Как нейросеть умудряется одним быстрым импульсом заменять терабайты вычислений в бесконечном дереве вариантов? Эрик Джанг воссоздал AlphaGo всего за 3000 долларов, чтобы разгадать главную загадку искусственного интеллекта — феномен «сжатия поиска» во внутренние веса модели. Этот опыт доказывает, что законы масштабирования и уникальная инженерная культура DeepMind превращают настольные игры в прямой путь к созданию полноценного AGI.
🧠 Феномен AlphaGo: зачем пересобирать легенду и как устроена математика Го 0:31
Загадка одного прохода: зачем пересобирать AlphaGo в эпоху LLM 0:31
Развитие современных нейросетей приучило индустрию к масштабированию языковых моделей, однако фундаментальные прорывы прошлого до сих пор скрывают в себе глубокие научные загадки. Специалист по искусственному интеллекту Эрик Джанг (Eric Jang) в беседе с ведущим подкаста Дваркешем Пателем (Dwarkesh Patel) признается, что его личная мотивация заняться воссозданием легендарной системы AlphaGo с нуля была продиктована чистым исследовательским любопытством. Его поразил невероятный феномен: как относительно небольшая нейросеть способна всего за один прямой проход (single forward pass) эффективно заменять собой колоссальный, вычислительно неподъемный поиск в дереве вариантов.
До этой вехи считалось, что игра Го абсолютно не поддается традиционному компьютерному перебору из-за астрономического числа комбинаций, делающих точный поиск математически невозможным. Тем не менее AlphaGo доказала, что решения, принимаемые нейросетью, способны интуитивно направлять и сужать этот процесс до масштабов, доступных человеческому восприятию. «Для меня всегда оставалось величайшей тайной, как локальные вычисления одной сети могут так эффективно компенсировать глубину дерева», — отмечает Эрик Джанг.
Интерес к этой теме подогревается еще и тем, что технологии радикально демократизировались. В 2020 году появился успешный открытый проект, воссоздающий эти принципы, продемонстрировавший важный сдвиг: то, на что DeepMind когда-то тратила миллионы долларов, огромные исследовательские ресурсы и вычислительные мощности, сегодня может быть воспроизведено силами энтузиастов на доступном оборудовании. Воссоздание AlphaGo сегодня — это попытка заглянуть «под капот» механизма сжатия знаний.
От камней к алгоритмам: жесткая логика правил Го и компьютерный подсчет 2:09
Чтобы понять, с какой вычислительной стеной сталкивается искусственный интеллект, необходимо разобрать базовую механику и правила Го. Дваркеш Патель и Эрик Джанг наглядно демонстрируют их на доске: игроки поочередно выставляют черные и белые камни на пересечения линий. Главная цель — окружить как можно больше территории. Если группа камней соперника полностью блокируется со всех соседних пересечений по вертикали и горизонтали (диагонали при этом не учитываются), она считается захваченной и удаляется с поля. Подобная топология создает уникальные тактические паттерны, где позиционирование позволяет атаковать целые группы камней, а динамика игры становится экспоненциально сложнее с каждым новым ходом.
Однако наибольшую сложность для автоматизации представляет не сам захват, а финал партии и процедура определения победителя. В традиционных человеческих партиях игроки в определенный момент интуитивно соглашаются, что значимых ходов больше нет, и останавливают игру. Судейство в таком формате опирается на визуальное разделение «живых» и «мертвых» камней, что для компьютерного алгоритма слишком двусмысленно и сложно для формализации.
Чтобы решить эту проблему, все современные ИИ-системы для игры в Го обучаются и играют строго по методу подсчета Тромпа-Тейлора (Tromp-Taylor scoring). Суть этого подхода заключается в следующем:
- Игра продолжается до тех пор, пока на поле вообще не останется валидных ходов для обеих сторон, вынуждая заполнять все свободное пространство.
- Вместо гипотетического завершения партии игроки обязаны доигрывать её до абсолютного физического финала.
- Очки начисляются исключительно за пустые пересечения, полностью окруженные камнями одного цвета, и за сами выжившие камни этого цвета на доске.
Такой подход полностью убирает любые серые зоны и разночтения. Для ИИ метод Тромпа-Тейлора идеален: он превращает финал партии в строгое математическое уравнение, возвращающее однозначную финальную награду (return) — победу, ничью или поражение. Ранее в разговоре собеседники вскользь упоминали, что именно эта строгость правил отличает настольные игры от неопределенности реального мира, но для алгоритма это фундаментальная точка опоры.
