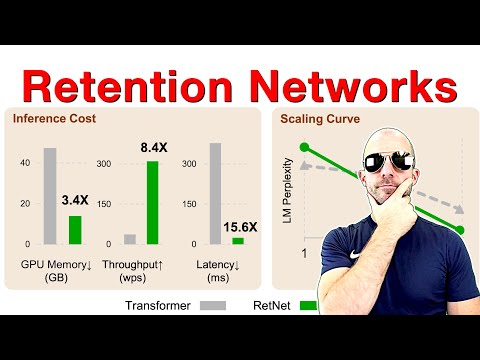
Снижение потребления памяти вдвое при одновременном ускорении инференса в четыре раза — не магия, а результат эволюции архитектуры Transformer за последние восемь лет. Переход от классического внимания к методам вроде RoPE, MQA и MLA кардинально изменил ландшафт глубокого обучения, позволяя строить эффективные модели, способные обрабатывать огромные контексты без потери точности.
🚀 Эволюция архитектуры Transformer: Путь от 2017 к 2025 году 0:25
Современные большие языковые модели (LLM) — это результат восьми лет интенсивной работы исследователей над оптимизацией оригинальной архитектуры, представленной в статье 2017 года «Attention Is All You Need». Данный курс ставит целью проследить эволюцию этих методов, направленных на повышение точности, скорости и эффективности обучения моделей.
Практическая значимость этих улучшений наглядно видна при сравнении базовой модели 2017 года с современной конфигурацией. Применение актуальных техник — таких как Multi-Head Latent Attention, оптимизированная нормализация и отказ от dropout — позволяет добиться впечатляющих результатов:
- Снижение функции потерь (Loss): Удалось достичь уменьшения loss на 11% по сравнению с архитектурой 2017 года.
- Оптимизация памяти: Потребление видеопамяти (VRAM) при обучении на аппаратном обеспечении уровня RTX 4070 снизилось с 7 ГБ до 3,5 ГБ — сокращение на 50%.
- Скорость вывода (Inference): Производительность возросла с ~100 до более чем 400 токенов в секунду.
Эти данные подтверждают, что предложенные сообществом идеи не только теоретически обоснованы, но и критически важны для практического использования ресурсов GPU при дообучении моделей.
🧩 Методы позиционного кодирования: Зачем это нужно? 4:43
Одной из фундаментальных задач архитектуры является передача модели информации о порядке слов. Без позиционного кодирования механизм self-attention воспринимает слова как «мешок токенов»: вектор слова «hi» будет идентичным вне зависимости от того, стоит ли оно в начале, середине или конце предложения. Позиционное кодирование необходимо, чтобы модель понимала синтаксические и семантические связи, зависящие от порядка слов.
Основные подходы к решению этой задачи делятся на абсолютные и относительные методы.
🔢 Абсолютные методы: Learnable и Sinusoidal 6:43
Абсолютные методы подразумевают присвоение каждому индексу позиции уникального вектора, который затем суммируется с эмбеддингом токена.
- Learnable Positional Encoding: В этой модели создается матрица весов размером
block_sizeнаembedding_size, которая обучается вместе с остальными параметрами сети. Ключевой недостаток — отсутствие обобщающей способности: модель не может работать с последовательностями длиннее, чем размер блока, на котором она обучалась. Кроме того, позиции не имеют внутренней взаимосвязи (модель не знает, что позиция 5 предшествует позиции 20). - Sinusoidal Positional Encoding: Вместо обучаемых параметров используются фиксированные математические формулы на основе функций синуса и косинуса. Преимущество этого метода в том, что он не требует обучения дополнительных весов и позволяет обрабатывать последовательности любой длины, используя заданные частотные характеристики волн.
Эксперименты показывают, что использование любого типа позиционного кодирования (как Learnable, так и Sinusoidal) значительно превосходит вариант обучения модели без какой-либо информации о позициях, который неизбежно приводит к стагнации и недообучению.
