В рамках курса EE364A в Стэнфордском университете профессор Стивен Бойд детально разбирает практические аспекты реализации метода Ньютона для задач выпуклой оптимизации. Особое внимание уделяется переходу от абстрактных теоретических оценок сходимости к реальному ускорению вычислений за счет глубокого понимания структуры матриц и линейной алгебры. Лектор демонстрирует, как правильный учет разреженности, ленточной структуры и низкоранговых модификаций гессиана позволяет решать сложнейшие прикладные задачи прямо на мобильном телефоне.
🎯 Теория самосогласованности: преодоление классических ограничений 0:05
Концепция самосогласованности (self-concordance) призвана решить давнюю проблему классического анализа сходимости метода Ньютона. Лектор отмечает, что традиционные математические подходы долгое время оставались менее совершенными, чем реальные алгоритмы вычислений и их программные реализации.
Анализ сходимости напрямую зависит от величины третьей производной функции, поскольку при ее равенстве нулю метод Ньютона сходится ровно за один шаг. По сути, третья производная отражает скорость изменения гессиана при перемещении по области определения.
В классическом анализе для одномерного случая в качестве меры используется абсолютное значение третьей производной $|f'''(x)|$. Профессор Стивен Бойд иронизирует, что такое определение — первое, что придет в голову обычному человеку на улице, однако у него есть критический недостаток: оно зависит от аффинных преобразований координат.
Для устранения этой зависимости математики пришли к сравнению абсолютного значения третьей производной с величиной второй производной в степени $3/2$. Функции, удовлетворяющие этому условию, называются самосогласованными; хотя этому свойству соответствуют не все выпуклые функции, его разделяет огромное количество практически важных моделей.
Стивен Бойд признается, что не может высмеять анализ сходимости на основе самосогласованности, хотя обычно теоретические выкладки содержат длинный список невыполнимых условий и заканчиваются слабыми выводами. В гипотезе самосогласованности нет неизвестных параметров, что делает ее исключительно элегантной.
Важной метрикой здесь выступает ньютоновский декремент $\lambda$, рассчитываемый через градиент и обратный гессиан, который полностью независим от изменений координат. Стивен Бойд предупреждает разработчиков: если в коде для проверки сходимости используется обычная норма градиента, алгоритм автоматически становится зависимым от масштабирования координат.
При соблюдении условий гарантируется стабильное уменьшение целевой функции на каждом шаге до достижения критического значения $\eta$, после чего начинается стремительная квадратичная сходимость. Оценка сложности метода избавляется от неопределенных констант, а использование нижних границ для оптимума $p^*$ позволяет получить четкую верхнюю границу числа шагов.
Стивен Бойд вспоминает, что их собственный «небрежный» анализ с коллегами давал оценку в 375 шагов, умноженных на разность значений функций. В то же время математики Юрий Нестеров и Аркадий Немировский в своей фундаментальной работе смогли доказать гораздо более жесткую и точную границу, равную примерно 11. В реальной практике этот коэффициент, по оценкам лектора, еще меньше и близок к 2.
Теория самосогласованности чаще всего применяется для доказательства сходимости методов внутренних точек, которые составляют основу современных оптимизационных пакетов. Тем не менее Стивен Бойд подчеркивает прагматичный подход: если функция не является самосогласованной, но алгоритм отлично проходит тесты, ни один практик не станет об этом беспокоиться.
🛠 От матана к линейной алгебре: структура гессиана 7:14
Реализация алгоритмов минимизации гладких функций неизбежно упирается в расчет гессиана, градиента и последующее решение систем линейных уравнений. Любая задача минимизации гладкой выпуклой функции сводится к последовательности из нескольких десятков квадратичных оптимизаций, то есть к чистой линейной алгебре.
Это позволяет напрямую переносить в алгоритмы оптимизации все известные структуры матриц:
- Разреженные матрицы (sparse): содержат подавляющее большинство нулевых элементов, что экономит память.
- Ленточные структуры (banded): ненулевые элементы сгруппированы около главной диагонали.
- Блочные матрицы: упрощают декомпозицию больших систем на независимые подзадачи.
Худшая ошибка, которую может совершить разработчик, — сформировать гессиан в виде плотной матрицы, проигнорировав обилие нулевых элементов. Если структура не заложена в код явно, стандартные численные методы не смогут использовать ее преимущества автоматически.
Профессор Стэнфордского университета рекомендует выработать привычку замечать структуру матриц во всех прикладных задачах. Распространенный сценарий — сепарабельная функция (сумма функций от отдельных переменных), дополненная аффинной функцией. Гессиан сепарабельной части всегда строго диагонален, так как все перекрестные производные равны нулю.
