Исследователи из Salesforce Research создали BLIP — унифицированную модель для одновременного понимания и генерации мультимодального контента. В интервью Яннику Килчеру авторы архитектуры Джуннан Ли и Дунсю Ли объяснили, как их подход решает фундаментальную проблему «шумных» данных при обучении нейросетей. Главный вывод разработчиков заключается в том, что очистка и контролируемое улучшение обучающей выборки дают больший эффект, чем простое наращивание её объёмов.
🛠️ Унифицированный подход: что такое BLIP 1:19
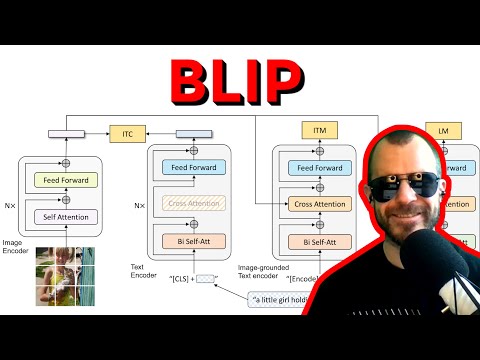
Модель BLIP представляет собой новую парадигму в обучении визуально-языковых моделей. По словам Джуннана Ли, ключевым преимуществом системы является её универсальность: в рамках единого фреймворка она объединяет функции понимания и генерации контента.
Функционал системы разделен на два основных направления:
- Мультимодальное понимание: совместный анализ изображений и текста для формирования общих признаков, используемых в задачах классификации.
- Визуальная генерация: создание текстового описания на основе входного изображения, ярким примером чего служит задача генерации подписей (image captioning).
Обычно для этих задач обучаются отдельные специализированные модели. BLIP доказывает, что объединение этих возможностей в одной сети не только возможно, но и взаимно выгодно для качества репрезентаций.
🧼 Бутстрэпинг данных: качество важнее количества 3:32
Главной технической инновацией BLIP стал алгоритм бутстрэпинга данных (data bootstrapping), направленный на борьбу со скрытым шумом в интернет-датасетах. Традиционно модели обучаются на миллиардах пар «картинка-текст», собранных краулерами из альтернативного текста (alt-text) веб-страниц, однако эти подписи часто оказываются некорректными.
Джуннан Ли определяет «шум» не как грамматические ошибки, а как отсутствие смысловой связи текста с визуальным рядом. Например, подпись к фотографии «мост рядом с моим домом» грамматически верна, но бесполезна для обучения общей модели, так как не описывает фактические объекты.
Для очистки датасетов авторы внедрили двухэтапный процесс:
- Генератор подписей (Captioner): синтезирует новые, потенциально более точные текстовые описания для веб-изображений.
- Фильтр (Filter): оценивает соответствие между исходным (или синтезированным) текстом и картинкой, удаляя нерелевантные пары.
По мнению Джуннана Ли, качество данных играет не менее, а порой и более важную роль, чем их количество. Это подтвердилось при переходе от стандартного датасета Conceptual Captions (3 миллиона изображений) к масштабному набору LAION, где проблема зашумленности проявилась наиболее остро.
🎭 Разнообразие против точности: эффект случайного сэмплирования 8:39
В ходе экспериментов исследователи столкнулись со скрытым противоречием между строгостью фильтрации и разнообразием текстов. Джуннан Ли отметил, что их выводы дополняют популярные теории о пользе некурированных данных: сырые данные дают масштаб, но бутстрэпинг выводит точность на новый уровень.
Особое внимание авторы уделили стратегии декодирования при генерации подписей, сравнив два метода:
- Beam Search (лучевой поиск): детерминированный подход, выбирающий наиболее вероятные слова. Он генерирует безопасные, но скучные фразы вроде «мужчина с собакой в парке», не приносящие модели новых знаний.
- Nucleus Sampling (ядерное сэмплирование): стохастический метод, генерирующий более разнообразные и «человечные» описания.