📏 Относительные методы и переход к RoPE 10:30
В отличие от абсолютных методов, относительное кодирование фокусируется не на конкретной позиции токена, а на расстоянии между словами. Этот подход модифицирует работу механизма self-attention, чтобы учитывать «дистанцию» между токенами: например, расстояние между одинаковыми словами равно 0, а для слов до и после текущего — отрицательные и положительные значения соответственно. Важным преимуществом является интуитивность: близкие слова оказывают большее влияние, чем далекие, что соответствует структуре естественного языка.
В дальнейшем исследователи пришли к методу Rotary Positional Embedding (RoPE), который объединяет преимущества обоих подходов, сохраняя относительные расстояния через вращение эмбеддингов в пространстве. (Более детальный разбор RoPE будет рассмотрен во второй главе).
🧠 Взлет Rotary Positional Embedding (RoPE): Идеальный баланс в кодировании позиций 48:28
Ранее в разговоре подробно рассматривались базовые методы позиционного кодирования, включая синусоидальный подход и классическое относительное кодирование с обучаемыми параметрами. Несмотря на то, что относительный метод показал наилучшую точность на обучении и валидации, его главным недостатком оказалась крайне низкая скорость работы — процесс обучения модели растянулся на 5 часов против всего 2 часов у синусоидального аналога. Именно эта вычислительная проблема подготовила почву для появления революционной технологии, которая доминирует в современных больших языковых моделях (LLM). Автор переходит к разбору третьего, наиболее эффективного метода — Rotary Positional Embedding (RoPE).
Поворотный момент: концепция вращения без дополнительных параметров 48:28
Главное и неоспоримое преимущество метода Rotary Positional Embedding заключается в том, что он абсолютно не добавляет в архитектуру новые обучаемые параметры. Для инженеров, стремящихся оптимизировать потребление памяти и ускорить вычисления, это становится идеальной отправной точкой. Вместо того чтобы прибавлять позиционные векторы к токенам или создавать громоздкие матрицы смещения, RoPE элегантно трансформирует саму математику взаимодействия векторов внутри механизма внимания.
Суть подхода сводится к тому, что алгоритм напрямую модифицирует векторы ключей (Key) и запросов (Query), физически вращая их в многомерном пространстве перед тем, как запустить процедуру вычисления весов внимания. Такое вращение позволяет естественным образом закодировать относительное расстояние между токенами: чем сильнее повернуты векторы друг относительно друга, тем дальше токены находятся в исходном тексте. Чтобы наглядно продемонстрировать эту концепцию широкой аудитории, лектор адаптировал сложную архитектурную схему, использовавшуюся ранее для относительного кодирования, и существенно упростил её под нужды RoPE. Подобный визуальный подход помогает детально разобраться в происходящих «под капотом» процессах, не ограничиваясь сухим чтением программного кода.
Архитектурные изменения: модификация векторов Query и Key 48:56
В новой схеме архитектурные изменения локализованы в строго определенном месте, что делает концепцию RoPE невероятно изящной. При обработке входной последовательности токенов вся остальная логика нейросети остается неизменной, а фокус внимания смещается исключительно на этап генерации тензоров Query (запросов) и Key (ключей) внутри голов механизма Attention.
В традиционных реализациях, как отмечает автор, векторы запросов и ключей формируются напрямую из эмбеддингов токенов и сразу перемножаются. В случае с RoPE в этот пайплайн добавляется промежуточная операция вращения тензоров, которая на обновленных схемах обозначается специальной круговой иконкой поворота. Спикер подчеркивает:
«Единственное, что вам действительно нужно изменить — это этап создания тензоров ключей и запросов из входных данных: вы будете вращать их перед расчетом весов внимания».
Благодаря этому математическому трюку, когда повернутые векторы Query и Key перемножаются через матричное умножение, информация об их взаимном расположении вычисляется автоматически. Это полностью исключает необходимость в ресурсоемких операциях вроде бродкастинга (broadcasting) или создания громоздких таблиц смещения для позиций, которые так сильно замедляли относительное кодирование на этапе обучения.