Математика выбора: баланс исследования и эксплуатации в UCB1 и PUCT 13:02
Поскольку пространство возможных исходов в Го подвержено комбинаторному взрыву, прямой перебор дерева вариантов абсолютно невозможен. ИИ должен на каждом шаге решать классическую дилемму теории принятия решений: балансировать между эксплуатацией (exploitation) уже известных хороших ходов и исследованием (exploration) новых, потенциально более выгодных веток дерева. Для управления этим процессом на каждом узле дерева применяется строгий математический критерий выбора действий.
Каждый узел в структуре данных хранит ключевые метрики: количество визитов родительского узла и среднюю ценность действия $Q(a)$. Величина $Q(a)$ отражает математическое ожидание выигрыша при выборе конкретного хода $a$ из текущей точки, усредненное по всем сыгранным из нее симуляциям.
В классическом подходе UCB1 (Upper Confidence Bound) выбор падает на действие, максимизирующее сумму текущей ценности $Q(a)$ и специального бонуса за неизученность. Если узел посещается редко, этот бонус растет, заставляя алгоритм пробовать альтернативные варианты. Однако AlphaGo совершила шаг вперед, внедрив формулу PUCT (Predicted Upper Confidence with Trees). Основное уравнение PUCT модифицирует логику исследования за счет подключения априорной вероятности ходов:
$$\text{PUCT}(s, a) = Q(s, a) + c \cdot P(s, a) \cdot \frac{\sqrt{\sum_b N(s, b)}}{1 + N(s, a)}$$
Здесь переменная $P(s, a)$ представляет собой начальную оценку вероятности хорошего хода, выданную нейросетью. В самый первый момент времени, когда статистика посещений конкретного действия равна нулю ($N(s, a) = 0$), выбор алгоритма полностью определяется предсказанием ИИ. Но по мере накопления реальных симуляций знаменатель дроби растет, плавно снижая влияние априорного мнения ИИ. В итоге алгоритм органично переходит от интуитивного доверия стартовой оценке к строгому расчету на основе накопленной статистики побед $Q(a)$.
Ранее в беседе авторы вскользь упомянули, что именно этот механизм позволяет дистиллировать сложнейший поиск в веса модели, а также наметили общие контуры алгоритма MCTS, но ключевая магия PUCT заключается именно в динамическом переключении фокуса между исследованием и чистой математической выгодой.
🧠 Интуиция против вычислений: как сети политики и ценности направляют MCTS 25:16
Роль сетей политики и ценности: цифровая интуиция 25:16
В традиционном программировании настольных игр машинам приходилось просчитывать миллионы вариантов до самого логического завершения партии. В случае с Го из-за колоссального числа комбинаций такой перебор математически невозможен. Эрик Джанг указывает, что создатели AlphaGo изменили этот подход, фактически симулировав человеческую интуицию с помощью двух специализированных компонентов нейросети: сети политики (policy network) и сети ценности (value network). Сеть ценности берет на вход текущее состояние доски и предсказывает общую вероятность победы $P(\text{win})$. Это позволяет алгоритму «одним взглядом» оценить положение сил, опираясь на кристаллизованные знания, точно так же, как это делает опытный мастер-человек.
Вместо того чтобы блуждать в бесконечных ветвях дерева до самого финала, AlphaGo радикально сжимает пространство поиска. Система мгновенно предсказывает исход и интуитивно решает, какой шаг сделать следующим. Архитектурно это реализуется через общую нейросетевую базу, обрабатывающую двух- или трехканальное представление доски, которая затем разделяется на две независимые ветви (branching heads), параллельно выдавая распределение вероятностей ходов и оценку шансов на успех.
Архитектурные баталии: почему ResNet эффективнее Трансформеров в Го 32:54
Несмотря на тотальное доминирование архитектуры Трансформеров в современных больших языковых моделях, в робототехнике и настольных играх классические сверточные сети (CNN), такие как ResNet, до сих пор удерживают лидерство. Как объясняет Эрик Джанг, выбор конкретной архитектуры напрямую завязан на вычислительный бюджет и специфику пространственных данных. Сверточные сети обладают мощным индуктивным сдвигом (inductive bias): они изначально спроектированы так, что близко расположенные на доске камни воспринимаются как взаимосвязанные элементы. Это обеспечивает максимальную эффективность на единицу вычислительных затрат («bang for the buck») при работе с ограниченными ресурсами.
Трансформеры же вынуждены распределять внимание (attention) по всей площади доски одновременно, что усложняет локальный анализ. Практические исследования, включая проект KataGo, подтверждают, что сверточным сетям намного проще связывать ценность локальных признаков. Джанг признается:
«Я очень старался заставить трансформеры эффективно работать в этих задачах»
Однако для локальных взаимодействий на игровом поле архитектура ResNet остается более прагматичным и экономически оправданным решением.
