Исследователь в области машинного обучения Янник Кильхер (Yannic Kilcher) представил подробный разбор научной работы, посвященной BLIP — новой архитектуре и методу обучения нейросетей от Salesforce Research. Проект предлагает элегантное решение двух главных проблем в области взаимодействия зрения и языка: несовместимости архитектур для понимания и генерации, а также низкого качества данных, собранных из открытого интернета.
🧠 Архитектура MED: Унификация через модульность 3:42
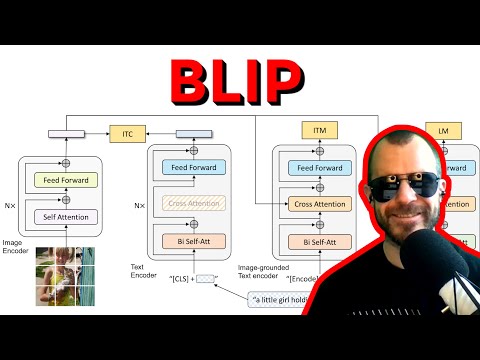
Современные модели компьютерного зрения и обработки естественного языка обычно делятся на два типа: только энкодеры (как CLIP) или энкодер-декодеры. По мнению Янника Кильхера, у обоих подходов есть существенные недостатки . Энкодеры отлично справляются с задачами поиска (retrieval), когда нужно сопоставить картинку с текстом, но их крайне сложно заставить генерировать описания . С другой стороны, архитектуры энкодер-декодер эффективны для создания подписей к изображениям, но плохо работают в задачах поиска и сопоставления .
Для решения этой проблемы Salesforce Research предложили архитектуру MED (Multimodal Mixture of Encoder-Decoder) — «нечестивую смесь» из нескольких модулей, работающих с общими весами :
- Визуальный трансформер (ViT): выступает в роли единого энкодера изображений, преобразуя картинку в набор векторов (эмбеддингов) .
- Унимодальный текстовый энкодер: классический модуль (похожий на BERT), который кодирует текст без учета изображения. Это позволяет модели работать в стиле CLIP .
- Текстовый энкодер с опорой на изображение (Image-grounded Text Encoder): использует механизм cross-attention (перекрестного внимания) для внедрения визуальной информации в процесс кодирования текста. Это создает совместное представление пары «картинка-текст» .
- Текстовый декодер с опорой на изображение: заменяет двунаправленное внимание на каузальное (при котором модель видит только предыдущие слова), что позволяет генерировать текст на основе визуальных данных .
Интересной особенностью архитектуры является совместное использование параметров. Как отмечает Янник Кильхер, текстовые модули делят между собой веса слоев прямого распространения (feed-forward) и слоев cross-attention, что уменьшает размер модели и, согласно результатам тестов, улучшает производительность .
🎯 Три цели обучения для одной модели 18:38
Модель BLIP обучается одновременно на трех задачах, что позволяет ей быть универсальной «из коробки» :
- Image-Text Contrastive Loss (ITC): обучение на контрасте, где модель учится сближать векторы похожих изображений и текстов и отдалять несовпадающие пары.
- Image-Text Matching Loss (ITM): задача бинарной классификации. Модели подается пара «текст-картинка», и она должна ответить, соответствуют ли они друг другу. Для усложнения задачи используется стратегия «hard negative mining» — подбор ложных пар, которые очень похожи на истинные .
- Language Modeling Loss (LM): классическая задача генерации текста, где модель учится предсказывать следующее слово в описании картинки .
🧼 Метод CapFilt: Очистка «шумного» интернета 29:47
Второй прорывной частью работы является метод бутстрапинга данных под названием CapFilt (Captioning and Filtering). Основная претензия авторов к современным датасетам заключается в том, что они собраны из интернета через alt-тексты (описания картинок в HTML). По словам Янника Кильхера, такие подписи часто бесполезны: люди либо не заполняют их, либо используют для поисковой оптимизации (SEO), вставляя ключевые слова, не связанные с содержанием фото .
Процесс CapFilt состоит из нескольких этапов:
- Обучение на чистых данных: Сначала модель обучается на небольшом, но качественном датасете (например, COCO), созданном людьми .
- Создание «Аннотатора» (Captioner): Часть модели (декодер) используется для генерации новых, синтетических подписей к «шумным» картинкам из интернета .
- Создание «Фильтра» (Filter): Другая часть модели (энкодер ITM) оценивает, насколько текст (как оригинальный из интернета, так и синтетический) подходит к изображению .
- Очистка: Если фильтр считает, что описание не соответствует картинке, эта пара удаляется. В итоге получается огромный массив данных, который одновременно масштабен (миллионы картинок из сети) и точен (благодаря фильтрации и переподписыванию) .
Янник Кильхер подчеркивает, что это важный тренд: использование дискриминативных моделей для фильтрации выходов генеративных моделей становится «золотым стандартом» индустрии .
🎲 Нуклеарное сэмплирование против жадного поиска 42:17
В процессе генерации новых описаний для датасета исследователи обнаружили важный нюанс. Традиционный «лучевой поиск» (beam search), который ищет наиболее вероятные слова, выдавал слишком скучные и общие описания . Использование нуклеарного сэмплирования (nucleus sampling), которое вносит элемент случайности, привело к созданию более разнообразных и информативных подписей.
По мнению Кильхера, это доказывает, что для обучения ИИ «неожиданные» и редкие данные в подписях могут быть полезнее, чем максимально безопасные и предсказуемые варианты . Модель обучается лучше, когда получает новые крупицы знаний, а не повторение очевидного.
🚀 Будущее динамических нейросетей 44:41
Завершая обзор, Янник Кильхер выразил надежду на появление фреймворков, которые позволят собирать такие модели автоматически . BLIP продемонстрировал, что модули (энкодеры изображений и текстов) можно не только выбирать, но и пересобирать под конкретные задачи: визуальные ответы на вопросы (VQA), поиск или генерацию .
Хотя Янник скептически относится к заявлениям авторов о том, что BLIP «значительно» превосходит конкурентов (считая это стандартным преувеличением для научных статей), он признает , что архитектура и метод очистки данных являются крайне перспективными рецептами для будущего развития мультимодального ИИ.