Интеграция в код: базовый класс и магия частот RoFormer 49:34
Для демонстрации практической реализации RoPE автор переключается в редактор VS Code и открывает скрипт под названием model_rope. Процесс интеграции начинается с самого верхнего уровня — конструктора основного класса языковой модели GPTLanguageModel. Сюда добавляется критически важный гиперпараметр, управляющий вращением — базовая частота rope_base_frequency, значение которой по умолчанию устанавливается равным 10 000.
Лектор делает важное историческое и техническое примечание: это магическое число 10 000 взято непосредственно из оригинальной научной статьи, представившей миру архитектуру RoFormer. Именно эта базовая частота используется встроенными математическими формулами для расчета сложного спектра частот, определяющих углы поворота векторов в разных измерениях.
Далее в коде инициализируется специализированный класс RotaryPositionalEmbedding, который берет на себя все низкоуровневые вычисления этих частот и результирующих эмбеддингов. Полученные позиционные структуры передаются в качестве параметров конструктора внутрь трансформерного блока (block). Архитектурный путь передачи данных здесь полностью повторяет логику, применявшуюся для относительного кодирования: из блока позиционные эмбеддинги спускаются еще глубже — непосредственно в слой многоголового внимания multi_head_attention_layer. Внутри метода __init__ этого класса закладывается прочный фундамент для динамического изменения векторов в forward pass, детальный разбор кода которого позволяет увидеть, как теоретическая концепция многомерного вращения превращается в высокопроизводительный инструмент для обучения современных передовых LLM.
🧠 Роторное позиционное кодирование и механизмы внимания
Реализация Rotary Positional Embedding (RoPE) 50:25
В основе метода RoPE лежит идея обработки пар значений эмбеддинга как комплексных чисел. Для этого процесс вычислений проходит в цикле до половины размера эмбеддинга, где каждые два значения объединяются в одно комплексное число. Формула частоты заимствована из статьи «Roformer» и использует базовую частоту, установленную по умолчанию на 10 000. После вычисления частот (theta) они умножаются на индексы позиций с помощью torch.outer, что позволяет получить тензор нужной размерности для последующего вращения. Значения theta вычисляются только один раз при инициализации модели, аналогично синусоидальному кодированию.
Для применения вращения тензор входных данных $X$ размерности $(B, T, D)$ приводится к виду $(B, T, D/2, 2)$, чтобы разделить эмбеддинги на пары. После преобразования в комплексный вид выполняется умножение на предварительно вычисленные частоты, что и осуществляет поворот в комплексной плоскости. В завершение тензор переводится обратно в вещественные числа и «сплющивается» до исходной размерности $(B, T, D)$. Ранее в разговоре упоминались методы позиционного кодирования из первой главы.
Сравнение RoPE с другими методами 1:00:15
В экспериментах RoPE продемонстрировал результаты, близкие к относительному позиционному кодированию по значению функции потерь. Однако, благодаря тому что обучение RoPE заняло 2 часа против 5 часов у относительного кодирования, метод оказался в 2,5 раза быстрее при лучшей обобщающей способности на валидации. Отказ от использования любого позиционного кодирования приводит к значительному росту функции потерь, что подтверждает критическую важность этих механизмов для производительности модели.
Базовый механизм Multi-Head Attention (MHA) 1:04:01
Многоголовое внимание (MHA), представленное в статье «Attention Is All You Need» в 2017 году, остается фундаментальной архитектурой. Оно вычисляет оценки внимания параллельно в нескольких «головах», что позволяет модели фокусироваться на различных аспектах входных данных одновременно. В каждой голове входные данные проецируются в матрицы Query, Key и Value. При генерации текста (decoder-only архитектура) применяется маскирование будущих токенов, чтобы модель не имела доступа к информации, которую она должна предсказать. Матрица оценок внимания получается путем умножения Query на транспонированную матрицу Key с последующим масштабированием.