Инициализация на данных экспертов: фундамент стабильного обучения 39:06
Попытка построить искусственный интеллект, обучающийся исключительно с нуля путем игры с самим собой — как это сделано в более поздних версиях AlphaZero —, выглядит концептуально чистой. Однако оригинальный подход AlphaGo опирался на предварительное обучение с учителем. Эрик Джанг формулирует базовую аксиому современного ИИ:
«В глубоком обучении инициализация — это всё»
Для обеспечения стабильности градиентного спуска и исключения хаотичного поведения модели на старте, разработчики начали с инициализации весов на данных реальных экспертов. Сеть сначала обучали предсказывать хорошие действия, анализируя миллионы ходов из человеческих партий.
Такая стратегия позволяет сразу получить стабильного «быстрого игрока». Джанг отмечает, что даже компактная модель объемом менее 3 миллионов параметров, обученная на экспертных данных, способна играть на удивительно высоком уровне. Это дает разработчикам возможность быстро верифицировать корректность правил игры в коде и отладить инфраструктуру перед тем, как переходить к тяжеловесным стадиям обучения с подкреплением.
Анатомия поиска: четыре этапа алгоритма MCTS 43:10
Хотя интуитивная оценка нейросетей позволяет отсечь миллионы заведомо слабых траекторий, для достижения подлинно сверхчеловеческого уровня необходим точный математический расчет. Эту задачу решает алгоритм поиска в дереве Монте-Карло (MCTS), выполняющий функцию последовательного улучшения стратегии. Вместо слепого перебора AlphaGo строит дерево симуляций, глубина и объем которого варьируются от 200 до 2048 узлов на один ход в зависимости от конфигурации.
Дваркеш Патель и Эрик Джанг детально описывают этот итеративный процесс, состоящий из четырех классических этапов:
- Выбор (Selection): Поиск начинается с корневого узла. Алгоритм спускается по уже существующим ветвям дерева, выбирая ходы с наивысшей комбинированной оценкой. Стоит отметить, что специфические формулы выбора узлов вроде PUCT, о которых шла речь в предыдущих главах, как раз и управляют балансом исследования этого пространства.
- Расширение (Expansion): Когда симуляция достигает листа дерева, который еще не был развернут, алгоритм создает новые дочерние узлы, соответствующие легальным ходам на доске.
- Оценка (Evaluation): Вместо классических случайных розыгрышей (rollouts) до конца партии, AlphaGo задействует обученные нейросети. Сеть политики вычисляет априорные вероятности ходов для новых узлов, а сеть ценности возвращает моментальную оценку позиции $V_\theta$.
- Обратное распространение (Backup): Полученное значение ценности передается вверх по всей цепочке родительских узлов, обновляя их внутреннюю статистику побед и счетчики посещений.
Благодаря такой синергии системе не требуется тратить астрономические $10^{22}$ FLOPS на генерацию одного качественного ходя, что превращает MCTS в элегантный инструмент дистилляции вычислений.
🧠 Сжатие мысли: Дистилляция поиска в веса модели 59:00
От прохода по дереву к мгновенному инсайту: механика дистилляции 1:00:23
В ходе беседы Дваркеш Патель и Эрик Джанг подходят к одному из самых красивых инженерных решений в истории искусственного интеллекта. Чтобы проиллюстрировать, насколько ресурсоемким является классический перебор вариантов, Эрик Джанг приводит яркие подробности из практики ИИ-разработки тех лет. На пике нагрузок вычислительные кластеры потребляли колоссальные объемы энергии — около 140 кВт на одну стойку. Для охлаждения таких систем приходилось использовать специальный состав, содержащий 25% пропиленгликоля. Компании калибра Jane Street шли на радикальные меры, буквально поднимая фальшполы для оперативной прокладки кабелей, а инженерам приходилось мириться с бытовым шумом, когда в дата-центрах затевали уборку прямо посреди рабочего дня.
Такая прожорливость обусловлена вычислительной сложностью. Ранее в разговоре они касались алгоритма поиска в дереве MCTS, требующего огромного количества симуляций для оценки каждого шага. Очевидно, что проводить тысячи шагов поиска на каждый ход в реальном времени слишком дорого. Решением этой проблемы становится дистилляция поиска в веса модели.
Суть процесса заключается в том, чтобы заставить нейросеть выдавать результат, эквивалентный тысячам шагов традиционного поиска, мгновенно — во время одного прямого прохода (forward pass). Эрик Джанг предлагает формализовать этот процесс через оператор MCTS $(a | s)$, преобразующий текущее состояние игры в рекомендацию по ходам. Изначально, на первых этапах обучения, базовая догадка нейросети выглядит хаотичной и размытой. Однако по мере того как дерево MCTS проводит симуляции, оно накапливает распределение визитов по узлам и находит гораздо более уверенное, оптимальное действие.
