📚 Основы линейной классификации: от теории к практике 0:06
В третьей лекции курса Stanford CS221 (осень 2025 года) эксперты Stanford Online подробно разобрали переход от линейной регрессии к линейной классификации. Основная проблема классификации заключается в том, что задача прогнозирования меняется: вместо предсказания вещественного числа модель теперь должна делать дискретный выбор из $K$ возможных классов.
🎯 Концепция классификации и проблема принятия решений 1:17
В классификации, будь то определение объекта на изображении или анализ тональности текста, итогом является одна из $K$ категорий. В случае бинарной классификации ($K=2$) принято кодировать выходные значения как $-1$ (негативный класс) и $+1$ (позитивный класс).
- Логит (logit): Это сырое предсказание, полученное путем вычисления скалярного произведения вектора признаков на вектор весов с добавлением смещения.
- Решающая граница (decision boundary): Поверхность, на которой прогноз «не определен» (логит равен 0). Все, что по одну сторону от нее — позитивный класс, по другую — негативный.
Как отмечают лекторы, создание таких классификаторов «вручную» не является задачей машинного обучения. Цель — научить алгоритм находить оптимальную границу на основе обучающих данных.
📉 Почему стандартные подходы не работают 12:47
Первым логичным шагом кажется использование квадратичной функции потерь (как в регрессии), но она плохо подходит для классификации.
- Проблема квадратичной функции: Она штрафует модель за «слишком правильные» ответы, если логит уходит далеко от целевого значения.
- 0-1 потери (0,1 loss): Идеально отражают суть задачи (0 — правильно, 1 — ошибка). Однако у этой функции градиент равен нулю почти везде, что делает классический градиентный спуск невозможным.
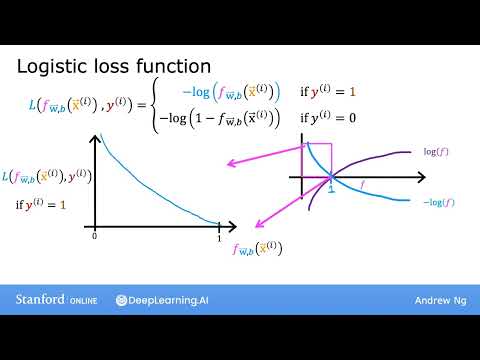
🧠 Логистическая функция и вероятности 31:23
Чтобы сделать модель обучаемой, необходимо «сгладить» дискретные решения (if-else) и перейти к непрерывным функциям. Решением становится использование логистической функции (sigmoid), которая преобразует любой логит в вероятность.
- Вероятностный подход: Классификатор теперь выдает не просто метку, а распределение вероятностей.
- Максимизация правдоподобия: Идея заключается в максимизации вероятности правильных меток в обучающей выборке.
- Логистические потери (logistic loss): Это непрерывная, дифференцируемая функция, которую можно оптимизировать с помощью градиентного спуска.
🌐 Мультиклассовая классификация и текст 53:25
Когда классов больше двух, применяются расширенные инструменты:
- Softmax: Обобщение логистической функции для вектора логитов, которое обеспечивает суммирование вероятностей всех классов в единицу.
- Cross-Entropy: Мера различия между целевым распределением (часто представленным как one-hot вектор) и предсказанным.
Отдельно лекторы затронули тему преобразования текста в тензоры. Для обучения моделей слова сначала токенизируются (превращаются в индексы), а затем кодируются в разреженные векторы. Метод «мешка слов» (bag of words) позволяет получить фиксированный размер вектора независимо от длины текста, хотя он и игнорирует порядок слов.