При добавлении ограничений структура итогового гессиана принимает вид «диагональ плюс матрица низкого ранга» ($A^T H_0 A$). Наивная реализация вычисления шага через факторизацию Холецкого для матрицы $n \times n$ потребует $O(n^3)$ флопсов.
Однако знание структуры позволяет провести факторизацию Холецкого гораздо эффективнее через введение вспомогательной переменной $w$ и использование дополнения Шура. Доминирующим фактором по вычислениям становится формирование матрицы, требующее всего $2p^2n$ операций. Если параметр $p$ составляет, к примеру, 1/100 от размерности $n$, экономия вычислительных ресурсов достигает внушительных 10 000 раз.
Ленточный гессиан означает, что ненулевые перекрестные производные существуют только для близких переменных, то есть взаимодействия носят локальный характер. Такие структуры тотально доминируют в задачах автоматического управления и обработки сигналов. Шаг Ньютона для ленточной матрицы рассчитывается за линейное время $O(n)$.
Стивен Бойд приводит пример: если решать задачу оптимального управления на пару тысяч шагов с размерностью состояния 10 и 5 входами, наивный код будет думать секунду или две. При правильном подходе и учете ленточной структуры время расчета падает до субмиллисекунд, что критически важно для систем реального времени.
⚖ Минимизация с ограничениями типа равенства 14:45
Переходя к задачам с ограничениями вида $Ax = b$, лектор напоминает условия оптимальности Каруша — Куна — Таккера (ККТ). Для выпуклой функции они являются необходимыми и достаточными без каких-либо дополнительных оговорок: градиент должен лежать в области значений транспонированной матрицы ограничений, а точка должна быть допустимой.
В случае квадратичной целевой функции градиент становится аффинной функцией, и условия ККТ превращаются в систему линейных уравнений. Матрица этой системы, называемая матрицей ККТ, является фундаментальным объектом, возникающим в механике, электротехнике и множестве других областей.
Матрица ККТ обратима тогда и только тогда, когда нуль-пространство матрицы ограничений $A$ не пересекается с нуль-пространством матрицы квадратичной формы $P$. При этом она не является положительно определенной — математики относят её к квази-знакоопределенным матрицам. Для ее эффективного решения применяется $LDL^T$-факторизация, аналогичная методу Холецкого, но учитывающая знаки.
Один из способов избавления от ограничений-равенств — полная параметризация допустимого множества через свободные переменные $z$ с помощью матрицы $F$, чья область значений совпадает с нуль-пространством $A$. Это превращает задачу в безусловную, которая легко решается стандартным методом Ньютона.
Классическим примером такой задачи выступает распределение ресурсов (resource allocation) между $n$ агентами при фиксированном общем бюджете $b$. Исключение одного уравнения позволяет выразить последнюю переменную через остальные.
Стивен Бойд предлагает аудитории визуализировать гессиан полученной сокращенной задачи. Исходная часть дает диагональную матрицу, а ограничение добавляет к ней матрицу единиц ранга 1. В итоге получается плотная матрица, но благодаря структуре «диагональ плюс ранг 1» задача решается за линейное время.
Лектор подчеркивает, что оптимизацию с миллионом переменных в такой постановке можно выполнить прямо на экране смартфона. К сожалению, по наблюдениям Бойда, ежедневно разработчики совершают ошибки, пытаясь использовать стандартные библиотеки вроде NumPy «в лоб», после чего жалуются на низкую скорость вычислений. Матрица $F$ в данном случае имеет структуру, где единичная матрица расположена над вектором из минус единиц, что и обеспечивает столь изящное математическое сокращение.
🚀 Метод Ньютона: допустимый и недопустимый запуск 24:11
Альтернативный путь — вычисление шага Ньютона напрямую из исходной системы ККТ без предварительного исключения ограничений. Геометрически это эквивалентно минимизации квадратичной аппроксимации функции Тейлора второго порядка при сохранении строгих равенств. Другая интерпретация заключается в линеаризации условий оптимальности первого порядка.
Концепция ньютоновского декремента сохраняется и здесь: величина $\frac{1}{2}\lambda^2$ в точности прогнозирует падение значения функции на текущем шаге, если бы она была строго квадратичной. Это дает отличный практический индикатор того, насколько близко алгоритм подобрался к оптимуму.
При допустимом методе Ньютона (feasible start) вычисления начинаются строго из точки, удовлетворяющей равенству $Ax = b$. Алгоритм пошагово уменьшает целевое значение, оставаясь в допустимой области и сохраняя полную аффинную инвариантность. С математической точки зрения траектории допустимого метода Ньютона и метода с предварительным исключением переменных абсолютно идентичны.
