Прошло более десяти лет с тех пор, как глубокое обучение совершило революцию в распознавании изображений, но робототехника долгое время оставалась «тихой гаванью», где классические методы контроля доминировали над нейросетями. Однако в «эру больших предобученных моделей» (Foundation Models) ситуация кардинально меняется. На семинаре в Стэнфордском университете (Stanford University) Дорса Садик (Dorsa Sadigh), доцент кафедры компьютерных наук, представила видение того, как робототехника может перенять успех больших языковых моделей (LLM) и какие препятствия стоят на пути создания «GPT для роботов».
🤖 Робототехника в эпоху фундаментных моделей 4:51
Фундаментные модели (Foundation Models), по определению Садик, — это системы, обученные на огромных массивах разнообразных данных в масштабе интернета (текст, изображения, речь), которые затем могут быть адаптированы для множества последующих задач (downstream tasks) . В NLP это позволило одной модели выполнять перевод, анализ настроений и ответы на вопросы — задачи, которые раньше требовали отдельных диссертаций .
В робототехнике существует два основных подхода к использованию этой идеи:
- Построение специализированных фундаментных моделей для роботов: сбор интервального объема данных (видео людей, данные симуляций, логи взаимодействия роботов) для обучения универсальной репрезентации .
- Креативное использование существующих моделей: применение ChatGPT или Vision-Language Models (VLM) для планирования задач и написания кода управления без предварительного переобучения их на робототехнических данных .
🗡️ Voltron: объединение синтаксиса и семантики 14:47
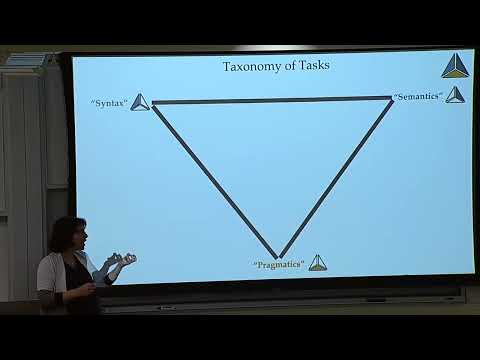
Одной из главных проблем использования визуальных моделей в робототехнике является конфликт между «синтаксисом» и «семантикой». Садик выделяет две крайности в компьютерном зрении:
- Masked Autoencoding (MAE): Модели обучаются восстанавливать замаскированные части изображения. Они отлично схватывают геометрию и края объектов (синтаксис), что критично для захвата, но не понимают смысла действий .
- Contrastive Learning (например, CLIP): Эти модели связывают изображения с текстом. Они понимают концепцию «налить жидкость» (семантика), но в процессе обучения разрушают локальные пространственные признаки, необходимые для точного движения .
Для решения этой проблемы лаборатория Стэнфордского университета разработала модель Voltron .
Ключевые особенности Voltron:
- Основа MAE: Сохраняет детализацию пикселей для понимания формы объектов .
- Языковая обусловленность: Энкодер учитывает текстовые описания (например, «очистка моркови»), что добавляет семантику .
- Динамика (Multi-frame): Модель анализирует не один кадр, а пары кадров, чтобы понимать физические изменения в мире .
- Генерация языка: Модель должна уметь описывать изменения в сцене, что углубляет понимание контекста .
В тестах по имитационному обучению (imitation learning) Voltron превзошел специализированные модели вроде R3M и MVP, особенно в задачах, требующих тонкой моторики и понимания инструкций . Эффектный пример — способность модели предугадывать момент захвата крана (intent inference) на видео с роботом, хотя модель обучалась только на видео с людьми .
📦 Проблема данных: от Open X-Embodiment до DROID 26:12
Если в NLP данных в избытке, то робототехнические данные дороги и дефицитны. Садик выделила несколько ключевых инициатив по сбору данных:
- Open X-Embodiment (RT-X): Коллаборация 21 института (включая Google), объединившая данные от разных типов роботов (cross-embodiment) в одну базу для обучения универсальной политики .
- DROID: Проект 13 институтов, направленный на сбор данных «в дикой природе» (in-the-wild) . В отличие от RT-X, здесь используется стандартизированная платформа (робот Franka с одинаковыми камерами), которую студенты перемещают по реальным локациям — от общежитий (Munger) до кухонь .
Разнообразие данных DROID позволяет роботам лучше обобщать навыки и игнорировать визуальные помехи (distractors) .
⚖️ Парадокс качества данных: «Меньше — значит лучше» 35:07
Самый неожиданный инсайт семинара связан с тем, что простое увеличение количества данных может ухудшить работу робота. Садик описала кейс, когда добавление идеальных демонстраций от второго оператора (Сидда) снизило успех робота с 14% до 7% .
Причина — мультимодальность и несовместимость. Разные люди выполняют одну и ту же задачу по-разному (например, поворачивают деталь в разные моменты времени). Когда робот обучается на противоречивых стилях, его политика «размывается», и он не может принять решение .
Стратегии борьбы с «плохими» данными:
- Фильтрация несовместимости: Автоматическое удаление данных, которые имеют низкое правдоподобие (likelihood) относительно основного набора . Это позволяет повысить успех с 38% до 54% даже при наличии шума .
- Активное руководство (Guided Collection): Использование интерфейса, который подсвечивается зеленым, если оператор действует «в стиле» модели, и красным, если он слишком отклоняется . Это помогло поднять результативность в задаче с перекладыванием яйца с 30% до 85% при том же объеме данных .
- Action Relabeling (алгоритм HYDRA): Вместо удаления данных, можно заставить людей (или алгоритмы) переразметить ключевые фазы движения, чтобы сделать действия более консистентными .
💻 Будущее: код как модальность 49:03
В завершение Садик отметила смену парадигмы в использовании LLM. Если раньше исследователи скептически относились к высокоуровневому планированию (проект SayCan), то теперь фокус смещается на генерацию самого управляющего кода (Code as Policies) .
Вместо того чтобы обучать нейросеть напрямую выводить токи в моторах, эффективнее использовать LLM для написания сложного кода на Python, который обращается к низкоуровневым примитивам робота. Это открывает путь к «социальному и физическому рассуждению» роботов, где они могут понимать сложные просьбы и даже обучать людей двигательным навыкам .




