В новом выпуске подкаста The Cognitive Revolution ведущий Нейтан Лабенц обсуждает мультимодальную революцию в области искусственного интеллекта с исследователями из Salesforce Research Singapore. Цзюньнань Ли и Дунсюй Ли, соавторы прорывных моделей BLIP и BLIP2, рассказывают о том, как им удалось создать системы, удерживающие лидерство в распознавании изображений на протяжении года, и почему будущее AI за «замороженными» моделями и специализированными коннекторами.
🌉 От зрения к языку: конвергенция областей AI 4:35
До недавнего времени компьютерное зрение и обработка естественного языка (NLP) считались отдельными дисциплинами с разным набором инструментов. Однако, по мнению Цзюньнаня Ли, границы между этими областями стремительно стираются . Переход к архитектуре трансформеров (Transformers) позволил исследователям легко перемещаться между доменами, применяя одни и те же методы для работы с текстом и изображениями.
Цзюньнань Ли отмечает:
- Исследователи начали свой путь как специалисты по компьютерному зрению во время PhD, но со временем расширили экспертизу на языковые модели .
- Феномен «великой конвергенции» заключается в том, что универсальные архитектуры начинают эффективно работать во всех модальностях .
Модель BLIP, выпущенная в начале 2022 года, стала одной из самых цитируемых работ года (18-е место среди всех работ по AI) . Она продемонстрировала лучшие результаты в создании подписей к изображениям (image captioning), визуальных ответах на вопросы (VQA) и сопоставлении изображений и текста.
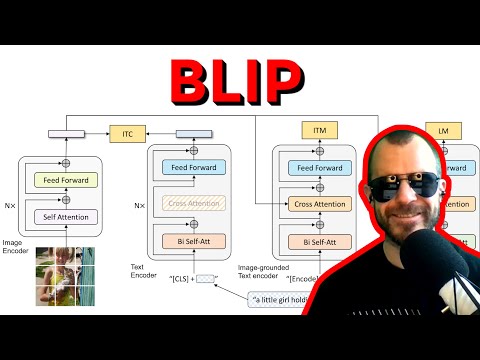
🧬 Архитектура BLIP: как обучали «золотой стандарт» 7:39
Путь к BLIP начался с работы над проектом ALBEF. Цзюньнань Ли поясняет, что их целью было создание мультимодального энкодера, способного понимать и изображение, и текст одновременно . В отличие от модели CLIP от OpenAI, которая использует унимодальные энкодеры и просто вычисляет их сходство, в работах Ли была добавлена «фьюжн-архитектура» (fusion encoder) .
Ключевые механизмы обучения BLIP включают три функции потерь (loss functions) :
- Контрастивное обучение (Contrastive Learning): обучение модели сопоставлять «положительные» пары (соответствующий текст и картинка) и отличать их от «отрицательных» (случайных пар) .
- Генерация подписей (Language Modeling): обучение декодера генерировать текстовые токены на основе визуальных данных .
- Сопоставление текста и изображения (Image-Text Matching): бинарная классификация, где модель через механизм перекрестного внимания (cross-attention) определяет, подходит ли текст к картинке на «микро-уровне» .
Важным новшеством стала фильтрация данных (data bootstrapping). По словам Цзюньнаня Ли, веб-данные крайне зашумлены (например, подпись к фото может быть просто фразой «какой отличный день»), что мешает обучению . Команда разработала фильтр, который удалял шумные подписи и заменял их синтетически сгенерированными качественными описаниями .
🏙️ Работа с логотипами и OCR: почему BLIP точнее конкурентов 20:16
Одной из уникальных особенностей BLIP стала его способность распознавать логотипы и текст на изображениях. Дунсюй Ли объясняет это отказом от использования фиксированных детекторов объектов (object detectors), которые ограничивают модель заранее заданными категориями (например, «кошка» или «машина») .
- Контрастивное обучение позволяет модели сопоставлять конкретные токены из текста с конкретными регионами изображения .
- Модель не имеет специализированного OCR-слоя, но благодаря масштабированию данных на 400 миллионов пар (LAION-400M), она обучается распознавать надписи как часть общего контекста .
- При этом модель может ошибаться в редких названиях компаний, подставляя вместо них похожие из обучающей выборки, так как действует холистически, а не посимвольно .
⚡ BLIP2: революция эффективности и «замороженные» модели 41:44
Выпуск BLIP2 радикально изменил подход к обучению мультимодальных систем. Вместо обучения всей модели целиком (end-to-end), исследователи решили соединить уже существующие и «замороженные» (frozen) модели .
Технические параметры BLIP2:
- Время обучения: менее 10 дней на одной машине с gpus A100 .
- Обучаемые параметры: менее 200 миллионов, несмотря на то что общая архитектура может включать языковые модели на несколько миллиардов параметров .
- Гибкость: можно подключать любую современную языковую модель (например, OPT или Vicuna) без необходимости переучивать визуальную часть .
Цзюньнань Ли сравнивает эту архитектуру с человеческим развитием: представьте человека, который вырос, обладая только знаниями из книг, и в один день открыл глаза . Его задача — научиться интерпретировать визуальные сигналы через призму уже имеющихся знаний.
🧩 Q-Former: мост между пикселями и смыслами 51:15
Сердцем BLIP2 является модуль Q-Former (Querying Transformer). Это компактный коннектор, который извлекает наиболее важные признаки из изображения и преобразует их в эмбеддинги, понятные языковой модели .
Чтобы система заработала, команда применила двухэтапную стратегию обучения :
- Этап 1: Обучение Q-Former понимать визуальную информацию в отрыве от большой языковой модели. На это уходит около 6 дней .
- Этап 2: Обучение коннектора «скармливать» эти знания языковой модели. Этот этап занимает всего около 2 дней .
Без первого этапа модель страдает от «катастрофического забывания» и пытается «читерить», подстраиваясь под статистику языка, а не под реальное содержание картинки . Интересно, что эмбеддинги, которые Q-Former посылает в языковую модель, не интерпретируемы для человека напрямую — это своего рода «темное пространство» внутри векторного поля, которое понимает только AI .
🔮 Будущее: видео, звук и путь к AGI 1:06:44
Исследователи видят в BLIP2 прототип «исполнительной функции» будущего интеллекта. Цзюньнань Ли полагает, что аналогичные коннекторы можно создать для любой модальности:
- Видео: добавление временных меток (timestamp) и позиционного кодирования кадров в тот же энкодер .
- Звук: использование аудио-энкодеров для перевода звуковых волн в понятные языковой модели сигналы .
- Действия: передача выходных данных языковой модели в другие коннекторы, управляющие робототехникой или написанием кода .
Цзюньнань Ли и Дунсюй Ли подчеркивают свою приверженность open-source. Почти 100% их исследований публикуются с открытым кодом и весами моделей . Они считают, что демократизация обучения (когда для создания мощного AI не нужны тысячи GPU) — это единственный способ вовлечь сообщество в развитие безопасных технологий .
🛠️ Ежедневная работа и этика в Salesforce 1:13:18
В повседневной работе ученые сами активно используют инструменты AI. Дунсюй Ли признается, что является «тяжелым пользователем» GitHub Copilot . По его словам, отключение этого плагина заметно снижает качество его жизни как разработчика, особенно при написании шаблонного кода и тестов .
Что касается рисков, в Salesforce Research работает специальная группа по этике (Ethical AI team). Они проверяют все сценарии использования моделей перед их релизом .