Выбор между этими подходами часто сводится к размерности: например, при 1000 переменных и 100 ограничениях метод исключения оперирует системой из 900 переменных, а ККТ-система раздувается до 1100 переменных. Интуитивно кажется, что решать меньшую систему выгоднее, ведь куб от 1100 больше куба от 900. Однако Стивен Бойд заявляет: при наличии внутренней структуры в матрицах решать большую систему ККТ практически всегда эффективнее, что опровергает стандартную интуицию.
Для ситуаций, когда найти начальную допустимую точку трудно, применяется метод Ньютона с недопустимым запуском (infeasible start Newton method). Алгоритм линеаризует невязку ограничений и оперирует прямо-двойственной переменной $z$, объединяющей исходные переменные $x$ и двойственные множители $\nu$. Именно этот подход скрыт под капотом большинства промышленных солверов, таких как ECOS.
При недопустимом запуске первый же шаг с полной длиной $t=1$ делает точку допустимой, и далее алгоритм превращается в классический метод Ньютона. Однако на практике сделать шаг полной длины часто невозможно, так как он может выбросить переменную за пределы области определения функции $f$.
Лектор дает критически важный совет для выполнения домашних заданий: при оптимизации функций с барьерами (например, $-\log x$) начальной точкой можно выбрать вектор из единиц. В процессе линейного поиска (backtracking) нельзя вычислять градиент и гессиан для точек, вышедших из области определения (ставших отрицательными). Обычные математические библиотеки могут вернуть числовое значение для формул $1/x$ или $1/x^2$ даже при отрицательном $x$, но это полностью разрушит сходимость алгоритма. Правильный подход — последовательно уменьшать шаг $t$ на множитель $\beta$ до тех пор, пока точка не вернется в область определения, и лишь затем переходить к оценке невязки.
График нормы невязки имеет строго определенный наклон, равный -1 при $t=0$. Это позволяет использовать стандартное условие Армихо для контроля сходимости. Стивен Бойд называет написание подобного солвера важнейшим жизненным опытом, который должен пережить каждый разработчик, чтобы перестать легкомысленно относиться к областям определения функций.
📊 Три метода — одна сложность: мифы о двойственности 41:59
В арсенале инженера теперь есть три основных инструмента:
- Прямой метод Ньютона с ограничениями-равенствами.
- Решение двойственной задачи оптимизации.
- Метод Ньютона с недопустимым запуском (infeasible start).
Лектор разбирает пример с 500 переменными и 100 ограничениями, чтобы развеять популярные мифы. Сторонники двойственного подхода часто утверждают, что решать двойственную задачу выгоднее, ведь она сокращает число переменных с 500 до 100, что якобы обещает ускорение в $5^3 = 125$ раз. В экономике такие методы любят называть системами «поиска цен» (price discovery), поскольку двойственные переменные отражают маргинальную полезность ресурсов. Более того, на слайдах презентаций часто показывают, что двойственный метод сошелся за 9 итераций против 14 у классического метода Ньютона.
Стивен Бойд категорично заявляет: все эти рассуждения в корне неверны и глупы, если мы используем грамотную линейную алгебру. При детальном анализе оказывается, что пошаговая сложность всех трех алгоритмов абсолютно идентична.
При использовании блочного исключения в методе Ньютона мы приходим к необходимости формирования и решения системы вида $A D A^T \Delta \nu = \text{rhs}$ размера $100 \times 100$, где $D$ — диагональная матрица. Расчет гессиана двойственной функции приводит ровно к такой же структуре. Метод с недопустимым запуском решает ту же систему, меняется лишь правая часть уравнений за счет добавления текущей невязки. Таким образом, переход к двойственной задаче сам по себе не дает никаких вычислительных преимуществ в рамках метода Ньютона, если вы изначально действовали эффективно.
🌐 Оптимизация сетевых потоков и матричные задачи 51:19
Великолепной иллюстрацией силы структурной линейной алгебры служит задача максимизации полезности потоков в графе (flow utility maximization). Переменная $x_i$ задает поток по ребру ориентированного графа, причем отрицательные значения вполне допустимы и просто указывают на движение против базового направления.
Уравнение $Ax = 0$ кодирует закон сохранения потока в узлах, где $A$ выступает матрицей инцидентности графа. Если чистая инжекция в узлах равна нулю, вектор потоков называют циркуляцией. Вектор $b$ задает внешние источники (генераторы) или потребителей (нагрузки) в узлах сети.
Эта модель идеально описывает множество прикладных систем:
- Энергосети: распределение электроэнергии без учета потерь в линиях.
