях $t$ функция сильно сглажена, но далека от оригинала.
- При росте $t$ до очень больших величин барьерная функция начинает предельно точно повторять форму исходного жесткого индикатора.
Однако здесь возникает классический компромисс: увеличение параметра $t$ гарантирует точность моделирования ограничений, но пропорционально затягивает расчеты, требуя все большего числа шагов Ньютона для сходимости. Лектор сравнивает эту концепцию с двойственностью Лагранжа, где индикатор заменялся линейной функцией с наклоном $\lambda$. Но если прямая линия является довольно грубым приближением, то логарифмический барьер работает безупречно благодаря тому, что он принудительно удерживает точку строго внутри допустимого множества. В качестве альтернативы существуют так называемые штрафные функции (penalty functions), которые действуют противоположным образом, формируя внешнюю границу вместо внутренней.
🎯 Центральный путь и сопряжённая двойственность 13:36
Математически логарифмический барьер $\phi(x)$ представляет собой сумму отрицательных логарифмов от запасов по ограничениям (margins) $-f_i(x)$ и является строго выпуклым. Его градиент состоит из масштабированных градиентов функций ограничений, разделенных на величину запаса. Гессиан барьера включает два компонента: гессианы индивидуальных функций, взвешенные по обратным величинам запасов, и сумму векторов ранга 1, обратно пропорциональных квадратам запасов. Для удобства вычислений исходная задача умножается на параметр $t$, что приводит к эквивалентной форме, где $t$ стоит перед исходной целевой функцией $f_0(x)$.
Предполагая, что модифицированная задача имеет решение для каждого положительного значения $t$, мы получаем траекторию оптимальных точек $x^*(t)$. При стремлении $t$ к бесконечности эта траектория сходится к истинному оптимуму исходной задачи. Непрерывная кривая в пространстве $\mathbb{R}^n$, параметризованная коэффициентом $t$, называется центральным путем (central path).
На примере двумерного многогранника Стивен Бойд наглядно описывает геометрию этого процесса:
- При $t \to 0$ минимизация барьера приводит алгоритм в так называемый аналитический центр многогранника (analytic center), где максимизируется произведение запасов по всем ограничениям.
- При увеличении $t$ в систему вводится влияние целевой функции $c^T x$, и точка начинает плавное движение вдоль центрального пути.
- В конечном итоге траектория упирается в оптимальную вершину многогранника, соответствующую направлению вектора стоимости $c$.
Удивительное свойство центрального пути заключается в том, что любая точка на нем автоматически удовлетворяет условиям Каруша — Куна — Таккера (ККТ) для барьерной задачи. Прямая допустимость $Ax = b$ обеспечивается жестким равенством, а градиент целевой функции уравновешивается градиентом барьера и транспонированной матрицей ограничений-равенств. Если разделить это выражение на $t$, становится очевидно, что точка $x^*(t)$ минимизирует функцию Лагранжа для строго определенных двойственных переменных. Двойственные множители $\lambda_i$ оказываются равны $1 / (t \cdot (-f_i(x)))$.
Подстановка этих значений в двойственную функцию дает поразительный результат: разрыв двойственности (duality gap) между текущим значением целевой функции и оптимальным значением $p^*$ составляет ровно $m/t$, где $m$ — количество ограничений-неравенств. Таким образом, решая гладкую задачу методом Ньютона, мы непреднамеренно генерируем допустимые двойственные точки, которые дают четкую верхнюю границу погрешности. Ограничение точности известно заранее и жестко задано величиной $m/t$. При устремлении $t$ к бесконечности зазор схлопывается, гарантируя нахождение точного решения.
Отвечая на вопрос студента о разнице между этим подходом и прямой оптимизацией функции Лагранжа, профессор поясняет, что для многих задач (включая линейное программирование) случайный выбор двойственных переменных возвращает значение минус бесконечность. Цены в экономике и множители в математике должны удовлетворять крайне специфическим условиям сходимости. Барьерный метод уникален тем, что допустимые двойственные переменные генерируются автоматически в процессе минимизации.
В контексте условий ККТ барьерная модификация отличается от исходной задачи лишь в одном компоненте — условии дополняющей нежесткости (complementary slackness). Вместо жесткого требования $\lambda_i f_i(x) = 0$ вводится аппроксимация $\lambda_i f_i(x) = -1/t$. При росте $t$ это выражение стремится к нулю, делая точки центрального пути почти идеальными решениями исходной системы ККТ.