Оптимизация: Multi-Query Attention (MQA) 1:10:37
Метод MQA, описанный в статье «Fast Transformer Decoding», нацелен на повышение эффективности использования памяти путем сокращения KV-кэша. В отличие от MHA, где для каждой «головы» существуют свои матрицы Key и Value, в MQA все головы используют одну и ту же пару K и V. Это радикально ускоряет инференс при генерации токенов. Несмотря на теоретически меньшее разнообразие представлений, эксперименты показали, что MQA может работать даже лучше MHA на определенных наборах данных. Исследование также подтверждает, что преимущество в скорости инференса наиболее заметно при генерации небольшого количества токенов (до 7 раз быстрее при 100–200 токенах), но постепенно сокращается при увеличении длины последовательности.
-
🧠 Эволюция механизмов внимания: от MHA к MQA и локальным окнам 1:16:11
В архитектуре трансформеров механизм внимания претерпел значительные изменения, стремясь найти оптимальный баланс между вычислительной эффективностью и способностью модели улавливать контекст. В качестве отправной точки выступает классический Multi-Head Attention (MHA), ставший стандартом для оценки всех последующих модификаций.
Multi-Head Attention (MHA): Золотой стандарт 1:16:11
Классический механизм Multi-Head Attention (MHA), внедренный в 2017 году, остается эталоном для сравнения. В MHA каждая «голова» (head) внимания обладает собственными, независимыми матрицами запросов (Query), ключей (Key) и значений (Value). Это позволяет модели параллельно фокусироваться на различных аспектах входных данных. Однако при инференсе, особенно для длинных последовательностей, независимость этих матриц требует значительных вычислительных ресурсов.
Multi-Query Attention (MQA): Скорость превыше всего 1:16:11
Multi-Query Attention (MQA) предлагает радикальное упрощение, направленное на ускорение генерации текста. В отличие от MHA, в MQA все головы запросов делят между собой одну и ту же пару матриц ключей и значений.
- Реализация: При выполнении операций в коде MQA использует механизм широковещания (broadcasting) в библиотеках вроде PyTorch. Матрицы $K$ и $V$ автоматически дублируются столько раз, сколько необходимо, чтобы размерности совпали с количеством голов запросов.
- Результаты: MQA значительно ускоряет инференс, однако исследователи отмечают риск снижения качества генерации при увеличении длины последовательностей. На текущем этапе разработки это делает MQA эффективным решением для задач, требующих быстрого ответа при умеренной длине контента.
Local Attention: Ограничение контекста 1:21:31
Альтернативным подходом к оптимизации является Local Attention, который ограничивает «поле зрения» каждого токена фиксированным окном. Вместо того чтобы вычислять внимание по всей длине последовательности, модель фокусируется лишь на ближайших токенах (например, на двух предыдущих).
- Эффективность vs. Контекст: Основное преимущество данного метода — снижение вычислительной сложности. Однако платой за это становится потеря долгосрочных зависимостей. Модель может «видеть» только локальный контекст, что иногда приводит к деградации производительности.
- Маскирование: Технически это реализуется через наложение дополнительной маски (sliding window mask), которая обнуляет веса внимания для токенов, выходящих за пределы заданного окна. При сравнении с MHA и MQA, Local Attention показывает достойные результаты на этапе обучения, однако его скорость инференса в ряде конфигураций может оказаться даже ниже, чем у стандартного MHA, требуя глубокой программной оптимизации.
Ранее в разговоре были затронуты темы группового внимания (GQA) и методы позиционного кодирования, которые будут детально разобраны в других разделах.
🧠 Групповой поиск внимания: Практическая реализация Grouped Query Attention 1:40:26
Трансляция логики GQA в код: Магия repeat_interleave 1:40:38
Переход от классических механизмов внимания к более оптимизированным структурам требует не просто концептуального понимания, но и хирургически точной работы с размерностями тензоров. В этой части лекции подробно разбирается внутренняя кухня Grouped Query Attention (GQA) — гибридного подхода, разработанного для достижения идеального баланса между вычислительной скоростью и качеством генерации. Главная практическая задача здесь заключается в том, чтобы корректно сопоставить количество головок ключей и значений (KV heads) с количеством головок запросов (Query heads).
