Инновационный подход к обучению нейросетей: Supervised Contrastive Learning 0:00
Исследователи из Google Research и MIT предложили метод Supervised Contrastive Learning (обучение с учителем на основе сопоставления), который ставит под сомнение устоявшуюся практику использования стандартной функции потерь cross-entropy (перекрестная энтропия) в глубоком обучении. Автор канала Yannic Kilcher отмечает, что, хотя авторы статьи заявляют о «новой функции потерь», по сути, речь идет о новом подходе к предварительному обучению (pre-training) классификаторов, который демонстрирует впечатляющие результаты на ImageNet.
📉 Ограничения классического подхода 2:16
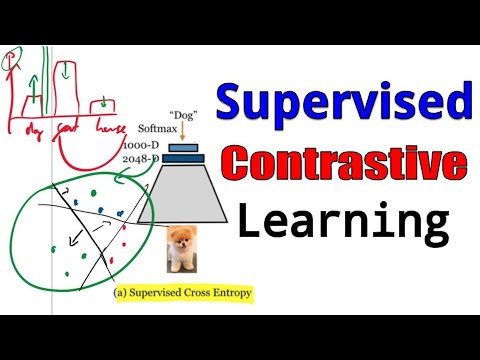
В традиционном обучении с учителем (cross-entropy training) нейросеть получает изображение, преобразует его в вектор представления (representation), который затем классифицируется с помощью линейного слоя и функции softmax.
- Принцип работы: Нейросеть минимизирует отрицательный логарифм вероятности правильного класса, одновременно максимизируя вероятность верного ответа и «выталкивая» остальные классы при нормализации распределения.
- Результат: В пространстве представлений классы разделяются гиперплоскостями, которые строит линейный классификатор. По мнению Yannic Kilcher, основная проблема здесь в том, что нейросеть «заботится» только о том, чтобы объекты оказались по нужную сторону границы принятия решения, не учитывая внутреннюю структуру самих классов.
💡 Концепция Supervised Contrastive Learning 7:34
Вместо одновременного обучения классификатора и представлений, авторы предлагают двухэтапный процесс:
- Этап предварительного обучения: Сеть учится отображать изображения одного класса максимально близко друг к другу в пространстве представлений, при этом отдаляя их от объектов других классов. Здесь не используются границы принятия решений; обучение строится на сравнении «позитивных» и «негативных» пар.
- Этап обучения классификатора: Веса представлений «замораживаются», и на них обучается только классификатор с использованием стандартной cross-entropy.
🔍 Механика Contrastive Pre-training 10:07
Метод основан на идеях самообучения (self-supervised learning), где сеть учится быть устойчивой к аугментациям (различным версиям одного и того же изображения — например, кадрированию или повороту).
- Различия с классическим contrastive learning: В обычном самообучении сеть может ошибочно «отталкивать» два изображения одного класса, если они случайно попали в разные пакеты данных (negatives). Supervised Contrastive Learning исправляет это, используя метки классов для формирования групп.
- Оптимизация: Все аугментации и оригинальные изображения одного класса «притягиваются» друг к другу, а изображения других классов «отталкиваются».
📊 Анализ эффективности и выводы 21:18
Yannic Kilcher детально анализирует градиент функции потерь и приходит к выводу, что метод фокусируется на «сложных» примерах — тех парах, которые нейросеть пока не научилась правильно распределять.
Ключевые факты о результатах:
- Стабильность: Метод показывает меньшую чувствительность к гиперпараметрам, таким как выбор оптимизатора или стратегии аугментации.
- Устойчивость к искажениям: При тестировании на наборе данных с «коррумпированными» изображениями точность падает медленнее, чем при использовании классической cross-entropy.
- Ресурсоемкость: Обучение требует огромных вычислительных мощностей, включая батч-сайзы до 8192 и использование кластеров TPU, а процесс может достигать 700 эпох.
По словам ведущего, несмотря на то что улучшение метрик на ImageNet составляет около 1%, необходимо дождаться независимой репликации результатов, так как на малых приростах точности огромное влияние могут оказывать вычислительные ресурсы и размер пакетов, а не только сама архитектура потерь.