🌌 Механическая интерпретация: силовые поля и избыточные ограничения 24:43
Для упрощения понимания Стивен Бойд предлагает физическую аналогию, основанную на теории силовых полей и классической механике. Переменную $x$ можно представить как обобщенное положение или конфигурацию механической системы. В такой модели целевая функция и барьеры выступают в роли потенциалов, порождающих силовые поля, где сила эквивалентна взятому с отрицательным знаком градиенту потенциала. В точках центрального пути все силы, действующие на систему, идеально сбалансированы, а их векторная сумма равна нулю.
В задаче линейного программирования целевая функция формирует постоянное силовое поле $-t \cdot c$, аналогичное гравитационному, которое непрерывно тянет точку в направлении оптимума. В свою очередь, каждое ограничение-неравенство генерирует отталкивающую силу (repulsive force), направленную строго внутрь допустимого многогранника. Величина этой силы обратно пропорциональна расстоянию (зазору) до соответствующей границы: вблизи стенки отталкивание становится бесконечно мощным, а вдали от нее — едва заметным. При фиксации параметра $t$ система приходит в состояние равновесия, где внешняя «гравитация» уравновешивается суммарным сопротивлением «стен» многогранника. Увеличение $t$ эквивалентно усилению гравитационного поля, что заставляет точку смещаться к новому положению равновесия, ближе к оптимальной вершине.
Профессор задает аудитории провокационный вопрос: изменится ли центральный путь, если в систему добавить избыточное (redundant) ограничение, которое геометрически находится в стороне и никак не меняет допустимую область? Один из студентов предполагает, что путь останется прежним, поскольку ограничение является избыточным. Стивен Бойд хвалит ответ за лаконичность, но тут же добавляет, что этот аргумент имеет один критический недостаток — он в корне неверен.
Каждое новое ограничение, даже избыточное, неизбежно генерирует собственное силовое поле. Если разместить десяток фиктивных ограничений у одной из стен многогранника, они начнут суммарно отталкивать точку, из-за чего траектория центрального пути заметно выгнется в противоположную сторону. Тем не менее, итоговая точка схождения при $t \to \infty$ останется неизменной — алгоритм все равно проскользнет к истинному оптимальному решению. Физическая модель полезна для интуитивного понимания процессов, хотя детально описать динамику этих сил в многомерных пространствах математики пока не могут.
⏳ Исторический экскурс: от советских открытий до обложки The New York Times 31:17
Барьерные методы имеют богатую и драматичную историю. Значительная часть теоретической базы была заложена еще в 1960-х годах под названиями вроде «метод последовательной безусловной минимизации» (SUMT — Sequential Unconstrained Minimization Technique). Позже выяснилось, что советский математик И. И. Дикин еще в 1967 году разработал абсолютно современный по своей структуре алгоритм. Однако, по воспоминаниям московских коллег Бойда, в СССР его работа была практически проигнорирована академическим сообществом, а на Западе оставалась совершенно неизвестной. В итоге идеи, которые спустя два десятилетия попали на первые полосы ведущих мировых газет, годами пылились в статьях регионального вестника.
В США схожими разработками занимались Фиакко и Маккормик (Fiacco, McCormick). Суть их концепции последовательной оптимизации заключалась в пошаговом приближении к ответу. Если нам известна требуемая точность решения задачи (например, $10^{-5}$), мы можем рассчитать необходимую величину параметра $t$ на основе количества ограничений $m$. Алгоритм возвращает не просто абстрактную точку, а подкрепленный математическими вычислениями сертификат точности.
Для простых прикладных задач этот метод прямой безусловной минимизации (UMT) работает превосходно. Проблема кроется в универсальности: если попытаться с ходу заложить высокое значение точности в сложной LP-задаче, метод Ньютона потребует тысяч итераций и, скорее всего, разрушится из-за накопления численных погрешностей округления. На практике использовать бесконечную точность вычислений невозможно.
🗺️ Метод гомотопии и его применение в схемотехнике 34:51
Для обхода численных проблем применяется более широкий класс подходов из прикладной математики — методы гомотопии (homotopy methods). Их фундаментальная идея элегантна: решение сложной системы нелинейных уравнений начинается с введения вспомогательного параметра (например, $\theta$ или $t$), который искусственно сглаживает или упрощает задачу. Классический диапазон изменения этого параметра составляет от 0 до 1. При $t = 0$ система вырождается в тривиальную задачу, ответ для которой очевиден, а при $t = 1$ превращается в исходную сложную систему, которую требуется решить. Процесс вычислений представляет собой пошаговое движение (марш) вдоль этой траектории, где каждое последующее вычисление метода Ньютона стартует из точки, найденной на предыдущем шаге.