В качестве живого примера рассматривается конфигурация, в которой модель имеет всего 2 головки KV (соответствующие двум группам), но при этом оперирует 6 головками запросов. Чтобы свести эти данные воедино, необходимо вычислить коэффициент повторения. Лектор демонстрирует элегантную математику: количество запросов на одну группу KV в данном сценарии строго равно 3. Таким образом, простое умножение 2 × 3 дает нам заветную шестерку, идеально соответствующую общему числу поисковых головок.
Для реализации этой операции под капотом создается специальная вспомогательная функция repeat_kv, логика работы которой строится на базовых проверках:
- Если коэффициент повторения (repetition times) равен единице, функция мгновенно возвращает исходный тензор без каких-либо дополнительных манипуляций.
- Если же этот коэффициент строго больше единицы, в дело вступает мощный нативный инструмент PyTorch — метод
repeat_interleave.
Этот метод принимает целевой тензор, принимает количество необходимых повторений и, что критически важно, позволяет жестко специфицировать размерность, которую мы хотим размножить. В нашем случае таргетом становится именно измерение количества KV-головок, поскольку цель разработчика — эффективно перемасштабировать его с 2 до 6, подгоняя под совокупное число запросов. Лектор отдельно подчеркивает ценность этой встроенной функции PyTorch: если бы не repeat_interleave, программистам пришлось бы выполнять огромный объем сложнейшей «акробатики» с тензорами (gymnastics) и операциями изменения формы, чтобы добиться аналогичного результата. Данный алгоритм масштабирования применяется симметрично и для матриц ключей (Key), и для матриц значений (Value).
Математический конвейер: От вычисления весов до финального дропаута 1:42:11
Как только подготовительный этап завершен, а матрицы ключей и значений успешно приведены к нужным пропорциям, система переходит к стандартному математическому конвейеру внимания. Архитектура больше не требует специфических надстроек, и весь последующий процесс опрашивает классическую формулу вычисления весов. На вход подается стандартное матричное умножение, результатом которого становятся сырые веса внимания.
Последовательность шагов внутри forward-прохода выглядит следующим образом:
- Первым шагом к полученным весам применяется причинно-следственная маска (causal mask), которая исключает влияние будущих токенов на текущий контекст, после чего данные пропускаются через функцию активации Softmax.
- Для предотвращения переобучения и повышения обобщающей способности модели накладывается небольшое количество дропаута (dropout).
- Отрегулированная маскированная матрица перемножается с матрицей значений (V), формируя итоговый выходной тензор, обозначаемый в коде как Y.
Однако на этом этапе разработчик сталкивается с техническим нюансом: промежуточные вычисления оставляют тензор в четырехмерном пространстве. Для корректного вывода модели необходимо произвести обратное слияние (merge) размерностей количества головок запросов (query heads) и размера самой головки (head size). Именно эта операция выполняется в финальных строках блока кодирования. Завершающим штрихом становится еще один слой дропаута, который применяется непосредственно перед тем, как класс GroupedQueryAttention вернет окончательный очищенный результат вычислений.
Архитектурная дилемма: Слияние слоев против выделенного класса Head 1:42:53
Важным элементом повествования становится обсуждение чистоты архитектурного кода и оптимизации вычислений. Лектор обращает внимание на то, что в текущей реализации авторы намеренно отказались от использования изолированного класса Head, который часто встречается в базовых академических моделях. Вместо этого вся логика обработки индивидуальных головок была полностью интегрирована (fused) внутрь единого класса внимания.
