Алгоритм градиентного спуска: как обучаются нейронные сети 📉 0:00
В основе машинного обучения и настройки логистической регрессии лежит процесс поиска оптимальных параметров, минимизирующих ошибку модели. Видео эксперта DeepLearning.AI посвящено алгоритму градиентного спуска — фундаментальному методу, который позволяет нейронным сетям «учиться», постепенно приближаясь к наиболее точным настройкам весов.
Суть задачи: минимизация функции стоимости 🎯 0:42
Логистическая регрессия опирается на две ключевые функции:
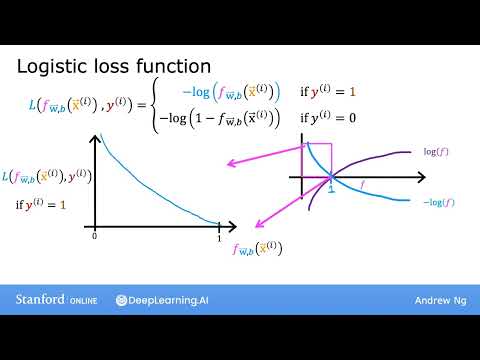
- Функция потерь (loss function): измеряет качество работы модели на одном конкретном примере из обучающей выборки.
- Функция стоимости (cost function, $J$): определяет, насколько хорошо параметры модели ($W$ и $B$) работают на всем наборе данных в целом.
Цель обучения нейронной сети заключается в подборе таких значений параметров $W$ и $B$, при которых функция стоимости $J(W, B)$ достигает своего минимума. Важным преимуществом логистической регрессии является то, что её функция стоимости — это выпуклая функция («форма чаши»), что гарантирует отсутствие множества локальных оптимумов и облегчает поиск глобального минимума.
Механика градиентного спуска 🚶 2:31
Процесс поиска параметров выглядит как итеративное движение «под гору» по поверхности функции стоимости.
- Инициализация: Параметры $W$ и $B$ задаются начальными значениями (обычно нулями).
- Шаг спуска: Алгоритм вычисляет направление самого крутого спуска и делает небольшой шаг в эту сторону.
- Итерации: Этот процесс повторяется многократно до тех пор, пока параметры не приблизятся к глобальному минимуму.
Математически обновление параметра $W$ для простой функции $J(W)$ выглядит следующим образом:
$$W := W - \alpha \frac{dJ(W)}{dW}$$
- $\alpha$ (learning rate) — коэффициент скорости обучения, который определяет размер каждого шага.
- Производная $\frac{dJ(W)}{dW}$ — это, по сути, наклон функции (градиент) в текущей точке, который указывает направление для спуска.
Навигация по склону: почему это работает 🏔️ 5:11
Логика обновления параметров интуитивно понятна, даже если вы не эксперт в математическом анализе:
- Если производная положительна (склон идет вверх), значение $W$ уменьшается, что заставляет модель двигаться влево.
- Если производная отрицательна (склон идет вниз), значение $W$ увеличивается, сдвигая параметры вправо.
В случае логистической регрессии, где параметров два ($W$ и $B$), алгоритм обновляет каждый из них одновременно, используя соответствующие производные.
Нюансы нотации и реализация в коде 💻 8:17
В математической литературе при наличии двух и более переменных вместо обычной «d» для обозначения производной часто используют символ частичной производной (стилизованная «кривая d»).
- Для программиста важно понимать: это лишь вопрос нотации, суть остается той же — измерение наклона функции по отношению к конкретной переменной.
- При написании кода принято использовать переменные
dwдля производной по $W$ иdbдля производной по $B$.
Автор отмечает, что если глубокие дебри математического анализа кажутся пугающими, не стоит волноваться: для эффективной работы с нейронными сетями достаточно интуитивного понимания того, что производная просто указывает направление «вниз» по функции стоимости.