Вместо того чтобы каждый раз заново строить это гигантское дерево, процесс дистилляции фиксирует ключевые этапы:
- Расчет распределения визитов MCTS для каждого посещенного состояния.
- Использование полученного распределения в качестве целевой метки для обучения сети.
- Корректировка внутренних весов модели, чтобы она выдавала аналогичный сильный ход за один прямой проход (forward pass).
В результате, когда дистиллированная сеть сталкивается с позицией, она сразу генерирует сильный ход. Более того, если поверх этой уже улучшенной сети запустить еще 1000 симуляций поиска, алгоритм стартует с качественно более высокой базовой точки.
Траектории DAgger и аналогия с беспилотными автомобилями 1:05:55
Обсуждая математический фундамент этого процесса, Эрик Джанг проводит глубокую параллель с обучением в робототехнике и упоминает знаменитый алгоритм DAgger (Dataset Aggregation). В рамках Марковских процессов принятия решений (MDP) система генерирует последовательные траектории состояний и действий. При стандартном обучении с учителем на экспертных данных возникает классическая фундаментальная проблема. Её проще всего понять на примере беспилотного автомобиля: если обучать модель только на идеальном вождении профессионала, она никогда не увидит ошибок. Но стоит машине хотя бы немного съехать с трассы или потерять траекторию, как она полностью теряется, поскольку в её обучающей выборке просто нет примеров возвращения в правильную полосу.
В архитектуре AlphaGo дистилляция через самообучение обходит это ограничение. Даже если в процессе игры модель совершает неоптимальные ходы или оказывается в партии, которую в итоге проигрывает, на каждом отдельном шаге дерево MCTS всё равно находит наилучшее возможное исправление ситуации. Поиск MCTS постоянно корректируется и направляется внутренней оценкой ценности позиций. Таким образом, нейросеть учится не просто бездумно копировать идеальные ходы, а предсказывать те точные корректирующие действия, которые сгенерировал бы глубокий поиск MCTS, столкнись он с этой же сложной ситуацией.
Стабилизация AlphaZero: от дисперсии к единой архитектуре 1:08:09
Тем не менее, построение стабильного цикла самообучения (self-play) таит в себе множество подводных камней. Эрик Джанг отмечает, что если полагаться на чистые эвристики, система может стать крайне нестабильной. Например, специфические правила подсчета очков, такие как резолюция Тромпа-Тейлора в Го, могут приводить к тому, что на определенных этапах оценки промежуточных узлов начинают резко колебаться. Ранее в разговоре они касались критериев выбора узлов PUCT, но здесь высокая дисперсия в оценке ценности способна полностью исказить его работу. В худшем сценарии неверная оценка ценности способна полностью разрушить сбалансированность поиска.
Ранее собеседники уже разбирали роль сетей политики и ценности в структуре AlphaGo, однако для решения проблемы нестабильности инженерам пришлось пойти на важный архитектурный шаг. Во всех последующих модификациях, включая AlphaZero, эти две сети были объединены в единую монолитную архитектуру с двумя «головами». Этот шаг взял лучшее от методов временно́го различия (Temporal Difference learning, или TD-learning). Объединение сетей помогло эффективно переносить вычисленные значения ценности в промежуточные узлы дерева, радикально снижая неопределенность относительно глубины поиска. Модель получила возможность надежно инициализировать поиск с хорошей стартовой точки, замыкая самосовершенствующийся цикл, где сильная политика подкрепляет точную оценку ценности, и наоборот. Как резюмирует Джанг, заставить эту систему работать без сбоев на практике — это колоссальный труд, требующий тончайшей настройки.
🧠 Макроструктура хаоса и проклятие дисперсии в RL 1:17:12
Макроскопические решения вычислительных кошмаров 1:17:12
Успех AlphaGo заставляет переосмыслить саму природу сложных вычислительных задач. Эрик Джанг (Eric Jang) отмечает, что традиционно игра в Го воспринималась как практически неразрешимая из-за астрономического числа возможных комбинаций. Однако нейросети доказали, что даже проблемы, кажущиеся экспоненциально сложными или NP-трудными, часто имеют удивительно простые макроскопические решения. Вместо того чтобы просчитывать миллионы микроскопических вариантов на много шагов вперед, глубокая нейросеть способна упаковать колоссальные вычислительные ресурсы в один прямой проход (forward pass).
