В новом выпуске подкаста «The Cognitive Revolution» ведущий Натан Лабенц обсуждает с сооснователями некоммерческой исследовательской организации Timaeus — Джесси Хугландом и Дэниелом Мёрфетом — амбициозный подход к безопасности и интерпретируемости ИИ. В основе их работы лежит «сингулярная теория обучения» (Singular Learning Theory, SLT), объединяющая алгебраическую геометрию и статистику для понимания того, как обучающие данные формируют внутреннюю структуру нейросетей.
🏛️ Философские корни: Платон и «Теория всего» 6:02
Название организации Timaeus (Тимей) отсылает к одноимённому диалогу Платона, в котором философ изложил первую в истории «теорию всего» . В этом трактате элементы стихий (земля, воздух, огонь) связывались с платоновыми телами (куб, икосаэдр и др.). Дэниел Мёрфет отмечает, что хотя сама теория физически неверна, важен дух идеи: математика способна объяснить устройство мира .
В концепции «Тимея» мир разумен, а история Вселенной — это процесс обучения, где физика является лишь подмножеством теории обучения . Хотя гости признают этот тезис провокационным, они подчеркивают глубокую связь между статистической физикой и машинным обучением .
Дэниел Мёрфет, в прошлом профессор алгебраической геометрии, оставил академическую карьеру ради работы в Timaeus. Его интерес к ИИ начался с работ японского математика Сумио Ватанабэ, создателя SLT . Ватанабэ доказал, что глубокие пласты алгебраической геометрии лежат в основе байесовской статистики, что позволяет использовать геометрические инструменты для анализа нейросетей .
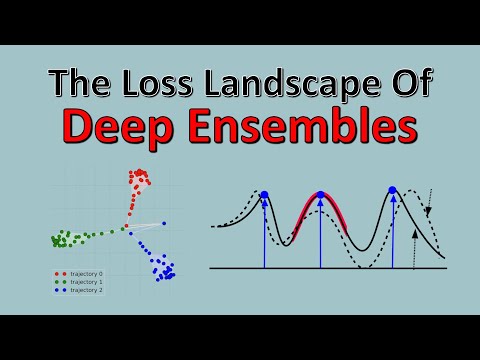
📉 Ландшафт потерь: за пределами «гладких чаш» 33:45
Традиционно процесс обучения нейросети представляют как спуск по гладкой поверхности «чаши» к точке минимума ошибок. Однако, по мнению Дэниела Мёрфета, такие визуализации «максимально вводят в заблуждение» . В действительности ландшафты потерь сверхвысокой размерности — это зазубренные поверхности, полные сингулярностей и вырождений (degeneracies) .
Ключевые идеи о ландшафте потерь:
- Вырождение (Degeneracy): Это направления в пространстве весов, двигаясь по которым модель не меняет своё внешнее поведение или показатель потерь, но может радикально менять внутреннюю архитектуру (схемы) .
- Сингулярности: Точки, где градиент равен нулю во всех направлениях. Они организуют траектории обучения, подобно тому как максимумы и минимумы определяют форму кривой в расчетах .
- Геометрия и обобщение: Согласно SLT, именно количество «долин» или «каньонов» (степень вырождения) определяет, насколько хорошо модель будет обобщать знания .
Джесси Хугланд поясняет: простые функции могут быть реализованы в нейросети огромным количеством способов. Чем больше вариантов реализации функции (больше объём в пространстве параметров), тем легче её «найти» алгоритму оптимизации (SGD) . Это создает естественную склонность ИИ к более простым решениям (бритва Оккама в математическом выражении) .
🧬 Эмбриология ИИ и развивающаяся интерпретируемость 11:35
Timaeus продвигает подход, который они называют «развивающейся интерпретируемостью» (developmental interpretability) . Вместо того чтобы изучать только готовую модель, учёные предлагают анализировать процесс её развития в ходе обучения.
