В машинном обучении долгое время считалось, что состязательные атаки (adversarial examples) — это досадные ошибки и баги нейросетей, неверно интерпретирующих пиксели. Однако фундаментальное исследование ученых из MIT под руководством Эндрю Ильяса (Andrew Ilyas) переворачивает это представление, доказывая, что уязвимости алгоритмов — это не программные сбои, а реальные, высокоточные признаки данных, которые просто невидимы для человека. В своем видеообзоре исследователь и блогер Янник Килчер (Yannic Kilcher) подробно разбирает эту концепцию, анализирует знаковые эксперименты авторов и высказывает долю здорового скептицизма в отношении их выводов.
🐱 Иллюзия восприятия: как обмануть нейросеть одной деталью 0:00
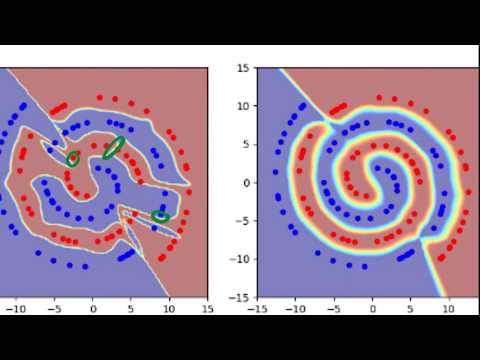
Обычная модель классификации изображений способна безошибочно определить, что на картинке изображен кот. Однако, если внести в это изображение минимальные, практически незаметные для человеческого глаза изменения — точечно скорректировать определенные пиксели — нейросеть внезапно заявит, что перед ней собака, самолет или небо. Такие модифицированные изображения называют состязательными примерами (adversarial examples).
До публикации обсуждаемой работы истинные причины повсеместного существования подобных уязвимостей оставались неясными. Авторы исследования выдвигают гипотезу: состязательные атаки напрямую связаны с наличием в данных «неробастных признаков» (non-robust features).
Согласно определению исследователей, эти признаки представляют собой:
- Закономерности в распределении данных, которые обладают высокой предсказательной силой.
- Математически точные, но при этом крайне хрупкие структуры.
- Элементы, абсолютно непонятные и невидимые для восприятия человека.
👁️ Кот или собака: почему нейросети «видят» направление шерсти 2:06
Чтобы объяснить разницу между восприятием человека и машины, Янник Килчер приводит наглядную аналогию с котами и собаками. Люди классифицируют живые объекты по крупным, устойчивым макропризнакам: форме ушей, расположению глаз, наличию усов и их взаимному геометрическому соотношению.
Однако в обучающей выборке могут присутствовать и другие закономерности. В гипотетическом сценарии, предложенном ведущим, у всех котов на изображениях шерсть направлена строго горизонтально, а у собак — вертикально. Человек не обратит на это внимания, но сверточная нейросеть (CNN), работающая через локальные операторы соседства пикселей, с огромной вероятностью ухватится именно за этот микропаттерн. Ей математически проще выучить направление ворса, чем сложные пространственные связи между ушами и глазами.
Если изменить направление шерсти на картинке с собакой, для человека она останется собакой. Но для модели, завязавшей свое решение на этот микропаттерн, изображение мгновенно превратится в кота.
Авторы статьи утверждают, что состязательные примеры возникают именно потому, что алгоритмы находят такие незаметные для нас, но реальные и полезные с точки зрения статистики признаки. Уязвимость моделей — это прямой результат их чувствительности к хорошо обобщающим закономерностям в данных.
📊 Математическая модель: полезность и робастность 7:43
Для строгого доказательства авторы формализуют понятия в рамках бинарной классификации, где целевые метки равны $+1$ или $-1$. Признаком называют математическое представление на последнем слое нейросети перед линейным классификатором (логистической регрессией).
Исследователи разделяют признаки на две категории:
- Полезные признаки (useful features). Признак $F$ считается полезным, если его математическое ожидание произведения с истинной меткой класса выше определенной константы, то есть когда он высоко коррелирует с правильным ответом. Модель извлекает только такие признаки, так как иные не помогают решать задачу.
- Робастные и неробастные признаки (robust and non-robust features). Робастный признак сохраняет высокую корреляцию с классом даже в том случае, если изображение подвергается состязательному искажению из заданного множества $\Delta$. Пример робастных признаков — взаимное положение глаз и ушей кота, которое нельзя изменить малой флуктуацией пикселей. Неробастный признак (например, микротекстура шерсти) при минимальном целенаправленном сдвиге полностью теряет свою полезность для классификации.
🧪 Разделение реальности: три знаковых эксперимента MIT 15:20
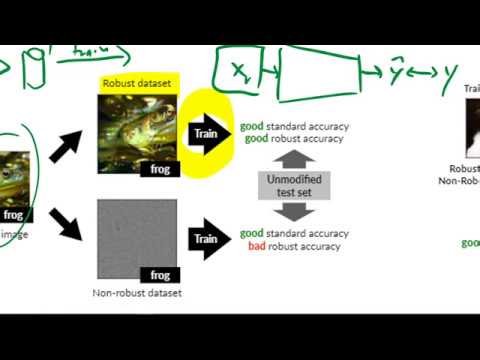
Чтобы подтвердить свою гипотезу, ученые провели серию экспериментов. Используя специальную процедуру, они разделили исходный обучающий датасет на две независимые модифицированные версии.