Этот прорыв заставляет задуматься о более широком классе задач в науке и индустрии. Дваркеш Патель (Dwarkesh Patel) и его гость рассуждают о том, что если Го математически близка к NP-трудным задачам, но поддается макроскопическому моделированию, то аналогичный подход применим и к другим сложнейшим вызовам, таким как предсказание структуры белка. Нейросеть не выдает абсолютно точного математического решения в каждой точке, но она позволяет добиться практически неограниченного прогресса. Реальный мир устроен так, что глубокие макроструктуры оказываются доступны для аппроксимации нейросетевыми архитектурами, что открывает путь к решению сложнейших природных симуляций.
Теория хаоса на черно-белой доске 1:20:55
Для объяснения того, как именно нейросети справляются с хаосом вариантов, Эрик Джанг приводит элегантную аналогию с прогнозированием погоды. В метеорологии невозможно абсолютно точно предсказать поведение каждого воздушного потока или узнать точную скорость ветра на высоте 6000 футов над конкретным холмом. Тем не менее, синоптики способны весьма точно определить глобальные макроструктуры — движение циклонов и общее изменение климата.
В Го ситуация идентична: детальный просчет каждого микро-шага обоих игроков на десятки ходов вперед невозможен из-за эффекта бабочки. Но существует более фундаментальная макроскопическая величина — общая траектория игры и понимание того, кто в данный момент побеждает. Не имеет значения, куда именно упадет конкретный камень, если понятен общий вектор развития доски.
Эрик Джанг замечает любопытную конвергенцию между алгоритмами искусственного интеллекта и криптографией. В криптографии задача состоит в том, чтобы сделать финальное состояние максимально хаотичным и непредсказуемым на основе входных данных. В нейросетях же, напротив, цель — пробиться сквозь этот хаос, найти устойчивые паттерны в эволюции алгоритмов и напрямую максимизировать вероятность победы.
Проблема редкой обратной связи: почему LLM обучаются хуже, чем AlphaGo 1:25:25
Центральной темой дискуссии становится глубокий разрыв в эффективности обучения с подкреплением (RL) между специализированными игровыми системами и большими языковыми моделями (LLM). В отличие от AlphaGo, где алгоритм MCTS (механику которого собеседники подробно разбирали ранее) обеспечивает плотный сигнал на каждом ходу, стандартный («наивный») RL страдает от колоссальной дисперсии.
Эрик Джанг иллюстрирует это математическим примером. Предположим, у нас есть две разные политики. Они играют друг с другом 100 матчей, и стратегия А побеждает в 51 из них, а стратегия Б — в 49. Вполне вероятно, что это минимальное преимущество вызвано чистой случайностью. Однако при наивном подходе алгоритм REINFORCE воспримет это как истинный сигнал к обучению и начнет поощрять абсолютно все ходы, сделанные в выигранных партиях, даже если часть из них были ошибочными. Как отмечал в свое время известный исследователь Андрей Карпати, этот метод можно назвать «градиентным RL», и его главная беда — в накоплении шума.
В LLMs эта проблема обостряется еще сильнее, так как декодер генерирует текст по токенам. Ошибка в перемножении вероятностей отдельных токенов драматически увеличивает дисперсию финального градиента. Чтобы справиться с этим проклятием, исследователи вынуждены использовать сложные математические инструменты:
-
Вычитание базовой линии (baseline performance) из функции награды для калибровки сигналов.
-
Использование функции преимущества (advantage function), которая оценивает, насколько конкретное действие лучше среднего ожидаемого результата.
Это напрямую возвращает нас к концепции функции ценности, которая ранее упоминалась при анализе архитектуры AlphaGo. В играх со сложной средой разработчики часто используют фиктивную игру с самим собой (fictitious self-play), где они фиксируют оппонента и пытаются «взобраться на холм» (hill climb), оптимизируя стратегию против конкретного подмножества ходов.
🤖 Законы масштабирования и демократизация ИИ: от миллионов долларов к трем тысячам 1:51:17
Законы масштабирования в настольных играх: баланс модели и поиска 1:51:17
В процессе диалога Дваркеш Патель и Эрик Джанг переходят к обсуждению фундаментальных принципов, управляющих эффективностью современных ИИ-систем. Ранее в разговоре они вскользь касались разрыва в эффективности обучения с подкреплением (RL) между большими языковыми моделями и алгоритмами AlphaGo. Однако именно настольные игры, благодаря своей жестко детерминированной структуре, служат идеальной «чистой комнатой» для вывода законов масштабирования (scaling laws).
