Революция в классификации: Supervised Contrastive Learning 0:00
Исследователи из Google Research и MIT представили работу, в которой предлагают заменить традиционную функцию потерь (loss function) при обучении нейронных сетей — кросс-энтропию (cross-entropy) — на новый метод под названием Supervised Contrastive Learning (обучение с учителем на основе контраста). Это смелое утверждение: поскольку кросс-энтропия является стандартом де-факто в глубоком обучении, потенциальная замена может перевернуть всю область.
По словам ведущего обзора Янника Килчера (Yannic Kilcher), новый метод показывает результаты, превосходящие современный уровень техники (SOTA) при использовании стандартных техник аугментации данных, таких как AutoAugment и RandAugment. В тестах на ImageNet, самом известном бенчмарке компьютерного зрения, данный подход улучшает точность классификации примерно на 1% — для этой области это значительный прорыв.
🧠 Почему не кросс-энтропия? 2:16
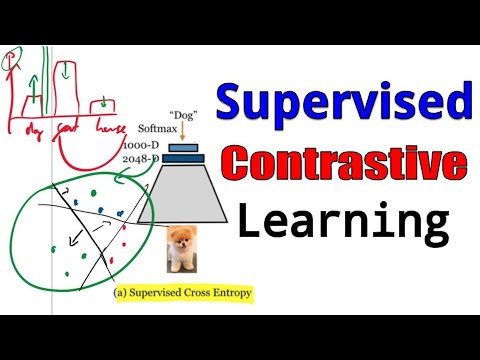
В классическом обучении с учителем при использовании кросс-энтропии процесс выглядит следующим образом:
- Изображение проходит через нейронную сеть, создавая векторное представление (representation).
- Это представление подается в классификационный слой с функцией Softmax.
- На выходе получается распределение вероятностей по классам.
Цель кросс-энтропии — максимизировать вероятность правильного класса и минимизировать вероятности всех остальных, что фактически «толкает» правильный класс вверх, а неправильные — вниз. Янник Килчер отмечает, что такая модель фокусируется исключительно на том, чтобы разделить классы линейной границей в пространстве признаков. При этом, если сеть обучена плохо, она будет активно «толкать» образцы через границу принятия решения, пытаясь исправить ошибки.
🔍 Суть Supervised Contrastive Learning 7:34
Авторы исследования предлагают разделить обучение на два этапа. Идея заключается в том, чтобы сначала научить сеть создавать качественные представления, а затем сделать задачу классификации максимально простой.
- Этап 1 (Предобучение): Сеть учится «сближать» в пространстве признаков изображения одного класса и «раздвигать» изображения разных классов, не заботясь напрямую о границах классификации.
- Этап 2 (Классификация): Веса сети «замораживаются», и обучается только финальный классификационный слой с использованием обычной кросс-энтропии.
Янник Килчер объясняет, что в отличие от самообучения (self-supervised learning), где метки классов отсутствуют и модель может случайно «раздвинуть» изображения одного класса (потому что не знает, что они принадлежат к одной категории), здесь метки являются ключевым элементом. В объектив попадают все примеры из одного мини-батча, относящиеся к тому же классу, и все они «притягиваются» друг к другу, тогда как всё остальное — отталкивается.
📉 Анализ градиентов и стабильность 21:18
Авторы работы провели детальный анализ градиентов своей функции потерь. Янник Килчер подметил, что их метод фокусируется на «сложных» примерах — тех, где сеть еще не научилась правильно выравнивать представления. Он отмечает, что это поведение во многом напоминает работу кросс-энтропии, которая также перестает активно «тянуть» градиенты для образцов, которые сеть уже классифицирует уверенно.
Ключевые преимущества метода, выделенные авторами:
- Гиперпараметрическая стабильность: при смене аугментаций или оптимизаторов точность модели остается более стабильной, чем при использовании кросс-энтропии.
- Устойчивость к искажениям: на «испорченном» (corrupted) наборе ImageNet точность модели с новой функцией потерь падает медленнее.
⚖️ Скептицизм эксперта 28:37
Несмотря на заявленные успехи, Янник Килчер призывает к осторожности в оценках. Во-первых, он указывает на огромные затраты вычислительных ресурсов: авторы использовали размеры мини-батчей до 8192 и обучали модели до 700 эпох, что требует мощностей уровня TPU-кластера. Во-вторых, эксперт считает, что 1% прироста на ImageNet может быть обусловлен не столько самой функцией потерь, сколько именно огромным объемом вычислений и качеством настройки гиперпараметров.
По мнению Килчера, прежде чем считать этот подход новой парадигмой для всего глубокого обучения, необходимо увидеть его репликацию независимыми исследователями в различных условиях.