- Банковские системы: движение денежных средств между счетами и организациями.
- Медицина: транспорт лекарственных веществ между различными органами и тканями человека.
Матрица инцидентности $A$ экстремально разрежена: каждый её столбец содержит ровно две ненулевые отметки (+1 и -1), поскольку любое ребро жестко связывает только два узла. Сумма строк матрицы всегда равна нулю, поэтому один узел условно заземляют, удаляя соответствующую строку для достижения полного ранга матрицы. Подобные структуры активно изучаются в биологии при анализе баланса потоков (flux balance) и в линейном программировании.
Для понимания масштаба: энергосистема Калифорнии включает около 3100 генераторов и порядка 6000 линий электропередачи. Это небольшая задача, которую можно решить даже неоптимальным плотным методом. Однако для объединенной энергосистемы западной части США (US Western grid) размерность возрастает до сотен тысяч элементов.
Сепарабельность целевой функции гарантирует строго диагональный гессиан. Блочное исключение в системе ККТ приводит нас к вычислению матрицы Лапласа ($A D A^T$), которая в электротехнике называется матрицей проводимости.
Стивен Бойд критикует представителей теоретической компьютерной науки (TCS), создавших вокруг решения уравнений Лапласа целую индустрию публикаций, называя их методы в подавляющем большинстве абсолютно бесполезными для реальной инженерной практики. В матрице Лапласа элемент на пересечении строки $i$ и столбца $j$ отличен от нуля только тогда, когда узлы связаны дугой в графе.
Если в сети из миллиона узлов и 10 миллионов ребер степень связности каждого узла колеблется от 2 до 50, то и количество ненулевых элементов в строке будет строго ограничено этим диапазоном. Это позволяет применять сверхэффективные разреженные солверы и разворачивать полноценный метод Ньютона для колоссальных сетевых задач.
Аналогичный прорыв в производительности происходит при оптимизации матричных переменных (например, в задачах полуопределенного программирования, SDP). Если развернуть симметричную матрицу $X$ размера $n \times n$ в вектор, мы получим порядка $n^2/2$ переменных, а гессиан превратится в монстра размером $n^4$ элементов, требуя $O(n^6)$ операций на один шаг. Для $n=200$ это станет непреодолимым препятствием.
Однако прямое линеаризованное представление производной обратной матрицы ($\Delta(X^{-1}) = -X^{-1} \Delta X X^{-1}$) позволяет выполнить блочное исключение вручную. Это снижает итоговую вычислительную сложность до величин порядка $pn^3$ или $p^2n^2$, совершая концептуальный переход от шестой степени к квадрату или кубу размерности. Именно этот математический трюк незаметно для пользователя отрабатывает каждый раз при запуске современных SDP-солверов.
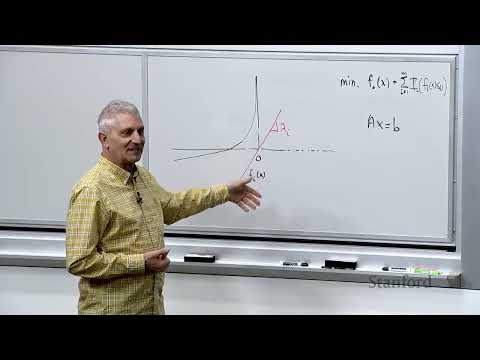
🚧 Переход к неравенствам: логарифмический барьер 1:10:57
В общей иерархии методов оптимизации мы прошли путь от базовой линейной алгебры (минимизация квадратичных функций с равенствами) к минимизации общих гладких функций с ограничениями-равенствами. Финальный шаг в этой структуре — добавление ограничений-неравенств вида $f_i(x) \le 0$. Задача состоит в том, чтобы свести их к последовательности уже освоенных нами задач с равенствами.
С математической точки зрения жесткое ограничение-неравенство можно представить как функцию штрафа, которая равна нулю в допустимой зоне и мгновенно уходит в плюс бесконечность при нарушении границы. Такая индикаторная функция разрывна и не имеет производных, поэтому применить к ней метод Ньютона напрямую невозможно.
Идея лагранжевой двойственности предлагает линейную аппроксимацию этого барьера, что на первый взгляд кажется крайне грубым приближением. Однако для выпуклых задач при правильном подборе наклона (цен) эта аппроксимация работает идеально.
В барьерных методах исследователи пошли по более интуитивному пути, создавая гладкую аппроксимацию, которая плавно устремляется к бесконечности при приближении к границе допустимой зоны. Логарифмический барьер идеально подходит под эти критерии, открывая дорогу к методам внутренних точек, подробный разбор которых лектор намечает на следующую встречу.