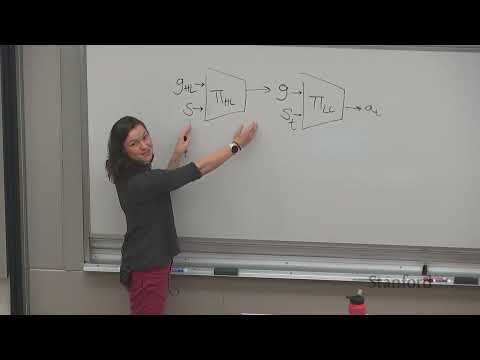
Теория и практика поиска стратегий в обучении с подкреплением 0:05
Лекция посвящена продвинутым методам поиска стратегий в обучении с подкреплением (Reinforcement Learning, RL), включая глубокое изучение proximal policy optimization (PPO) и концепцию имитационного обучения. Ведущий от Stanford Online разбирает теоретические основы оптимизации стратегий, механизмы оценки преимуществ (Advantage Estimation) и способы эффективного переноса знаний от экспертов к обучаемым агентам.
🛠 Оптимизация стратегий и PPO 4:24
Основная проблема классического метода REINFORCE заключается в низкой эффективности использования выборки (sample efficiency) и чувствительности к изменениям в пространстве параметров. В PPO для достижения монотонного улучшения используется два ключевых подхода:
- Адаптивное KL-штрафование: ограничивает изменение новой стратегии относительно старой, чтобы избежать катастрофического падения производительности.
- Клиппирование (Clipped Objective): математически аналогичный метод, препятствующий слишком резким обновлениям стратегии.
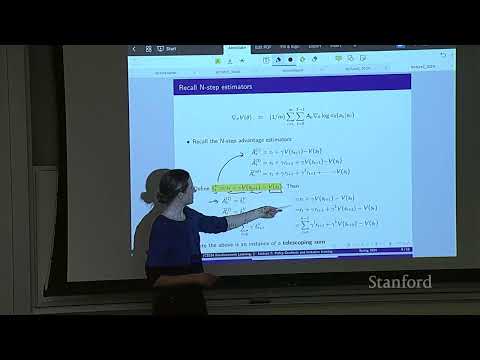
Важной частью PPO является обобщенная оценка преимуществ (Generalized Advantage Estimation, GAE). Она позволяет сбалансировать дисперсию и смещение (bias-variance tradeoff) при оценке преимущества действия, используя взвешенную комбинацию $n$-шаговых оценщиков. Ведущий отмечает, что использование телескопических сумм позволяет эффективно пересчитывать значения, не храня в памяти множество копий различных оценщиков.
📉 Монотонное улучшение и границы производительности 28:44
Теоретическим обоснованием успеха PPO служит доказательство возможности гарантированного монотонного улучшения. В основе лежит использование нижней границы (lower bound) функции производительности стратегии.
- Если мы максимизируем эту нижнюю границу, мы гарантированно получаем стратегию, которая либо лучше предыдущей, либо достигает локального оптимума.
- На практике прямая реализация этого теоретического результата часто приводит к слишком консервативным «малым шагам», из-за чего обучение занимает много времени.
Хотя PPO не гарантирует монотонность в чистом виде (из-за приближений), он приближается к ней, что делает его предпочтительным инструментом в чувствительных областях, таких как медицина или управление промышленным оборудованием.
🤖 Имитационное обучение: от Behavior Cloning к Dagger 44:05
Имитационное обучение (Imitation Learning) позволяет избежать необходимости явного задания функции вознаграждения, используя демонстрации экспертов.
Behavior Cloning (BC)
Самый прямой подход, сводящий RL к задаче обучения с учителем.
- Метод: агент обучается предсказывать действия эксперта по состоянию среды.
- Проблема: накопление ошибок (compounding errors). Небольшая ошибка на одном шаге выводит агента в область состояний, которую эксперт не демонстрировал (data distribution mismatch), что ведет к квадратичному росту ошибки в долгосрочной перспективе.
Алгоритм Dagger
Решает проблему BC через итеративное взаимодействие с экспертом:
- Агент выполняет текущую стратегию в среде.
- Эксперт («тренер») размечает, какое действие было бы правильным в каждой точке траектории, где агент совершил ошибку.
- Данные агрегируются, и модель переобучается.
- Минус: метод требует «человека в цикле» (human-in-the-loop), что крайне дорого и ресурсозатратно.
💎 Обратное обучение с подкреплением (Inverse RL)
В случаях, когда эксперт демонстрирует оптимальное поведение, но функция вознаграждения неизвестна, применяется Inverse Reinforcement Learning (IRL).
- Проблема идентификации: существует бесконечное множество функций вознаграждения, при которых одна и та же стратегия является оптимальной. Например, нулевая функция или функция, умноженная на положительную константу.
- Feature Matching: ведущий подчеркивает, что для восстановления функции достаточно найти стратегию, которая воспроизводит те же частоты признаков (feature counts), что и эксперт. В условиях, когда веса функций вознаграждения ограничены, это гарантирует близость к производительности экспертной стратегии.