Ускорение обучения нейросетей через фокусировку на самых сложных примерах 📉 0:00
Обучение глубоких нейронных сетей — процесс вычислительно затратный, где значительная часть времени уходит на обратное распространение ошибки (backpropagation). В обзоре статьи «Accelerating Deep Learning by Focusing on the Biggest Losers» («Ускорение глубокого обучения путем фокусировки на главных аутсайдерах») от Анжелы Янг и коллег, ведущий канала Yannic Kilcher анализирует инженерный подход, призванный сократить это время. Главная идея работы заключается в том, чтобы не тратить ресурсы на прохождение всей цепочки градиентов для каждого обучающего примера, а сфокусироваться лишь на тех, которые вызывают наибольшие затруднения у модели.
💡 Основная концепция: «избирательное обучение» 0:24
В традиционном цикле обучения данные разбиваются на мини-батчи, которые проходят через сеть в рамках прямого и обратного проходов. Обратный проход обычно требует вдвое больше ресурсов, чем прямой, так как необходимо обновить веса каждого слоя. Авторы исследования предлагают оптимизацию:
- Выявление «трудных» примеров: В ходе предварительного прямого прохода вычисляется значение функции потерь (loss) для каждого примера.
- Выборочное обучение: Примеры с наибольшим значением потерь считаются «трудными». Именно они отбираются для последующего полноценного обратного прохода.
- Экономия ресурсов: Обучение модели происходит только на выбранном подмножестве, что значительно снижает вычислительную нагрузку.
Как отмечает Yannic Kilcher, это базируется на упрощающем допущении: если сеть хорошо справляется со сложными примерами, она неизбежно освоит и легкие. Однако для корректной работы алгоритма требуется дополнительный, второй прямой проход по отобранным «трудным» примерам, так как для вычисления градиентов часто нужно знать промежуточные состояния слоев (например, в операциях max pool).
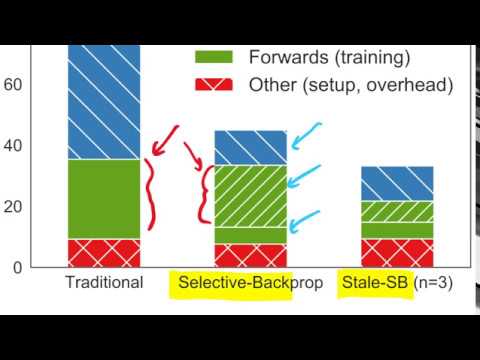
🐢 «Старое» избирательное обучение (Stale Selective Backprop) 7:08
Чтобы еще сильнее сократить накладные расходы на постоянные вычисления потерь, авторы предложили улучшенную версию алгоритма — «старое» избирательное обучение (stale selective backprop). Вместо того чтобы вычислять потери для всех примеров на каждом шаге, предлагается:
- Пропустить весь датасет через сеть один раз.
- Сохранить полученные значения потерь в базу данных.
- Использовать эти (постепенно устаревающие) данные для селекции примеров в течение нескольких эпох.
Это позволяет «амортизировать» стоимость прямых проходов, необходимых для оценки сложности примеров. Yannic Kilcher подчеркивает, что согласно экспериментам авторов, использование устаревшей информации не оказывает критического влияния на итоговую производительность модели.
⚖️ Критика метода: шум в данных и риск переобучения 11:49
Несмотря на эффективность, подход имеет существенную уязвимость, которую признают сами авторы: работа с неправильно размеченными данными.
- Проблема меток: Алгоритм считает «трудным» тот пример, где модель ошибается. Если пример размечен неверно (например, на картинке с людьми алгоритм ожидает увидеть грузовик), нейросеть будет считать его сложным и «зацикливаться» на нем.
- Итог обучения: Избыточное внимание к «шумным» или ошибочным примерам приводит к тому, что модель начинает заучивать ошибки, что вредит качеству обобщения на тестовых данных.
В ходе экспериментов выяснилось, что при 1% или 10% «перемешанных» (неверных) меток метод сохраняет преимущество в скорости. Однако при 20% неверных меток модель начинает «массивно переобучаться» на ошибках, что нивелирует все преимущества подхода.
🚀 Результаты и применимость на практике 16:18
Исследование демонстрирует впечатляющие показатели ускорения на популярных бенчмарках (SVHN, CIFAR-10). Например, на датасете SVHN метод оказался в 3,4–5 раз быстрее традиционного обучения.
Тем не менее, Yannic Kilcher выражает скепсис относительно масштабируемости этого подхода:
- Зависимость от сложности задачи: По мере усложнения задачи (например, при переходе от CIFAR-10 к CIFAR-100) выигрыш в скорости сокращается.
- Влияние смещения (bias): Фокусировка на сложных примерах вносит систематическое смещение в процесс обучения. На сложных задачах и архитектурах это смещение «бьет» по качеству модели сильнее.
- Прогноз для ImageNet: Yannic Kilcher предполагает, что для датасетов уровня ImageNet этот метод может оказаться практически бесполезным.
Ведущий заключает, что, хотя работа представляет собой качественное инженерное исследование с полезными экспериментами, авторам не хватает глубокого теоретического анализа того, как вносимое смещение влияет на финальную точность модели.