Лектор приводит в пример классический симулятор электронных схем SPICE, где гомотопия используется для поиска точек равновесия постоянного тока (DC bias point) в цепях с миллиардами нелинейных уравнений, описывающих поведение транзисторов. Физическим гомотопическим параметром здесь выступает напряжение питания (supply voltage). Если полностью обесточить схему (установить напряжение в 0), то финальный ответ тривиален: все токи и потенциалы в цепи равны нулю. Затем инженеры начинают плавно «выкручивать ручку» напряжения питания, например, поднимая его до 50 милливольт. При таком низком напряжении транзисторы еще не включаются и ведут себя как обычные линейные резисторы, что позволяет найти решение всего за один-два шага Ньютона. Шаг за шагом наращивая напряжение (100 милливольт, затем 200 и так далее), симулятор доходит до номинальных 2 вольт, успешно вычисляя рабочую точку сложнейшей микросхемы.
Главное отличие барьерного метода от общих методов гомотопии заключается в топологической простоте траектории. В стандартных математических задачах гомотопический путь может разветвляться (бифуркация) или внезапно обрываться, требуя сложной логики отката по шагам (например, уменьшения шага с 0.1 до 0.075 при сбое сходимости). В выпуклой оптимизации барьерный путь всегда линеен, единственен и гарантированно ведет к цели, а единственным варьируемым параметром остается объем вычислительных усилий.
🚀 Алгоритм барьерного метода и загадка сложности $O(1)$ 41:49
Базовый барьерный алгоритм выглядит просто: на каждом этапе запускается центрирование методом Ньютона для текущего значения $t$, после чего проверяется условие останова $m/t < \epsilon$. Если точность не достигнута, параметр $t$ умножается на коэффициент $\mu$ (где $\mu > 1$), и цикл повторяется. Коэффициент $\mu$ фактически определяет степень агрессивности сокращения целевого зазора на следующем шаге. Если выбрать минимальный шаг (например, $\mu = 1.05$), траектория сместится незначительно, и для перецентрирования потребуется всего пара итераций Ньютона — такой подход называется методом короткого шага (short-step methods).
Теоретики обычно настаивают на микроскопических шагах порядка $\mu = 1 + 1/\sqrt{m}$, однако инженерная практика диктует совершенно иные правила: разработчики выбирают огромные значения $\mu$ в диапазоне от 10 до 100 и даже больше. Прелесть выпуклой структуры в том, что алгоритм теоретически защищен от критических сбоев. Даже при экстремальном обновлении параметров метод Ньютона гарантированно сойдется к оптимуму, пусть и за большее число внутренних шагов.
График сходимости зазора двойственности имеет характерный вид ступенчатой лестницы (staircase plot) на полулогарифмической шкале:
- Ширина каждой проступи (горизонтальной части ступени) отражает количество шагов Ньютона, затраченных на процедуру центрирования.
- Высота падения фиксирована и в точности равна величине коэффициента $\mu$.
При агрессивном значении $\mu = 50$ зазор за один шаг падает в пятьдесят раз, требуя около 11 итераций на центрирование. При плавном $\mu = 2$ проступи становятся намного уже (по 2–3 шага Ньютона), поскольку новые задачи почти не отличаются от предыдущих, но общее число ступеней возрастает.
Эксперименты показывают удивительный феномен: при изменении $\mu$ от 2 до 150 общее число шагов Ньютона, необходимых для снижения погрешности в $10^8$ раз, остается практически неизменным и колеблется в районе 30–40 итераций. Происходит взаимная компенсация эффектов: малый шаг дает быструю сходимость на этапе, но требует много этапов; большой шаг требует много усилий внутри этапа, но кардинально сокращает их общее число. Это избавляет инженеров от изнурительной ручной настройки параметров: алгоритм работает одинаково стабильно в широком диапазоне значений.
Парадоксально и то, что для задачи со 50 переменными и 100 ограничениями количество вершин в многограннике астрономическое, но барьерный метод находит точный ответ всего за 35 остановок на «запрос направления» через ККТ-матрицу. Что еще более поразительно — эти графики и объемы вычислений абсолютно не меняются при росте размерности пространства до 5 000 или 10 000 переменных. В реальных вычислениях эмпирическая сложность барьерных методов оценивается как $O(1)$ — они всегда требуют от 20 до 50 шагов Ньютона независимо от масштаба задачи.
Стивен Бойд делится историей своего коллеги из Эдинбурга, который решал на суперкомпьютере колоссальную задачу линейного программирования с 2 миллиардами переменных и 500 миллионами ограничений. На вопрос о количестве итераций коллега буднично ответил: «Все как обычно, 22–23 шага». Правда, сама итерация из-за объемов данных длилась по 25 минут. Бойд в шутку добавляет, что в момент запуска расчетов в Эдинбурге, скорее всего, тускнел свет, но сразу оговаривается, что эта часть истории — вымысел.
