Алгоритм обратного распространения ошибки (backpropagation) — это фундаментальный механизм обучения нейронных сетей, позволяющий им эффективно настраивать свои внутренние параметры. В данном материале мы разберем интуитивную механику работы этого процесса, который позволяет нейросети «понимать», как именно нужно изменить веса и смещения, чтобы минимизировать ошибку при распознавании образов.
⚙️ Суть алгоритма обратного распространения 0:00
Алгоритм обратного распространения ошибки — это метод вычисления градиента функции стоимости для сложной нейронной сети. Основная задача градиентного спуска заключается в поиске таких значений весов и смещений, которые минимизируют общую ошибку. Поскольку количество параметров в нейросети может достигать десятков тысяч, представлять градиент как направление в многомерном пространстве сложно.
Вместо этого полезно мыслить категориями «чувствительности»:
- Каждый компонент градиента показывает, насколько сильно функция стоимости зависит от изменения конкретного веса или смещения.
- Если градиент для веса равен 3.2, а для другого — 0.1, это означает, что изменение первого веса влияет на стоимость в 32 раза сильнее.
🧠 Интуитивная механика настройки весов 2:47
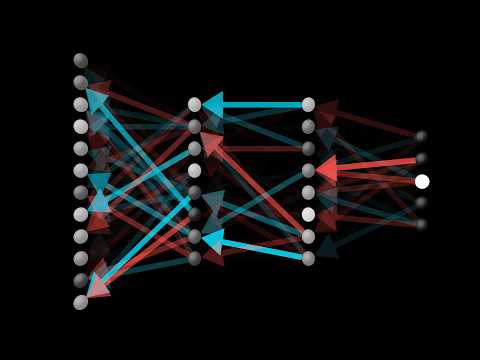
Чтобы понять, как нейросеть обучается на конкретном примере (например, изображении цифры «2»), нужно рассмотреть процесс «пожеланий» каждого нейрона.
Как нейроны «высказывают» свои пожелания
- Выходной слой: Если нейросеть ошибается, мы хотим «подтолкнуть» активацию нужного нейрона (отвечающего за цифру «2») вверх, а активации ошибочных нейронов — вниз. Величина этого «толчка» пропорциональна тому, насколько текущее значение далеко от целевого.
- Влияние на веса: Увеличение активации нейрона достигается тремя способами: изменением смещения (bias), изменением входящих весов или изменением активаций предыдущего слоя.
- Эффективность изменений: Наибольший эффект достигается при изменении тех связей, которые приходят от наиболее активных нейронов предыдущего слоя.
Автор видео отмечает любопытную аналогию с теорией Хебба в нейробиологии: «нейроны, которые разряжаются вместе, связываются вместе». В искусственных сетях это означает, что связи укрепляются между нейронами, которые активно участвуют в правильной классификации примера.
Процесс распространения назад 7:22
После того как выходной слой определил свои «желаемые» изменения, эти пожелания передаются на предыдущие слои:
- Каждый нейрон второго слоя получает список запросов от нейронов выходного слоя.
- Эти запросы суммируются с учетом величины весов, связывающих нейроны.
- Процесс повторяется рекурсивно, двигаясь от последнего слоя к первому.
📉 Стохастический градиентный спуск (SGD) 8:27
Важно помнить, что мы корректируем сеть не по одному примеру, а по среднему значению для всей обучающей выборки. Однако вычисление градиента по десяткам тысяч примеров для каждого шага обучения крайне медленно.
Для ускорения вычислений используется метод мини-пакетов (mini-batch):
- Обучающие данные перемешиваются и делятся на небольшие группы (например, по 100 штук).
- Шаг градиентного спуска вычисляется для одного мини-пакета.
- Это не дает идеального направления к минимуму функции, но позволяет нейросети совершать гораздо более быстрые шаги, напоминая «пьяного человека, который неровной походкой, но быстро спускается с холма».
Этот подход получил название стохастический градиентный спуск. Постепенно, проходя через множество мини-пакетов, нейросеть сходится к локальному минимуму функции стоимости, обеспечивая высокое качество классификации.
📊 Данные — это ключ 11:55
Для эффективной работы любого алгоритма обучения, включая нейронные сети, критически важно наличие больших объемов размеченных данных. Классическим примером в машинном обучении является база данных MNIST, содержащая тысячи рукописных цифр, размеченных людьми. Одной из главных проблем для инженеров остается поиск и подготовка таких качественных размеченных датасетов.