Этот выбор напрямую влияет на структуру данных. Проектирование слоя без выделенного класса Head оставляет тензор четырехмерным на протяжении всех внутренних этапов вычислений. Если бы разработчики пошли по альтернативному пути и сохранили отдельный класс для каждой головки, им пришлось бы оперировать трехмерными тензорами, выполняя все расчеты изолированно, а затем принудительно осуществлять конкатенацию (склейку) выходов от каждой головки в самом конце пайплайна. Фьюзинг (слияние) позволяет избежать лишних накладных расходов на создание объектов и делает код более монолитным.
Для того чтобы каждый студент мог самостоятельно пощупать эти концепции руками, запустить бенчмарки и верифицировать полученные результаты, лектор демонстрирует специально подготовленный интерактивный блокнот Jupyter под номером 923 improving transformer grouped query attention.
Стоит отметить, что далее в рамках этого видеофрагмента автор переходит к детальному разбору альтернативных подходов, таких как линейное внимание (Linear Attention) и разреженное внимание на базе алгоритмов Big Bird, включая демонстрацию работы с масками и разбор интерактивного кода в терминале VS Code, однако эти темы подробно раскрываются в последующих главах нашего большого обзора.
⚡ Эволюция механизмов внимания и оптимизация архитектуры 2:05:42
По мере роста потребностей в обработке длинных контекстов и повышения эффективности инференса, классические подходы к архитектуре трансформеров потребовали радикальных изменений. В этот период были разработаны методы, позволяющие преодолеть квадратичную сложность стандартного внимания и оптимизировать использование памяти.
Linear Attention: Преодоление квадратичного барьера 2:10:36
Одной из фундаментальных проблем стандартного механизма внимания (Attention) является его вычислительная сложность $O(N^2)$, где $N$ — длина последовательности. При работе с длинными текстами это приводит к экспоненциальному росту требований к памяти и времени вычислений.
Linear Attention предлагает элегантное решение: аппроксимацию механизма внимания, которая снижает вычислительную сложность до линейной $O(N)$. Это достигается за счет изменения порядка матричного умножения в механизме softmax-внимания, что позволяет трансформеру обрабатывать значительно более длинные последовательности, сохраняя при этом приемлемое качество генерации. Несмотря на то, что в более современных конфигурациях часто отдается предпочтение другим методам, Linear Attention остается важным этапом в поиске путей оптимизации трансформеров.
Sparse Attention (Big Bird) и другие подходы 2:05:42
В стремлении еще сильнее оптимизировать обработку контекста, исследователи представили методы разреженного (sparse) внимания, такие как Big Bird. Основная идея Big Bird заключается в комбинировании различных стратегий доступа к данным:
- Глобальное внимание: позволяет модели фокусироваться на критически важных токенах всей последовательности.
- Локальное внимание: обеспечивает передачу информации между соседними токенами.
- Случайное (random) внимание: помогает расширить рецептивное поле модели без необходимости связывать каждый токен с каждым.
Благодаря такой структуре, Big Bird достигает линейной зависимости сложности от длины текста, что делает его крайне эффективным инструментом для задач, требующих анализа очень длинных документов, где стандартный механизм внимания потребовал бы непомерных вычислительных затрат.
Ранее в разговоре были затронуты темы Multi-Head Latent Attention (MLA), методов активации, нормализации (включая Layer Norm и RMS Norm) и их влияния на стабильность обучения и предотвращение проблем с градиентами.
-
🚀 Собираем «Идеальный Трансформер»: Нормализация, SwiGLU и финальный апгрейд 2:30:53
Завершая масштабный разбор архитектуры Transformer, мы переходим к этапу тонкой настройки. Когда основные механизмы внимания уже определены, в игру вступают детали, которые на первый взгляд кажутся вспомогательными, но на деле определяют стабильность обучения и итоговый Loss модели. В этой главе мы разберем эволюцию нормализации, выбор функций активации и увидим, как пошаговое внедрение всех современных «фишек» позволяет снизить ошибку на рекордные 11.4%.
Смена парадигмы нормализации: RMS Norm против Layer Norm 2:30:53
Стандартом в оригинальном Трансформере долгое время оставался Layer Norm. Однако современные архитектуры, стремящиеся к максимальной эффективности, переходят на RMS Norm (Root Mean Square Layer Normalization).