Данный феномен означает, что вся современная оптимизация полностью свелась к вычислительной линейной алгебре. Качественный прорыв в скорости работы современных солверов (таких как ECOS в библиотеке CVXPY) обеспечивается не усложнением логики самих алгоритмов, а созданием сверхэффективных методов факторизации матриц.
📐 Фаза I: Поиск допустимой точки и минимизация нарушений 1:06:23
Описанный барьерный метод строго требует наличия начальной точки, лежащей внутри допустимой области. На практике для поиска такой точки применяется двухфазная схема (Phase I / Phase II). Современные промышленные солверы умеют объединять эти фазы, одновременно отслеживая ограничения, недопустимость и неограниченность целевой функции всего в нескольких строках кода. Тем не менее, классический раздельный подход Фазы I критически важен для понимания.
Задача Фазы I формулируется как поиск вектора $x$, удовлетворяющего системе неравенств при заданных линейных равенствах $Ax = b$. Для этого вводится вспомогательная переменная сдвига — слак-переменная $s$ (slack variable). Новая оптимизационная задача ориентирована на минимизацию этого параметра $s$. Начальное значение $s$ выбрать легко: берется любая точка, удовлетворяющая равенствам $Ax = b$, вычисляется максимальное нарушение среди всех неравенств $f_i(x)$, к нему добавляется единица — и система становится допустимой для барьерного старта. Как только в процессе минимизации алгоритм достигает отрицательного значения $s$, расчет немедленно прерывается, поскольку текущая точка гарантированно стала строго допустимой, и система переключается на Фазу II (основной барьерный метод).
Если исходная система в принципе не имеет совместных решений, Фаза I завершится на оптимальном значении, например, $s^* = 1.3$. Это дает ценнейшую инженерную интерпретацию: спецификации несовместны, но если ослабить каждое ограничение ровно на 1.3 единицы, задача обретет решение. При этом на уровне геометрии несколько жестких ограничений одновременно упрутся в этот барьер 1.3, формируя зону максимального противодействия («система заклинивает»).
Альтернативой минимизации максимума является метод суммы нарушений (sum of infeasibilities). Математически этот подход минимизирует сумму положительных частей функций ограничений, что эквивалентно использованию нормы $L_1$ для вектора нарушений. Известное свойство нормы $L_1$ — стимулирование разреженности (sparsity) решения. В контексте проектирования систем это означает, что если из 50 заданных инженерных ограничений выполнить все одновременно невозможно, алгоритм автоматически найдет компромиссное решение, которое идеально удовлетворит, например, 47 условий, оставив невыполненными всего три. На диаграммах распределения зазоров это выглядит как четкое разделение: большинство ограничений уходят в глубокую допустимую область, а оставшаяся горстка группируется у барьера нарушений.
На примере деформирующегося многогранника, объем которого схлопывается до нуля при изменении параметра $\gamma$, Бойд показывает, что вычислительная сложность Фазы I также стабильна и составляет порядка 30–40 шагов. Алгоритм резко замедляется лишь в одной узкой зоне — непосредственно на тонкой границе между допустимостью и недопустимостью системы, где построение разделяющих сертификатов требует предельной точности.
🔬 Самосогласованность и теоретические границы сложности 1:16:25
В финальной части лекции Бойд кратко затрагивает математическую теорию самосогласованных функций (self-concordant functions), разработанную Нестеровым и Немировским. Для строгого анализа сходимости требуется, чтобы комбинированная функция вида $t \cdot f_0(x) + \phi(x)$ обладала свойством самосогласованности. Некоторые естественные задачи, такие как максимизация энтропии с линейными неравенствами, изначально этим свойством не обладают. Однако добавление избыточного ограничения $x \ge 0$ и соответствующего логарифмического барьера $-\sum \log x_i$ мгновенно делает задачу самосогласованной.
Профессор с юмором замечает, что практическое значение этой сложной теории долгое время оставалось туманным. На практике разработчики часто жертвуют самосогласованностью ради кратного ускорения вычислений, не опасаясь «полиции алгоритмической сложности», которая якобы должна прийти с ордером на их арест. Тем не менее, теория дает четкие и строгие верхние границы числа шагов Ньютона, необходимых для перецентрирования на каждом шаге гомотопии.
Общее число итераций Ньютона зависит от разности значений функций между начальной точкой $x_0$ и оптимумом $x^*$, деленной на теоретический параметр сходимости $\gamma$, плюс небольшая константа. Проблема классического анализа заключалась в том, что для оценки количества шагов нужно было заранее знать разность значений функций, то есть фактически сначала решить задачу. Этот парадокс разрешается с помощью сопряженной двойственности Лагранжа, которая позволяет аналитически оценить строгую нижнюю границу оптимума еще до начала финальных вычислений. Эту тему лектор обещает подробно развить на следующем занятии.




