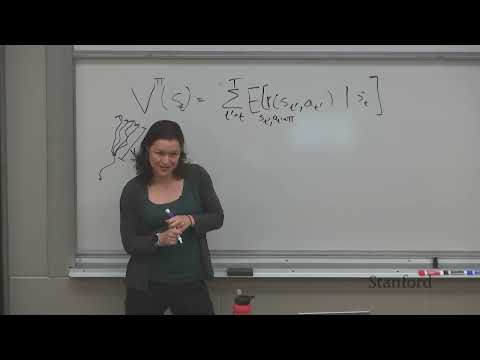
Введение в методы поиска стратегий: от базовых подходов до PPO 2:37
В шестой лекции курса Stanford CS234 эксперты Stanford Online разбирают современные методы поиска стратегий (policy search) в обучении с подкреплением, уделяя особое внимание алгоритму Proximal Policy Optimization (PPO). PPO является стандартом индустрии, используемым, в частности, при обучении ChatGPT, благодаря своей эффективности и стабильности. Лекторы объясняют переход от базовых градиентных методов к более продвинутым архитектурам «актер-критик» (actor-critic), позволяющим существенно повысить скорость обучения и качество получаемых политик.
🛡️ Стабилизация обучения: Базовые линии и смещение 5:02
Одной из главных проблем «ванильных» методов градиента стратегии (policy gradient) является высокая дисперсия оценок, что замедляет сходимость.
- Введение базовой линии (Baseline): Добавление функции $b(s_t)$, зависящей только от состояния, позволяет снизить дисперсию оценки градиента без внесения смещения (bias).
- Теоретическое обоснование: Лекторы доказали, что в математическом ожидании вычитание базовой линии равно нулю, что делает градиент несмещенным.
- Выбор базовой линии: Оптимальным выбором является среднее ожидаемое вознаграждение, близкое к значению функции ценности (value function) самой политики.
🎭 Архитектуры Актер-Критик 16:28
Для дальнейшего снижения дисперсии вводится концепция «актер-критик» (actor-critic), где обучение разделено на две части:
- Актер (Actor): Сама политика (параметризуется весами $\theta$), отвечающая за выбор действий.
- Критик (Critic): Оценка функции ценности или функции «состояние-действие» (параметризуется весами $w$), оценивающая качество принятых решений.
- Преимущество: Использование критика позволяет проводить бутстрапинг (bootstrapping), аппроксимируя значение функции вместо использования полного Монте-Карло возврата, что значительно снижает дисперсию.
⚖️ Торговля смещением и дисперсией в n-шаговых методах 21:05
При выборе целей для обучения алгоритма возникает фундаментальный компромисс между смещением (bias) и дисперсией (variance):
- TD-методы (Temporal Difference): Имеют низкую дисперсию, но высокое смещение из-за раннего бутстрапинга на основе оценок.
- Монте-Карло методы: Обладают низким или нулевым смещением (так как основаны на реальных возвратах), но страдают от крайне высокой дисперсии из-за стохастичности среды.
Лекторы подчеркивают, что оптимальный подход часто заключается в выборе $n$ шагов перед бутстрапингом для поиска баланса между этими крайностями.
🚀 Проблемы градиентов стратегии и решение PPO 31:48
Традиционные методы сталкиваются с двумя критическими препятствиями:
- Низкая эффективность выборки: Стандартные методы требуют сбора новых данных после каждого шага обновления политики (on-policy).
- Чувствительность к размеру шага: Небольшие изменения в пространстве параметров $\theta$ могут приводить к радикальным и непредсказуемым изменениям в распределении действий, что часто вызывает катастрофическое падение производительности («крах» политики).
📉 Clipped Objective (Клиппированный целевой объект)
Чтобы избежать чрезмерно резких обновлений, PPO вводит механизм ограничения (clipping) отношения вероятностей действий новой и старой политики.
- Механизм: Если изменение политики становится слишком большим (отношение выходит за пределы $[1-\epsilon, 1+\epsilon]$), функция потерь ограничивается.
- Результат: Это делает процесс оптимизации более консервативным и стабильным, предотвращая взрывное поведение весов.
- Эффективность: Графики производительности в доменах MuJoCo показывают, что PPO достигает лучших результатов быстрее, чем TRPO, при этом будучи значительно проще в реализации.