Архитектура Transformer совершила революцию в обработке естественного языка, однако её главным ограничением остаётся квадратичная зависимость вычислительной сложности от длины последовательности. В своём видеоразборе популярный IT-блогер Янник Килчер (Yannic Kilcher) подробно анализирует статью исследователей из Google Research, предложивших модель Big Bird. Эта новая архитектура призвана решить проблему длинных контекстов, заменяя полный механизм внимания комбинацией более эффективных подходов.
🧱 Проблема квадратичной сложности классических моделей 1:46
В традиционных моделях, таких как BERT, каждый токен на каждом слое взаимодействует со всеми остальными токенами. Как объясняет Янник Килчер, для входной последовательности длиной $N$ это требует построения полной матрицы связей, что приводит к вычислительной сложности порядка $O(N^2)$ как по памяти, так и по вычислениям.
Из-за этого ограничения стандартный контекст BERT обычно зажат в рамки 512 токенов. По словам ведущего, этого вполне хватает для коротких текстов, но если перед инженером встаёт задача суммаризации целых книг, больших статей или ответов на сложные вопросы по объёмным документам, стандартные трансформеры оказываются бессильны. Удвоение длины входа увеличивает требования к ресурсам в четыре раза, что делает масштабирование крайне дорогой задачей.
🦅 Архитектурные инновации: из чего состоит Big Bird 4:37
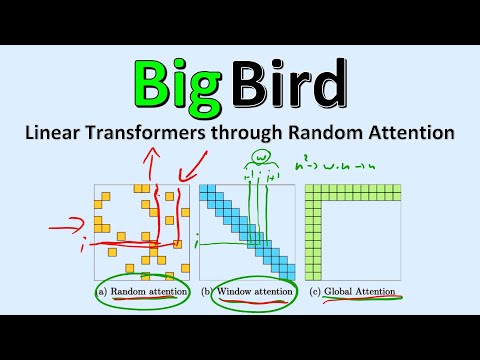
Чтобы преодолеть квадратичный барьер и свести сложность к линейной — $O(N)$, — авторы статьи из Google Research предложили модель Big Bird, названную в честь персонажа «Улицы Сезам». Полносвязный граф внимания в ней заменяется разреженным, который сочетает в себе три различных механизма:
- Случайное внимание (Random Attention);
- Оконное внимание (Windowed Attention);
- Глобальное внимание (Global Attention).
🎲 Случайное внимание и теория графов 5:58
В рамках случайного внимания каждый токен связывается лишь с фиксированным числом произвольно выбранных токенов $r$. Поскольку $r$ является константой и не зависит от общей длины последовательности, сложность падает до линейной — $O(r \times N)$.
Авторы статьи опираются на теорию случайных графов. Согласно математическим теоремам, случайное блуждание по такому графу позволяет очень быстро — за логарифмическое время — передать информацию от любого узла к любому другому. Янник Килчер предполагает, что выбранный паттерн случайных связей генерируется заново для каждой новой последовательности, но затем фиксируется и используется без изменений от слоя к слою внутри модели.
🪟 Оконное внимание и аналогия с конволюциями 10:07
Второй важный компонент Big Bird — оконное внимание, где каждый токен взаимодействует со своими непосредственными соседями в пределах заданного окна размера $w$. Этот подход обеспечивает линейную сложность $O(w \times N)$ и уже использовался ранее в другой известной архитектуре — Longformer.
Янник Килчер сравнивает работу оконного внимания с классическими свёрточными нейросетями (CNN). В свёртках каждый узел агрегирует информацию только от соседей, но по мере продвижения вверх по слоям эффективное поле зрения расширяется. По мнению ведущего, такой подход идеально ложится на специфику лингвистики, поскольку в текстах наиболее важный контекст для слова почти всегда находится в его ближайшем окружении.
🌐 Избирательное глобальное внимание 13:43
Третьим элементом системы является глобальное внимание, выделяющее критически важные токены, которые принудительно связываются со всеми остальными элементами последовательности. Ярким примером служит специальный сервисный токен CLS, традиционно используемый в трансформерах для задач классификации текста.
Благодаря глобальному токену, максимальная длина пути между любыми двумя узлами в графе Big Bird сокращается всего до двух шагов. Информация от исходного токена уходит на глобальный узел, а на следующем шаге глобальный узел транслирует её целевому токену. Именно это свойство авторы Big Bird используют в качестве фундамента для своих теоретических доказательств.