Основное различие заключается в математическом упрощении: если Layer Norm центрирует активации (вычитает среднее значение), то RMS Norm этого не делает. Это значительно снижает вычислительную сложность без потери качества работы модели. Практические тесты показывают, что разница в итоговой точности между ними составляет ничтожные 0.07% в пользу Layer Norm, что делает RMS Norm предпочтительным выбором для ускорения обучения.
Интересно, что в популярных библиотеках, таких как PyTorch, RMS Norm уже встроена, однако исследователи часто реализуют её вручную (как это сделано в скриптах Llama) для лучшего контроля над процессом.
Где ставить барьер: Pre-LN против Post-LN 2:34:58
Вопрос расположения слоя нормализации относительно блоков внимания — это всегда компромисс между стабильностью и качеством. В индустрии закрепились два подхода:
- Pre-Normalization (Pre-LN): Нормализация применяется перед слоем внимания. Это обеспечивает высокую стабильность обучения, особенно в очень глубоких сетях, так как модель становится менее чувствительной к выбору гиперпараметров.
- Post-Normalization (Post-LN): Нормализация ставится после слоев. Такой подход сложнее обучать, он требует тщательного подбора параметров, но в конечном итоге часто позволяет добиться более высокого качества на финальных этапах.
В бенчмарках на небольших моделях Post-LN показывает лучшие результаты, однако при масштабировании до сотен слоев Pre-LN становится спасением от взрывных градиентов.
Оптимизация активации и отказ от Dropout 2:38:46
Эволюция затронула и «внутренности» полносвязных слоев (FFN). Классическая функция ReLU уступила место более сложным и эффективным вариантам.
SwiGLU сегодня признана золотым стандартом. Сравнение ReLU, GeLU и SwiGLU показывает, что последняя обеспечивает лучшую сходимость модели. При финальной сборке «лучшей модели» замена ReLU на SwiGLU дала ощутимый прирост, увеличив общую эффективность снижения Loss с 9.27% до 10.72%.
Ещё одним важным архитектурным решением в 2025 году стал отказ от Dropout.
«Если вы обучаете LLM на гигантских датасетах всего за одну эпоху, Dropout вам не нужен, так как переобучение просто не успевает наступить».
Эксперименты подтверждают: при обучении в одну эпоху модель без Dropout показывает лучшие результаты, чем с ним.
Итоговая сборка: Дорога к снижению Loss на 11.4% 2:42:04
В финале исследования мы объединили все лучшие практики, чтобы сравнить базовый Transformer 2017 года с современной итерацией. Ранее в разговоре уже упоминались преимущества RoPE и MLA, и именно они стали фундаментом этого апгрейда.
Процесс улучшения модели выглядел как пошаговая лестница:
- Шаг 0: Базовая модель 2017 года (Baseline Loss: 4.84).
- Шаг 1 (MLA): Замена Multi-Head Attention на Multi-Head Latent Attention (метод сжатия KV-кэша из DeepSeek V2). Результат: снижение Loss на 3.72%.
- Шаг 2 (RoPE): Внедрение ротационных позиционных эмбеддингов. Суммарное снижение Loss: 8.57%.
- Шаг 3 (Post-LN): Переход к Post-нормализации в dense-слоях. Суммарно: 9.27%.
- Шаг 4 (SwiGLU): Замена функции активации. Суммарно: 10.72%.
- Шаг 5 (No Dropout): Удаление слоев Dropout. Итоговое снижение Loss: 11.44% (с 4.84 до 4.28).
Этот эксперимент наглядно доказывает: современный Трансформер — это не просто механизм внимания, а тонко настроенная экосистема, где каждая оптимизация, от RMS Norm до структуры MLA, вносит свой вклад в интеллектуальную мощь модели. Хотя архитектура продолжает меняться, понимание этих фундаментальных кирпичиков остается ключом к созданию эффективных ИИ-решений.