Инновационная архитектура RWKV: реинжиниринг RNN для эпохи Transformer 0:00
Модель RWKV представляет собой смелую попытку объединить сильные стороны трансформеров и рекуррентных нейронных сетей (RNN), предлагая архитектуру, которая масштабируется как трансформер, но при этом обладает вычислительной эффективностью RNN. Янник Кильхер в своем разборе отмечает, что проект примечателен своей компактностью: он был разработан крайне малочисленной группой исследователей, при этом результаты модели в ряде задач сопоставимы с гигантскими корпоративными трансформерами.
🏗 Архитектура: трансформер или конволюционная сеть? 8:11
Хотя авторы RWKV часто противопоставляют ее трансформерам, Кильхер утверждает, что правильнее всего рассматривать эту модель как конволюционную нейронную сеть, работающую вдоль одномерной последовательности токенов.
- Трансформеры: Обладают преимуществом параллельного обучения, но страдают от квадратичного роста требований к памяти при увеличении длины последовательности из-за механизма causal attention,.
- Классические RNN: Требуют постоянного объема памяти при инференсе, но крайне сложны в обучении из-за последовательного характера вычислений и проблемы исчезающего градиента,.
- RWKV: Предлагает «линейный механизм внимания», который позволяет переформулировать модель как рекуррентную структуру, сохраняя возможность параллельного обучения, свойственную трансформерам.
Кильхер отмечает, что термин «внимание» здесь используется крайне вольно, так как механизм существенно отличается от оригинального динамического распределения весов.
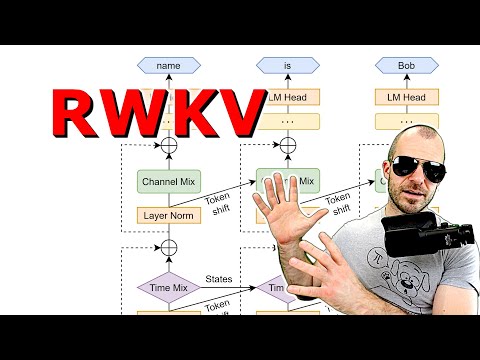
🛠 Механизмы взаимодействия: Time Mixing и Channel Mixing 31:49
Модель строится из повторяющихся блоков, каждый из которых состоит из двух основных модулей:
- Channel Mixing (Канальное смешивание): Напоминает классические полносвязные слои (feed-forward). На вход поступает сигнал $x$, который умножается на весовые матрицы для получения ключей $K$ и значений $V$. Результат пропускается через нелинейность (квадратичная функция ReLU) и умножается на «забывающий гейт» (forget gate), управляемый сигмоидой.
- Time Mixing (Временное смешивание): Именно здесь происходит работа с историей. В отличие от стандартных RNN, где скрытое состояние проходит через множество нелинейностей, RWKV использует линейное накопление прошлого.
Особую роль играет метод token shift, при котором модель линейно интерполирует входные данные текущего и предыдущего шагов. Кильхер подчеркивает, что отсутствие нелинейностей в процессе агрегации прошлого позволяет модели вычислять всё как «большую сумму», что и делает возможным параллельное обучение.
💡 Ограничения и прогнозы 56:16
Несмотря на эффективность, RWKV имеет свои минусы, о которых открыто говорят авторы архитектуры:
- Работа с контекстом: Из-за линейного механизма внимания модель может уступать трансформерам в задачах, требующих точного извлечения мелких деталей из очень длинного контекста.
- Промпт-инжиниринг: Кильхер обращает внимание, что для RWKV качество промпта зачастую критичнее, чем для стандартных трансформеров. Возможно, это связано с особенностями переноса информации из промпта в генерацию.
- Масштабируемость: Автор видео предполагает, что производительность моделей типа GPT-4 во многом обусловлена не столько спецификой трансформерного внимания, сколько именно масштабируемостью архитектуры, что дает шанс и таким проектам, как RWKV.
В заключение Кильхер отмечает, что на текущий момент RWKV — это «самая слабая» из форм памяти в сравнении с трансформерами, но за счет возможности глубокого стекинга слоев эта слабость может быть нивелирована при достаточном масштабировании.