🤨 Скепсис и скрытые нюансы: критика Янника Килчера 17:15
Несмотря на концептуальную стройность Big Bird, Янник Килчер выражает смешанные чувства по поводу этой работы и указывает на ряд спорных теоретических и практических аспектов. В частности, авторы статьи доказывают, что их разреженный механизм внимания математически является универсальным аппроксиматором и обладает полнотой по Тьюрингу. Однако ведущий подчёркивает, что эти гарантии имеют серьёзную оговорку.
Для симуляции полной матрицы внимания разреженному графу Big Bird требуется пройти через цепочку из нескольких слоёв. Янник Килчер указывает на то, что в худшем теоретическом сценарии для полного восстановления вычислительной мощности классического трансформера модели Big Bird понадобится количество слоёв, равное длине самой последовательности $N$. В таком случае линейное преимущество $O(N)$ на одном слое умножается на $N$ слоёв, превращая суммарную сложность обратно в квадратичную $O(N^2)$. Ведущий с иронией сравнивает это с «линейным алгоритмом сортировки», которому для работы требуется $N$ раундов перестановок.
📊 Фокусы с параметрами в экспериментах 22:12
Ещё больше вопросов у ведущего вызывают реальные конфигурации параметров, использованные в тестах базовой (Base) версии Big Bird. При детальном рассмотрении выясняется, что размер окна, количество случайных токенов и глобальных токенов привязаны к размеру блока ($b=64$):
- Размер окна равен трем блокам ($3b = 192$ токена);
- Количество случайных токенов равно трем блокам ($3b = 192$ токена);
- Количество глобальных токенов равно двум блокам ($2b = 128$ токенов).
В сумме каждый токен одновременно обрабатывает контекст из $8b = 512$ токенов. По оценке Янника Килчера, это означает, что Big Bird на практике рассчитывает внимание для точно такого же объёма данных, что и классический BERT (512 токенов). Главное преимущество новинки лишь в том, что она способна принимать на вход последовательности длиной до 4096 токенов, выборочно игнорируя часть связей.
Напрямую же, как отмечает Килчер, эта модель «из коробки» расходует даже больше памяти и вычислительной мощности, чем стандартный BERT. Кроме того, в ряде экспериментов авторы и вовсе выставляли количество случайных токенов в ноль, фактически превращая Big Bird в Longformer.
⚡ Инженерные хитрости: как подружить разреженность с железом 25:42
Современное компьютерное оборудование (графические процессоры и TPU) крайне неэффективно работает с чисто разреженными данными и одиночными индексами. Чтобы обойти эту проблему, разработчики Big Bird применили важную инженерную инновацию — блочную структуру внимания. Вместо работы с отдельными случайными или оконными токенами алгоритм оперирует целыми блоками фиксированной длины. Аппаратное обеспечение считывает блок целиком практически за то же время, что и один токен, что даёт колоссальный прирост в скорости вычислений при незначительном оверхеде по памяти.
🔄 Операция Matrix Roll 26:47
Другой серьёзной проблемой было выделение диагональной полосы оконного внимания из общей матрицы, что обычно требует медленного построчного индексирования. Инженеры Google Research решили эту задачу с помощью математического трюка — операции сдвига осей матрицы (Matrix Roll).
Они буквально «свернули» элементы оконного внимания в компактную прямоугольную матрицу, с которой специализированные процессоры TPU работают максимально эффективно. По признанию Килчера, этот трюк приводит к небольшим погрешностям на границах текстовой последовательности, поскольку модель начинает случайно захватывать непредусмотренные токены. Тем не менее, Килчер считает такую компромиссную плату вполне оправданной на фоне резкого масштабирования производительности. Аналогичным образом в прямоугольные матрицы упаковываются и случайные блоки.
📈 Экспериментальные результаты и выводы 29:28
В практических тестах Big Bird демонстрирует превосходство над стандартными моделями RoBERTa и Longformer на ряде бенчмарков. Тем не менее, Янник Килчер призывает не переоценивать эти победы, напоминая, что превосходство в результатах нередко может быть следствием банального увеличения объёма влитых в обучение вычислительных мощностей.
Ведущий подчёркивает, что для него ключевым показателем является не сам факт завоевания статуса «State-of-the-Art» (SOTA), а способность разреженной модели удерживать высокую планку точности. Тот факт, что Big Bird успешно конкурирует с узкоспециализированными инженерными решениями, доказывает: эмпирические потери от отказа от полного внимания минимальны и полностью окупаются экономией памяти и ростом скорости работы.
Кроме NLP, авторы успешно протестировали модель на задачах геномики, где работа с длинными цепочками данных ДНК критически важна. По итоговому мнению Килчера, Big Bird представляет собой отличный и жизнеспособный компромисс для индустрии.