В рамках специализации Machine Learning Specialization, созданной DeepLearning.AI, рассматривается фундаментальный вопрос оптимизации моделей классификации. Ведущий курса объясняет, почему стандартный подход, применяемый в линейной регрессии, оказывается неэффективным для логистической регрессии, и представляет новую математическую архитектуру функции потерь, необходимую для стабильного обучения нейронных сетей и алгоритмов машинного обучения.
📉 Проблема невыпуклости: почему MSE не работает 0:14
В задачах линейной регрессии традиционно используется функция стоимости на основе среднеквадратичной ошибки (MSE). Математически она представляет собой «выпуклую» (convex) функцию, по форме напоминающую чашу или гамак . Такая структура идеальна для алгоритма градиентного спуска, так как из любой точки он неизбежно сходится к единственному глобальному минимуму .
Однако при попытке применить тот же метод к логистической регрессии возникают серьезные препятствия:
- Сложная архитектура: Модель логистической регрессии использует сигмовидную функцию $f(x) = 1 / (1 + e^{-(wx+b)})$, которая вносит нелинейность .
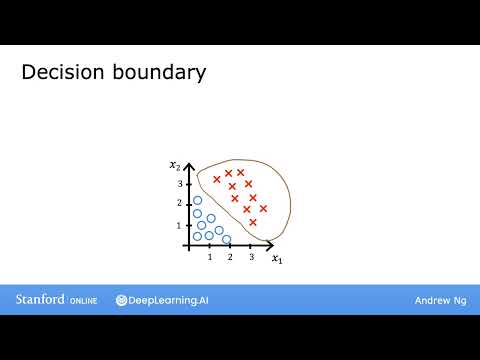
- Невыпуклость (Non-convexity): Если подставить логистическую функцию в формулу MSE, график функции стоимости станет «волнистым». На нем появится множество локальных минимумов .
- Риск застревания: При использовании градиентного спуска на такой поверхности алгоритм может «застрять» в локальном минимуме, так и не найдя оптимальные параметры $W$ и $B$ .
По мнению автора курса, именно отсутствие гарантии сходимости делает среднеквадратичную ошибку плохим выбором для задач классификации. Чтобы вернуть функции стоимости свойство выпуклости, необходимо пересмотреть само определение потерь для каждого отдельного примера .
🛠 Разделение понятий: «Потери» против «Стоимости» 3:11
Для построения новой функции стоимости вводится разграничение между двумя терминами:
- Функция потерь (Loss function): Обозначается как $L(f(x), y)$. Она вычисляет ошибку на одном конкретном обучающем примере .
- Функция стоимости (Cost function): Обозначается как $J(w, b)$. Это среднее арифметическое функций потерь по всему обучающему набору данных из $M$ примеров .
В логистической регрессии используется кусочно-заданная функция потерь, которая зависит от истинного значения метки $y$ (которая может быть либо 0, либо 1) . Это позволяет математически «выпрямить» поверхность оптимизации, сделав итоговую функцию стоимости $J$ снова выпуклой .
🎯 Анализ случая y = 1: наказание за неуверенность 4:48
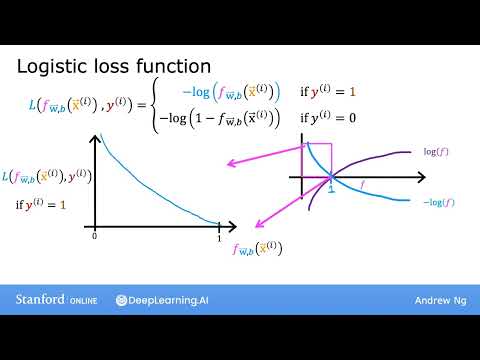
Когда истинная метка объекта равна 1 (например, опухоль является злокачественной), функция потерь определяется как отрицательный логарифм предсказания: $L = -\log(f(x))$ .
Логика этого выбора заключается в следующем:
- Идеальный прогноз: Если алгоритм предсказывает вероятность 1 (или очень близкую к ней), потери стремятся к нулю, так как предсказание совпало с реальностью .
- Средний результат: Если алгоритм выдает вероятность 0.5, потери становятся ощутимо выше .
- Критическая ошибка: Если алгоритм предсказывает вероятность 0.1 (считает, что шанс болезни всего 10%), в то время как $y=1$, функция назначает очень высокий штраф .
График этой функции на отрезке от 0 до 1 показывает, что чем дальше предсказание от единицы, тем стремительнее растут потери . Это «подталкивает» модель делать более точные и уверенные предсказания для положительного класса .
🛡 Анализ случая y = 0: борьба с ложной тревогой 7:32
Если истинная метка равна 0 (здоровая ткань), используется формула $L = -\log(1 - f(x))$ . Здесь логика зеркально меняется:
- Точное попадание: Когда предсказание $f(x)$ близко к 0, потери минимальны .
- Рост ошибки: Чем выше предсказанная вероятность, тем больше штраф, так как модель уходит дальше от истины .
- Бесконечный штраф: Если модель утверждает, что вероятность болезни 99.9% ($f(x) \to 1$), а на самом деле $y=0$, потери устремляются в бесконечность .
Автор подчеркивает, что такая жесткая минимизация ошибок крайне важна: если алгоритм ошибается в классификации, он должен получать максимально возможный «стимул» (штраф) для корректировки весов .
🚀 Практический результат: гладкая оптимизация 10:08
Главное преимущество новой логарифмической функции потерь заключается в том, что среднее этих потерь по всему набору данных всегда дает выпуклую функцию стоимости $J(w, b)$ . Хотя строгое математическое доказательство этого факта выходит за рамки курса, практические тесты подтверждают:
- Отсутствие локальных минимумов: Поверхность функции стоимости становится гладкой и похожей на чашу .
- Надежность: Градиентный спуск гарантированно находит глобальный минимум, обеспечивая наилучшие параметры модели .
- Визуализация: В лабораторных работах курса студенты могут сравнить «ухабистую» поверхность MSE и чистую выпуклую поверхность логистической функции потерь .
В следующем уроке планируется упрощение записи этой функции в одну строку, что позволит эффективно внедрить её в программный код для обучения моделей .