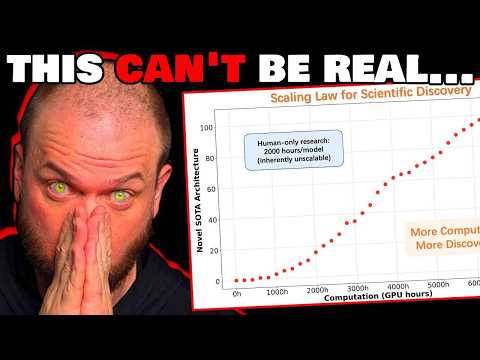
Эрик Джанг выделяет знаковую работу исследователя Энди Джонса (Andy Jones), посвященную инференс-масштабированию (inference scaling). Эта статья наглядно продемонстрировала, как именно вычислительные ресурсы могут гибко компенсировать либо физический размер нейросети, либо глубину поиска в дереве вариантов. По сути, перед инженерами встает фундаментальный выбор: сколько вычислений имеет смысл жестко «упаковать» внутрь фиксированных весов модели, а сколько — оставить на явный динамический поиск во время выполнения задачи. Если у вас небольшая нейросеть, её структурную слабость можно компенсировать более глубоким и длительным поиском; и наоборот, гигантская сеть способна принимать верные решения мгновенно, требуя минимума шагов в дереве.
Исследование Джонса примечательно тем, что выведенные им закономерности оказались универсальными. Ему удалось построить строгие математические графики законов масштабирования, которые безупречно работали в самых полярных условиях: от крошечного игрового поля размером 3x3 до бесконечной доски для игры в Го. Это доказывает, что правильное распределение compute-оптимальных параметров позволяет ИИ-боту исполнять стратегии на порядок качественнее.
Тем не менее, Джанг предостерегает от распространенной ошибки, которую сам совершил на ранних этапах проекта. Молодые исследователи часто пытаются сразу применить формулы масштабирования к сырым, еще не проверенным идеям. На практике же алгоритм действий должен быть строго последовательным:
-
Сначала необходимо создать жизнеспособный, принципиально работающий артефакт — сильного игрового бота, подтверждающего базовую гипотезу.
-
Только после того, как рабочая «рецептура» зафиксирована, можно разворачивать эмпирические законы масштабирования для оптимизации системы.
Для построения полноценных графиков масштабирования исследователь должен опираться на проблему, где плотность и объем доступных данных растут экспоненциально из года в год, обеспечивая прочный фундамент для обучения.
Радикальное удешевление разработки ИИ: эпоха доступных вычислений 1:55:58
Вторым ключевым вектором дискуссии становится феноменальный, тектонический сдвиг в стоимости воспроизведения передовых технологий искусственного интеллекта. Проекты, которые на заре эпохи глубокого обучения с подкреплением требовали от гигантов индустрии вроде Google DeepMind колоссальных бюджетов, сотен инженеров и миллионов долларов, сегодня перешли в категорию общедоступных.
Эрик Джанг иллюстрирует эту тенденцию поразительным личным кейсом. Разработка и хостинг его собственного независимого бота для игры в Го полностью развенчали миф о недосягаемости таких систем для небольших команд. Весь цикл предварительного поиска решений, проб и ошибок потребовал минимальных затрат, а финальный полноценный запуск (final run) обошелся всего в скромные 3 000 долларов на арендованных вычислительных мощностях. Когда оригинальная команда DeepMind создавала AlphaGo, они двигались вслепую, тратя миллионы на проверку базовых гипотез. Сегодня же независимые разработчики находятся в комфортном режиме, когда общая формула успеха уже известна и доказана. Исторический барьер, когда для обучения ИИ требовались промышленные суперкомпьютеры и обучение с полного нуля (tabula rasa), окончательно рухнул.
Такой скачок в доступности обусловлен не только стремительным развитием коммерческих GPU и ростом их чистой скорости, но и открытыми академическими прорывами. Джанг подробно ссылается на методологию статьи KataGo, которая перевернула подход к обучению игровых агентов. Вместо классического, крайне затратного пути чистого RL, современные системы активно используют вспомогательные цели обучения с учителем (auxiliary supervision objectives). Это позволяет вести совместное обучение (co-training) архитектуры, максимально быстро подтягивая ее к базовому экспертному уровню человека.
Когда вычислительный бюджет перестает быть непреодолимым препятствием, фокус инженерной мысли смещается на ювелирную оптимизацию каждого доступного FLOP. На самом переднем крае разработки больших моделей исследователи получают возможность скрупулезно тестировать код, отсекая неэффективные механики и проверяя, что действительно влияет на результат. Ранее в беседе авторы мимоходом упоминали концепции разметки через MCTS и структуры буферов воспроизведения (replay buffers), детальный разбор которых авторы оставляют для последующих глав. Главный же вывод Джанга монументален: демократизация технологий достигла точки, когда любой талантливый инженер, вооружившись открытыми статьями и парой тысяч долларов на облачный compute, способен в одиночку повторить ИИ-прорывы, еще десять лет назад казавшиеся вершиной человеческих достижений.
