Революция в сверточных сетях: концепция Involution 0:00
Традиционные сверточные нейронные сети (CNN) долгие годы оставались стандартом в задачах компьютерного зрения, начиная от архитектуры AlexNet и заканчивая ResNet. Однако исследователи из Гонконгского университета науки и технологий, ByteDance AI Lab и Пекинского университета представили альтернативный подход — операцию Involution. По мнению автора канала Янника Килчера, данный метод предлагает эффективный компромисс между классическими свертками и механизмами селф-аттеншн (self-attention), позволяя достичь высокой производительности при значительно меньшем количестве параметров и вычислительных затрат.
Принципы работы стандартной свертки 3:01
Чтобы понять суть инновации, необходимо проанализировать фундаментальные принципы классической свертки, которые авторы предлагают «инвертировать»:
- Пространственная агностичность (Spatial Agnostic): Сверточный фильтр (ядро) обладает свойством трансляционной инвариантности. Применяя одно и то же ядро ко всему изображению, сеть выполняет идентичные вычисления независимо от расположения объекта, что является формой совместного использования весов (weight sharing).
- Канальная специфичность (Channel Specific): В стандартных CNN ядра представляют собой четырехмерные тензоры. Для каждого выходного канала создается свой набор весов, так как каждый канал призван распознавать специфические признаки (например, наличие углов, краев или конкретных объектов).
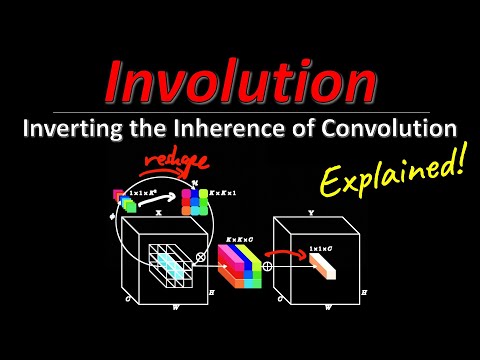
Философия Involution: переосмысление дизайна 10:32
Авторы Involution предлагают изменить эти принципы, внедрив пространственную специфичность и канальную агностичность.
- Канальная агностичность: Вместо создания множества специфичных ядер для каждого канала, используется одно ядро, которое распределяется (broadcast) по всем каналам. Это позволяет существенно сократить объем используемых параметров, так как отпадает необходимость в уникальных весах для каждого выходного канала.
- Динамическая генерация ядер: Ключевое отличие Involution заключается в том, что веса ядра не являются статичными. Для каждого конкретного пикселя ядро генерируется «на лету» с помощью небольшой нейронной сети (по сути, «бутылочного горлышка» из двух слоев).
Такой механизм делает вычисления «пространственно специфичными»: даже при прохождении одного и того же изображения, для разных областей будут использоваться разные веса, адаптированные под конкретные локальные особенности.
Связь с механизмом внимания и результаты 19:42
Янник Килчер отмечает, что Involution имеет сходство с механизмами внимания (self-attention), так как оба подхода используют «быстрые веса» (fast weights), вычисляемые непосредственно из данных. Однако в Involution отсутствует квадратичная сложность взаимодействия элементов, характерная для классического аттеншн-механизма, и нет необходимости в явной подаче позиционных кодировок, так как модель уже «знает» о расположении пикселей благодаря динамической генерации весов.
Эксперименты показывают многообещающие результаты:
- Involution демонстрирует точность, сопоставимую с ResNet-101, при этом экономит до 65% вычислительных ресурсов и памяти.
- Модели на базе Involution показывают лучшие результаты в задачах сегментации изображений.
По словам Килчера, несмотря на то, что с ростом масштаба данных эффективность Involution может уступать более общим архитектурам вроде трансформеров, для задач с ограниченными ресурсами этот подход выглядит крайне привлекательно и заслуживает внимания исследователей. Исходный код реализации уже доступен для тестирования.