В рамках первого эксперимента стандартную нейросеть обучили на датасете, содержащем исключительно робастные признаки. Результаты оказались примечательными:
- Модель показала отличную стандартную точность (standard accuracy) на обычном, немодифицированном тестовом наборе.
- Она продемонстрировала высокую робастную точность (robust accuracy) против состязательных атак.
Это доказывает, что без неробастных признаков в обучении модель физически не может их использовать, а значит, становится неуязвимой для атак, которые их эксплуатируют.
Во втором экспериментальном сценарии сеть обучили на датасете, где остались только неробастные признаки. Модель снова показала высокую точность на стандартном тестовом наборе, что подтверждает: эти невидимые человеку микропаттерны действительно отлично обобщают данные. Однако робастность такой сети ожидаемо оказалась крайне низкой.
Третий, наиболее изящный эксперимент задействовал «перевернутые» метки. Исследователи взяли изображение собаки и создали состязательный пример в сторону класса «кот». В итоге робастные признаки кричали, что это собака, а неробастные — что это кот. Модели присвоили ложную обучающую метку «кот».
Собрав такой датасет, где ложные неробастные признаки всегда соответствовали указанной метке, а честные робастные — противоречили ей, авторы обучили стандартную сеть. При тестировании на обычных, чистых изображениях котов (где и робастные, и неробастные признаки указывают на кота), эта сеть безошибочно определяла кота. Это произошло вопреки тому, что в процессе обучения она видела под меткой «кот» исключительно модифицированные изображения других объектов.
🛠️ Как разобрать картинку на атомы: методология синтеза 26:47
Для создания очищенных датасетов авторы применили оригинальные подходы оптимизации. На примере картинок из набора CIFAR-10 Янник Килчер демонстрирует судно, очищенное до робастных признаков, и лося, который из-за наложенных неробастных паттернов кажется нейросети кораблем.
Процесс синтеза робастной версии данных выглядит следующим образом:
- Используется уже обученная робастная модель, полученная стандартным методом состязательного обучения.
- Берется исходное изображение $X$, пропускается через эту сеть, и фиксируется её вектор признаков $G(X)$.
- Создается новое изображение $X'$, изначально заполненное случайным шумом.
- С помощью градиентного спуска и обратного распространения ошибки пиксели шума меняются так, чтобы вектор признаков $G(X')$ максимально приблизился к $G(X)$.
Поскольку робастная модель по определению реагирует только на устойчивые признаки, итоговое изображение $X_R$ перенимает от оригинала исключительно их, полностью игнорируя фоновый неробастный шум. Создание неробастной версии происходит значительно проще — через классический алгоритм генерации состязательных примеров, где к картинке одного класса подмешиваются микропаттерны другого.
🤨 Ложка дегтя: скептицизм и критика методологии 32:57
Несмотря на элегантность исследования, Янник Килчер высказывает серьезные критические замечания к работе ученых из MIT.
По мнению ведущего, в первом экспериментальном сценарии присутствует логическая уловка: для извлечения робастных признаков и создания очищенного датасета авторам уже необходим готовый робастный классификатор, обученный состязательным методом. Килчер утверждает, что такой подход фактически «тайком проносит» состязательное обучение внутрь всей процедуры. Высокая робастность новой модели — это лишь зеркальное отражение свойств той сети, с помощью которой генерировались данные.
Вторая претензия блогера носит концептуальный характер. Янник Килчер полагает, что данная теория не решает проблему состязательных примеров, а лишь переформулирует её в терминах признаков. Она констатирует наличие неробастных паттернов, но не объясняет, почему они возникают, как именно нейросети за них цепляются и как бороться с уязвимостями без предварительного владения робастной моделью.
По словам Килчера, авторы просто перенесли проблему из плоскости архитектуры классификаторов в плоскость геометрии датасетов, оставив многие ключевые вопросы открытыми.
📐 Геометрический парадокс: почему теории расходятся с практикой 37:04
В финальной части работы авторы приводят теоретический анализ на примере упрощенного распределения данных (гауссиан). В этой абстрактной модели классы разделены линейной границей.
Проблема заключается в фундаментальном несовпадении геометрий:
- Геометрия данных: реальные примеры распределены в пространстве определенным образом, имея свои средние значения и ковариации.
- Геометрия атак: состязательные примеры определяются как сдвиг на небольшое расстояние в любом произвольном направлении (в рамках гиперсферы ограниченного радиуса).
Из-за этого всенаправленного свойства атаки всегда находят траектории, где разделяющая граница классов оказывается критически близко к точке данных. Состязательное обучение принудительно расширяет границы классов за счет добавления атакованных примеров, смещая разделяющую гиперплоскость и выравнивая геометрию модели с геометрией потенциальных угроз.