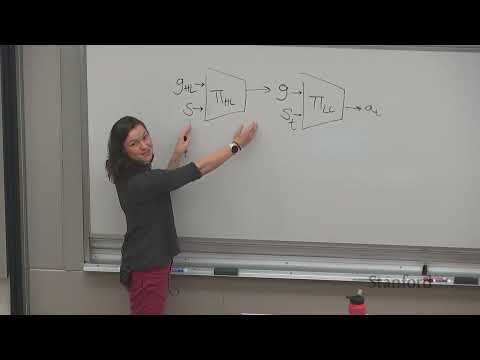
Имитационное обучение: от простого копирования к сложным стратегиям 0:05
Имитационное обучение — это способ создания интеллектуальных агентов, которые перенимают поведение эксперта, анализируя его действия. Профессор Стэнфордского университета объясняет, что в отличие от классического обучения с подкреплением, целью здесь является не максимизация награды, а точное воспроизведение стратегии демонстратора, чьи действия мы считаем эталонными.
🤖 Основы имитации: подход «Версия 0» 4:07
Самый прямолинейный метод имитации — это обучение с учителем, где модель пытается предсказать действия эксперта по состоянию среды.
- Механика: Используется обычная регрессия, например, минимизация среднеквадратичной ошибки (L2 loss) между предсказанием агента и действием человека из обучающей выборки.
- Проблема мультимодальности: В реальных сценариях, например, в автономном вождении, один и тот же входной сигнал может подразумевать разные правильные действия (один водитель едет прямо, другой перестраивается).
- Последствия L2-регрессии: При попытке «подогнать» модель под мультимодальные данные, алгоритм просто усредняет результаты, выбирая «среднее арифметическое» действие, которое в реальности может оказаться опасным или невозможным.
🧠 Выразительные распределения вместо «среднего» 14:30
Чтобы избежать усреднения, необходимо, чтобы нейронная сеть предсказывала не конкретное значение, а параметры целого распределения вероятностей.
- Дискретные действия: В играх типа Super Mario можно использовать категориальное распределение, которое является максимально выразительным для выбора из нескольких опций.
- Непрерывные действия: Здесь применяются более сложные инструменты:
- Смеси Гауссиан (GMM): Позволяют моделировать несколько «пиков» вероятности.
- Авторегрессионные модели: Подобно языковым моделям, они предсказывают каждое измерение действия последовательно. Это позволяет моделировать сложные многомерные стратегии, кондиционируя каждое последующее действие на предыдущие.
- Диффузионные модели: Современный стандарт для работы с непрерывными данными, позволяющий генерировать высококачественные предсказания через итеративный процесс удаления шума.
⚠️ Проблема накопления ошибок и способы спасения 55:06
Главная сложность имитационного обучения — это так называемый «сдвиг ковариат» (covariate shift). Агент, совершивший незначительную ошибку, попадает в ситуацию, которая не была представлена в обучающих данных, что приводит к еще большей ошибке, и так далее — ошибки начинают «накапливаться» (compounding errors).
Для борьбы с этим используются методы сбора корректирующих данных:
- DAgger (Data Aggregation): Алгоритм, при котором агент выполняет действия, а эксперт указывает, что нужно было сделать в каждой конкретной точке. Собранные данные добавляются в обучающую выборку, и процесс повторяется.
- Частичные демонстрации (Intervention): Эксперт берет полное управление на себя, когда видит, что агент начинает ошибаться. Эти моменты вмешательства являются ценнейшим сигналом для дообучения политики.
По мнению автора лекции, успех в таких задачах — это результат комбинации продуманной архитектуры нейросетей, тщательной курации данных и алгоритмов коррекции, которые позволяют агенту эффективно выходить из нестандартных ситуаций.