🤖 В лабиринтах RL: от буферов воспроизведения до ловушек локального мышления 2:05:56
Оф-полити обучение и «дневные грезы» нейросетей 2:05:56
Эрик Джанг (Eric Jang) подробно описывает архитектуру обучения, во многом схожую со стандартными робототехническими системами. В этой схеме буфер воспроизведения (replay buffer) непрерывно аккумулирует кортежи переходов, пока алгоритм занят постоянным перепланированием оптимальных действий. Параллельно с этим обновлятор Беллмана (Bellman updater) извлекает накопленные данные из буфера. Тренер использует собранную информацию, полученную из самых разных старых стратегий, что определяет этот подход как оф-полити (off-policy) обучение. Каждая выборка сопоставляется со значением целевой функции — $Q^{\text{target}}$.
Дваркеш Патель (Dwarkesh Patel) удачно сравнивает этот фоновый процесс с «грезами наяву» (daydreaming). Ключевое преимущество такой архитектуры заключается в мощном стабилизирующем эффекте. Когда текущая модель анализирует состояния, в которых ранее были допущены ошибки, она обучается эффективно возвращаться на оптимальную траекторию. Оф-полити подход не позволяет функции потерь хаотично взрываться, что выгодно отличает его от on-policy методов вроде REINFORCE или градиента стратегий, повсеместно применяемых для дообучения современных языковых моделей.
Информационный голод: почему RL уступает обучению с учителем 2:12:10
Размышляя о фундаментальной неэффективности обучения с подкреплением (RL), собеседники переходят к концепции информационной плотности данных. Обучение с учителем (supervised learning) дает принципиально больше бит информации на один образец, чем слепой метод проб и ошибок. Эрик Джанг иллюстрирует этот разрыв наглядным примером с текстовым промптом «Небо…». В supervised-режиме нейросеть сразу видит полноценное распределение вероятностей по всем возможным продолжениям. В чистом же RL-сценарии модель может сначала выдать случайное «Небо безмятежное», и ей потребуются тысячи неудачных итераций, чтобы случайно наткнуться на правильный вариант «синее».
Объем усваиваемой информации жестко ограничен априорной вероятностью выдать верный ответ, а в режиме крайне редкого успеха энтропия бинарной случайной величины начинает напоминать непредсказуемое подбрасывание монеты. Если построить график доли успешных попыток в логарифмической шкале, то supervised learning демонстрирует стабильный и чистый сигнал. Ранее в разговоре они касались дистилляции поиска в веса модели, и Эрик подчеркивает: именно доступ к «мягким таргетам» (soft targets) делает дистилляцию столь эффективным инструментом. Без этого RL-системы рискуют навсегда застрять в плоских локальных минимумах, где градиенты вырождаются, тогда как сигнал обучения с учителем всегда остается кристально чистым.
Автоматизация ИИ-лабораторий: Claude в роли исследователя 2:22:35
Обсуждая перспективу полной автоматизации создания искусственного интеллекта, Эрик Джанг делится личным опытом использования больших языковых моделей для написания сложного исследовательского кода. В ходе работы над проектом он активно привлекал ИИ-ассистентов, упоминая версии вроде Claude. Сегодня область применения LLM вышла далеко за рамки тривиальных задач вроде подсчета количества слоев в нейросети. Современные модели способны решать комплексные, открытые проблемы.
Типичная задача для автоматизированного агента может звучать как поиск наилучшего способа аппроксимации фиксированного набора данных в условиях ограниченного временного бюджета. В таком сценарии модель полностью берет на себя проведение экспериментов, построение аналитических графиков и самостоятельный поиск багов в кодовой базе обучения. В итоге формируется ветвистая структура — дерево исследований, где каждый отдельный узел представляет собой зафиксированную попытку, будь она успешной или провальной.
Тупик оптимизации: почему нейросетям не хватает латерального мышления 2:25:22
Несмотря на поразительные успехи LLM-кодинга, текущее поколение моделей спотыкается на мета-уровне: они не умеют стратегически выбирать, что именно делать дальше. ИИ отлично оптимизирует заданные метрики «вглубь», но полностью лишен латерального (бокового) мышления, позволяющего вовремя сменить неверный вектор исследований. В контексте скорого появления ИИ-систем класса Mythos и Mythos++ Эрик отмечает, что главной мотивацией для создания его сложной экспериментальной среды было стремление верифицировать базовое поведение агента: делает ли он именно то, что задумал создатель?
Человеческий подход к науке держится на локальной верифицируемости. Столкнувшись с падением метрик, ученый должен понять, вызвано ли это мелким багом или системной ошибкой в самой фундаментальной идее. Вся история глубокого обучения доказывает, что для радикального прорыва необходима глубокая, порой иррациональная вера в верность концепции и готовность пробиваться сквозь череду неудач. Проблема современных LLM в том, что они мыслят слишком локально. Модель может бесконечно тратить ресурсы на полировку тупикового алгоритма вместо того, чтобы масштабно взглянуть на проблему со стороны и осознать, что нужно задать совершенно другой вопрос.
