Лингвистические модели: от рассуждений к автономным агентам 0:15
В лекции 14 курса CS224N «Reasoning and Agents» Шикхар Мурти из Stanford University подробно рассматривает две перспективные области применения больших языковых моделей (LLM): способность к логическому мышлению и возможности выполнения действий в качестве автономных агентов. В условиях бурного развития этой сферы за последние несколько лет, лектор акцентирует внимание на том, что многие вопросы остаются открытыми, а существующие методы требуют критического анализа и дальнейшего изучения.
🧠 Способы стимуляции рассуждений в LLM 1:00
Шикхар Мурти определяет рассуждение как использование фактов и логики для получения ответа, выделяя три основные категории: дедуктивное (от правил к выводу), индуктивное (от наблюдений к обобщениям) и абдуктивное (вывод объяснений из наблюдений). Для внедрения логических навыков в языковые модели применяются различные стратегии промптинга:
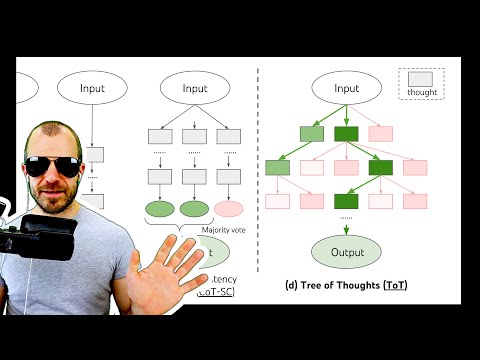
- Chain of Thought (CoT) Prompting: модель обучают или просят сгенерировать промежуточные шаги рассуждения перед выдачей итогового ответа.
- Self-Consistency: вместо одного «жадного» декодирования, модель генерирует несколько вариантов цепочек рассуждений и ответов, после чего выбирается наиболее часто встречающийся результат («мажоритарное голосование»). По наблюдениям Мурти, это превосходит простое ансамблирование разных моделей.
- Least-to-Most Prompting: метод декомпозиции сложной задачи на ряд подзадач, которые последовательно решаются моделью.
Исследователи отмечают, что с помощью достаточного инжиниринга промптов производительность стандартных методов CoT становится сопоставимой с более сложными подходами.
🛠 Дистилляция и итеративное обучение 10:09
Помимо промптинга, важным направлением является обучение небольших моделей навыкам рассуждения старших «коллег».
- Orca: пример использования дистилляции, где модель LLaMA с 13 млрд параметров дообучалась на детальных объяснениях, сгенерированных GPT-4. Это позволило меньшей модели демонстрировать более высокие результаты в рассуждениях, чем при стандартном обучении.
- Reinforced Self-Training (REST): итеративный процесс, где модель сначала генерирует рациональные обоснования, затем они фильтруются (сохраняются только те, что привели к верному ответу), и на них модель дообучается. По словам Мурти, этот метод позволяет в итоге превзойти результаты, достигнутые при обучении на эталонных обоснованиях, написанных людьми.
🔍 Проверка на прочность: рассуждение или запоминание? 20:17
Шикхар Мурти ставит под сомнение реальные способности моделей к рассуждению, ссылаясь на эксперименты с «пост-хок» объяснениями. В таких тестах было замечено, что даже при порче или сокращении цепочки рассуждений модель выдает тот же самый (иногда верный, иногда ошибочный) ответ, что указывает на отсутствие истинной логической зависимости.
Особое внимание уделяется контрафактуальному (или внераспределительному) оцениванию:
- Модели отлично справляются с базовой арифметикой в десятичной системе, но теряют точность при переходе к базе 9.
- Аналогичные падения наблюдаются в логических задачах при смене контекста (например, если «корги — это рептилии»).
- В отличие от LLM, люди демонстрируют гораздо меньшее снижение эффективности в подобных задачах.
По мнению лектора, это указывает на то, что текущие успехи моделей могут быть связаны не столько с системным логическим выводом, сколько с memorization — заучиванием паттернов из тренировочных данных.
🤖 LLM как агенты: действия в среде 30:09
Во второй части лекции обсуждается использование моделей как цифровых агентов, способных совершать действия (клики, ввод текста) в браузерах или специальных интерфейсах для достижения целей.
Эволюция подходов
- Semantic Parsers: использование машинного перевода для превращения естественного языка в исполняемые логические формы.
- Планы из примеров: обучение моделей выводить исполняемый план из инструкций.
- Reinforcement Learning (RL): прямое обучение политики действий с получением награды.
- Generative Trajectory Modeling: современный подход 2024 года, где агент предсказывает последовательность действий (траекторию) как следующую последовательность токенов, используя архитектуру трансформера.
Проблемы и будущее
Несмотря на использование синтетических данных и итеративное ре-лейблинг (повторную маркировку траекторий), агенты все еще далеки от совершенства. На бенчмарках типа MiniWoB и WebArena даже лучшие модели часто совершают тривиальные ошибки, например, вводя email-адрес в поле для пароля или зацикливаясь на неверных действиях. Мурти подчеркивает, что планирование на длинные дистанции остается серьезным барьером, а разрыв между человеческой эффективностью и возможностями ИИ-агентов остается значительным.