Введение в обучение с подкреплением: ключевые концепции и перспективы 0:05
В рамках первого лекционного занятия курса Stanford CS234 профессор Эмма Бранскилл (Emma Brunskill) представила фундаментальный обзор обучения с подкреплением (Reinforcement Learning, RL). Основная идея дисциплины заключается в создании автоматизированных агентов, способных обучаться принятию эффективных решений на основе опыта. Это направление является критически важным компонентом для достижения общего искусственного интеллекта (AGI), так как интеллект неразрывно связан с умением совершать осознанный выбор в условиях неопределенности.
🚀 Почему обучение с подкреплением критически важно 0:18
Обучение с подкреплением — это не просто теоретический интерес, а практический инструмент для решения сложных задач. За последнее десятилетие методы RL позволили достичь беспрецедентных результатов в различных областях:
- Настольные игры: Система AlphaGo от DeepMind стала первой, кто превзошел профессиональных игроков в игру Го, объединив методы RL и поиск по дереву Монте-Карло (Monte Carlo Tree Search).
- Научные исследования: В области термоядерного синтеза глубокое обучение с подкреплением применяется для управления магнитными полями внутри реактора, что позволяет создавать более гибкие и стабильные формы плазмы.
- Здравоохранение: В Греции во время пандемии COVID-19 использовалась модель, разработанная Хамсой Бастани (Hamsa Bastani), для оптимизации процесса тестирования при ограниченных ресурсах.
- Большие языковые модели: ChatGPT стал ярким примером успеха RLHF (обучение с подкреплением на основе отзывов людей), где модель обучается выбирать ответы, которые люди оценивают выше, что значительно повысило её эффективность по сравнению с обычным имитационным обучением.
🍰 «Пирог» машинного обучения: взгляд Яна Лекуна 10:35
Несмотря на успехи, в сообществе сохраняется скептицизм. Профессор Бранскилл упоминает знаменитое выступление Яна Лекуна (Yann LeCun) на конференции NeurIPS в 2016 году, где он метафорично описал архитектуру машинного обучения в виде торта.
- Основа (корж): Обучение без учителя (unsupervised learning) — это главная часть, работающая с огромными объемами неразмеченных данных.
- Глазурь: Обучение с учителем (supervised learning) — важный, но менее объемный компонент.
- Вишенка: Обучение с подкреплением — по мнению Лекуна, это важная, но лишь небольшая часть общей системы.
Профессор Бранскилл отмечает важность подобных дискуссий для понимания того, как именно мы можем продвинуться в создании продвинутых интеллектуальных систем.
🧠 Четыре кита обучения с подкреплением 16:30
Обучение с подкреплением как дисциплина опирается на четыре основополагающих элемента:
- Оптимизация: Наличие четкого понятия полезности (utility), позволяющего сравнивать различные стратегии и выбирать лучшие.
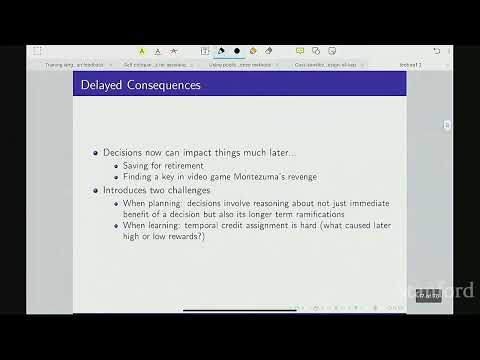
- Отложенные последствия: Понимание того, что действия сегодня влияют на результаты в далеком будущем. Это создает сложности как в планировании (когда правила известны, как в шахматах), так и в обучении (когда приходится решать задачу временного распределения кредита — какая именно серия действий привела к успеху).
- Исследование (Exploration): Агент обучается только через прямой опыт. Главная проблема здесь в том, что информация «цензурируется» — агент узнает только о последствиях предпринятых действий и никогда не узнает, что было бы, если бы он поступил иначе.
- Обобщение (Generalization): Поскольку пространство возможных состояний (например, в видеоиграх) комбинаторно взрывоопасно, агент должен уметь обобщать опыт с помощью нейронных сетей, так как перечислить все варианты в таблице невозможно.
🤖 Имитационное обучение vs RL 23:46
Участники дискуссии активно обсуждали вопрос: если у нас есть данные экспертов, стоит ли использовать имитационное обучение (Imitation Learning) вместо RL? Профессор Бранскилл поясняет, что имитационное обучение является частным случаем сведения RL к обучению с учителем (behavior cloning). Однако такой подход ограничивает возможности: если мы хотим превзойти человеческие показатели, мы не можем полагаться только на имитацию, так как агент не сможет подняться выше своего «учителя». Истинная сила обучения с подкреплением заключается в поиске стратегий, которые люди ещё не изобрели (например, алгоритмы матричного умножения AlphaTensor).
🛠 Учебные цели и логистика 33:35
Курс CS234 направлен на то, чтобы студенты научились:
- Определять ключевые особенности RL-задач.
- Формулировать прикладные проблемы как MDP (Марковские процессы принятия решений).
- Реализовывать алгоритмы в коде и оценивать их качество.
Профессор Бранскилл отдельно подчеркнула, что активное решение задач (forced recall) приносит в шесть раз большую пользу для обучения, чем пассивный просмотр лекций.