Эксперименты показали удивительный результат: использование ядерного сэмплирования дало существенный прирост качества downstream-задач по сравнению с лучевым поиском. Несмотря на то, что стохастический метод генерирует больше шума (что подтверждается ростом процента отфильтрованных данных), создаваемое им разнообразие концептов критически важно для глубокого обучения модели.
🏗️ Архитектура модели и синергия функций 16:22
Вопреки первому впечатлению о переусложненности, BLIP не является гигантской системой. Архитектурно она состоит из стандартного Vision Transformer (ViT) и базовой версии BERT. Модель развилась из предыдущей работы авторов — ALBEF (представленной на NeurIPS в прошлом году), которая была исключительно кодировщиком.
Для интеграции генеративных функций авторы добавили декодирующий модуль и внедрили глубокое совместное использование параметров (parameter sharing). Наиболее эффективной стратегией оказалось разделение слоев самовнимания (self-attention) между кодировщиком и декодировщиком, при сохранении раздельных слоев перекрестного внимания (cross-attention).
Обучение BLIP оптимизируется через три базовые функции потерь, каждая из которых решает свою задачу:
- Контрастивная потеря (Image-Text Contrastive) — для глобального сопоставления модальностей.
- Потеря сопоставления (Image-Text Matching) — для отбора жестких негативных примеров и фильтрации.
- Языковое моделирование (Language Modeling) — авторегрессионная потеря для пословной генерации текста.
По словам Джуннана Ли, авторегрессионная потеря заставляет модель анализировать микродетали изображения для предсказания конкретных слов, что кардинально улучшает fine-grained (мелкозернистое) понимание контекста.
📊 Результаты экспериментов: оправдан ли 1% прироста? 31:06
Таблицы результатов в статье демонстрируют стабильное преимущество BLIP перед конкурентами. В Таблице 1 зафиксировано, что совместное использование генератора и фильтра (C + F) дает синергетический эффект на задачах поиска (retrieval) и создания подписей на четырех различных датасетах. При этом средний чистый прирост метрик (например, Recall) составляет около 1–2%.
Ведущий Янник Килчер поднял закономерный вопрос: стоит ли тратить недели дорогостоящего обучения ради 2% улучшения? На этот счет у разработчиков сформировалась четкая позиция. По мнению Дунсю Ли, в коммерческих поисковых системах (например, в сервисах Salesforce) улучшение метрики извлечения даже на 1% конвертируется в огромную финансовую прибыль для бизнеса, полностью окупая затраты на инфраструктуру.
В процессе масштабирования авторы также выявили важные технические нюансы:
- Первоначальная попытка обучить модель на полном наборе LAION не дала ожидаемого прироста.
- Анализ показал, что датасет содержал слишком много мелких изображений (иконок и логотипов брендов), удаление которых вернуло рост показателей.
- В задаче NLVR2 (Таблица 8) увеличение объема данных не привело к линейному росту качества, что указывает на критическую важность точного выравнивания целей предобучения и финальной задачи.
💼 Исследования в Salesforce и свободный формат VQA 40:54
Качественным отличием BLIP от более ранних систем визуального вопрос-ответа (VQA) стала способность к свободному ведению диалога. Дунсю Ли подчеркнул, что старые модели VQA обучались как классификаторы по фиксированному словарю ответов, тогда как BLIP использует полноценную генерацию текста, позволяя пользователю задавать любые вопросы на естественном языке. Оценить это можно в открытом веб-демо.
Рассказывая о внутренней кухне Salesforce Research, авторы отметили высокий уровень академической свободы. Команда компактнее исследовательских подразделений Google или Meta, но обладает гибкостью и ориентирована на создание высокоэффективных решений. Пока модель находится на недельном предобучении, исследователи занимаются анализом литературы, внутренними дискуссиями или решением прикладных продуктовых задач. В финале интервью ученые объявили, что их команда активно расширяется и нанимает интернов со всего мира на удаленную работу.