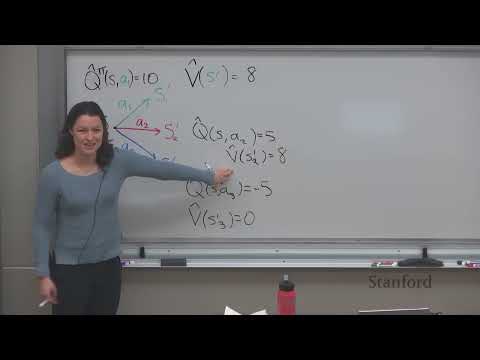Механика обучения с подкреплением в языковых моделях: погружение в алгоритм GRPO 0:34
В рамках 17-й лекции курса CS336 в Стэнфордском университете ведущий подробно разобрал техническую сторону алгоритмов policy gradient (градиента стратегии), уделив основное внимание методу GRPO (Group Relative Policy Optimization). Лектор подчеркнул, что reinforcement learning (RL) для языковых моделей обладает уникальными свойствами по сравнению с классической робототехникой, что делает обучение более гибким, но и создает специфические вызовы, такие как высокая дисперсия градиентов.
Основные концепции: RL в контексте языковых моделей 0:47
В задачах для языковых моделей состояние (state) определяется как промпт вместе с уже сгенерированным ответом, а действие (action) — как генерация следующего токена. Важной особенностью является использование «результативных наград» (outcome rewards), где функция вознаграждения оценивает весь ответ целиком, а не отдельные шаги.
- Динамика переходов: В языковых моделях она тривиальна — это просто добавление нового токена к существующей последовательности.
- Гибкость состояний: В отличие от робототехники, где физические ограничения могут сделать многие состояния недостижимыми, языковая модель может сгенерировать практически любую последовательность токенов, создавая себе «черновик» (scratchpad) для поиска правильного решения.
Политика обучения и проблема «разреженных» наград 5:37
Цель обучения — максимизировать ожидаемую награду. Классический (наивный) метод градиента стратегии предлагает просто брать градиент логарифма вероятности действий, взвешенный на награду. Однако на практике это приводит к существенным проблемам:
- Высокая дисперсия: Градиенты могут быть крайне шумными.
- Разреженные награды (sparse rewards): Если модель поначалу выдает только неправильные ответы (награда 0), она не получает сигнала для обновления параметров и «застревает».
- Изменение датасета: Важно понимать, что данные для обучения меняются от итерации к итерации, так как обновленная политика генерирует новые, потенциально более качественные ответы.
Роль базовых линий (baselines) и GRPO 15:43
Чтобы снизить дисперсию, в RL используют базовые линии (baselines) — функции $B(S)$, которые вычитаются из награды. Это не меняет математическое ожидание градиента, но значительно уменьшает шум, ускоряя сходимость.
Алгоритм GRPO (Group Relative Policy Optimization) стал популярен в 2024 году, так как он идеально подходит для LLM: модель генерирует группу ответов для одного промпта, что позволяет естественным образом вычислять относительную ценность ответов внутри группы.
- Центрирование наград: Вычитание среднего значения по группе ответов позволяет поощрять лучшие варианты и штрафовать худшие.
- Нормализация: Деление на стандартное отклонение делает алгоритм инвариантным к масштабу наград.
Практическая реализация: пример с сортировкой чисел 33:39
Для демонстрации лектор предложил простую задачу: сортировку $n$ чисел.
- Проблема частичных наград: Если давать 1 балл только за полностью верную сортировку, модель не обучится. Поэтому вводятся частичные награды за верное количество позиций или наличие токенов из промпта в ответе.
- Ловушки: Использование слишком щедрых «частичных наград» может привести к тому, что модель научится «хакать» систему, получая баллы за простые действия, но не решая задачу целиком.
- Архитектура: Лектор реализовал простую модель на Python, где каждый токен ответа декодируется почти независимо для простоты манипуляций с тензорами.
В заключение было отмечено, что при масштабировании RL-систем возникают сложности, нетипичные для пре-трейнинга: необходимость поддерживать одновременно несколько моделей (текущую, старую для стабильности обновлений и референсную для KL-регуляризации), а также организация распределенных вычислений для генерации ответов (inference).