🏁 Горький урок масштабирования и мост от игрового ИИ к AGI 2:30:44
🧠 Параллелизация инноваций и «Горький урок» вычислительной мощности 2:30:44
В финальной части беседы Дваркеш Патель и Эрик Джанг переходят к глубокому философскому осмыслению путей развития систем искусственного интеллекта, опираясь на знаменитый «Горький урок» (The Bitter Lesson) Ричарда Саттона. Суть данной концепции заключается в том, что долгосрочный прогресс в индустрии обеспечивается не созданием сложных, специфических алгоритмических надстроек, а планомерным увеличением доступной вычислительной мощности и объемов обучающих выборок. Эрик Джанг отмечает, что в процессе масштабного увеличения систем практически неизбежно наступает переломный момент, когда эффективность узконаправленных инженерных ухищрений начинает стремительно падать.
Когда в распоряжении разработчиков оказываются колоссальные объемы вычислительных ресурсов и миллиарды параметров, многие локальные архитектурные решения перестают приносить ожидаемую пользу. Как отмечает Эрик Джанг, масштаб обнажает две главные проблемы традиционных алгоритмических оптимизаций:
-
Алгоритмические множители перестают эффективно сочетаться и накладываться друг на друга, когда параметры и вычисления стремятся к бесконечности.
-
Выигрыш от любого локального трюка, созданного ради ускорения сходимости нейросети, носит сугубо временный и преходящий характер перед лицом чистого масштабирования.
В рамках работы над проектом AlphaGo исследователям было значительно проще верифицировать подобные гипотезы, поскольку они обладали жестким внешним циклом оценки в виде процента побед (win rate) против фиксированных версий программы или экспертов. Это давало четкий критерий истины: улучшает ли новая идея систему или является статистическим артефактом. В качестве примера фундаментальных законов масштабирования ИИ собеседники упоминают классические графики Chinchilla, которые определили оптимальный баланс между вычислительной мощностью и размером датасета.
Однако при переходе к общему искусственному интеллекту (AGI) ситуация кардинально меняется. В отличие от настольных игр с бинарным результатом, общий уровень прогресса на пути к AGI невероятно сложно измерить и формализовать. Здесь нет единого простого графика, который мог бы гарантировать, что оптимизация конкретной метрики действительно приближает человечество к созданию универсального разума.
🎮 От побед в Го к общему искусственному интеллекту: перенос опыта DeepMind 2:33:53
Второй важнейшей темой этой главы становится преемственность технологических подходов и так называемый «положительный перенос» (positive transfer) опыта из сферы игрового ИИ в область разработки больших языковых моделей. Эрик Джанг выражает твердую интуитивную уверенность в том, что опыт решения сложнейших игровых метазадач служит мощным фундаментом для современных прорывов. Команды исследователей из DeepMind, которые исторически специализировались на создании игровых агентов, сегодня успешно переключились на создание передовых LLM.
По мнению Джанга, специалисты способны эффективно переносить свои фундаментальные навыки проектирования крупномасштабных систем ИИ в совершенно новые домены. Ценность этого опыта выходит далеко за рамки написания конкретных строк кода или оптимизации алгоритмов поиска в дереве MCTS, которые подробно обсуждались ранее в разговоре. Главным активом становится уникальная инженерная культура и накопленные коллективные знания о том, как обеспечивать стабильное масштабирование и эффективную работу огромных кластеров TPU (Tensor Processing Units) в рамках сверхдлинных циклов непрерывного обучения.
При этом перенос опыта не является абсолютно прямолинейным процессом. Ранее в разговоре собеседники уже затрагивали важную роль инициализации нейросетей на данных экспертов, однако в эпоху LLM эти механики претерпевают серьезные качественные изменения. Тем не менее Джанг убежден, что даже на базе имеющихся сегодня мировых данных потенциал чистого масштабирования еще очень далек от своего насыщения.
В финале подкаста Дваркеш Патель благодарит Эрика за потрясающий и детальный разбор сложнейших концепций ИИ. Ведущий рекомендует аудитории обязательно посетить GitHub-аккаунт гостя с юзернеймом ericjang, а также подробно изучить его профильное эссе, где изложен этот глобальный тезис. В качестве напутствия исследователям собеседники подчеркивают, что интеграция алгоритмов поиска вроде MCTS для реализации механизмов рассуждения внутри компактных моделей до сих пор остается практически неизученной, но крайне перспективной областью для будущих технологических открытий.