По мнению Джесси Хугланда, это позволяет упростить задачу интерпретируемости:
- Понимание изменений в модели более эффективно, чем анализ миллиардов параметров в статике .
- Единицей измерения изменений является не каждый шаг градиентного спуска, а «фазовый переход» .
- Фазовые переходы в нейросетях аналогичны стадиям развития эмбриона в биологии .
Для фиксации этих переходов используется специальный показатель — локальный коэффициент обучения (Local Learning Coefficient, LLC). Он помогает идентифицировать внутренние структурные изменения, которые могут быть незаметны по общей кривой потерь .
🧠 «Центральная догма» и соответствие S4 29:49
Джесси Хугланд формулирует «центральную догму» их подхода (соответствие S4), которая описывает цепочку формирования поведения ИИ :
- Данные (Data) определяют геометрию ландшафта потерь.
- Геометрия (Geometry) определяет путь процесса обучения.
- Процесс обучения (Learning process) выбирает финальные веса.
- Веса (Weights) определяют алгоритмы и итоговое поведение модели.
По словам Хугланда, все современные методы выравнивания (RLHF, DPO, конституционный ИИ) — это просто модификации этой цепочки через изменение данных .
📉 Гроккинг и ловушки упрощения 55:38
Участники обсудили феномен «гроккинга» — момента, когда модель внезапно переходит от заучивания данных к пониманию общего алгоритма.
Дэниел Мёрфет выделяет два типа переходов:
- Тип A: Модель становится сложнее, чтобы усвоить больше информации (нормальное обучение) .
- Тип B: Модель находит более простое объяснение для тех же данных при сохранении уровня точности (гроккинг) .
Однако простота не всегда означает безопасность. Мёрфет приводит в пример «скандал Windrush» в Великобритании . Когда государство перешло от гибкой политики к жесткому требованию документации, чиновники на местах начали использовать «упрощенные алгоритмы» принятия решений, что привело к депортации законных граждан.
Оба собеседника сошлись во мнении, что в ИИ-безопасности существует риск: модель может выбрать опасное, упрощенное решение вместо сложного и правильного, просто потому что оно занимает «больший объём» в пространстве параметров .
🧪 От алхимии к промышленной химии 1:25:23
Джесси Хугланд сравнивает текущее состояние обучения нейросетей с алхимией: «У нас есть огромный котел (архитектура), огонь (оптимизатор) и реагенты (данные), которые мы просто сваливаем в кучу и перемешиваем, надеясь, что не получится смесь хлорки с отбеливателем» .
Будущее обучения, по мнению Timaeus, должно выглядеть как промышленное химическое производство:
- Точное знание концентрации и состава данных .
- Понимание того, в какой конкретный момент обучения нужно добавить определённый набор данных .
- Использование катализаторов для управления фазовыми переходами.
В качестве примера важности контроля данных упоминается инцидент с обучением Claude 4 от Anthropic . Разработчики случайно исключили набор данных о вредоносных системных подсказках, из-за чего модель начала выполнять опасные инструкции. Это было замечено только на этапе тестирования поведения. Цель Timaeus — создать инструменты, которые позволят замечать такие «пропуски» в режиме реального времени через мониторинг геометрии модели .
🚀 Масштабирование и будущее 1:33:45
Несмотря на то, что SLT часто воспринимается как чисто теоретическая область, Timaeus уже демонстрирует её применимость на практике:
- Исследователи смогли масштабировать методы с «игрушечных моделей» до сетей с 7 миллиардами параметров .
- Удалось идентифицировать моменты фазовых переходов, соответствующие появлению важных функциональных схем (например, индукционных схем) .
- До конца года команда планирует подтвердить методы обнаружения нейронных схем в моделях 7B и начать эксперименты по управлению процессом обучения (steering) .
Джесси Хугланд надеется, что со временем это превратит обучение ИИ из метода проб и ошибок в строгую инженерную дисциплину .