В очередном выпуске подкаста Machine Learning Street Talk ведущий Тим Скарфе вместе со специалистом в области искусственного интеллекта Аравиндом Сринивасом обсуждают революционный алгоритм CURL, меняющий подход к обучению с подкреплением. В центре внимания исследователей — переход от классического обучения на основе наград или ручной разметки к контрастивному самообучению (contrastive self-supervised learning), способному извлекать глубокие семантические связи напрямую из сырых пикселей. Участники беседы подробно разбирают историю развития технологий компьютерного зрения, ограничения современных нейросетевых архитектур и то, почему универсальный ИИ невозможно построить без прочного фундамента из неразмеченных данных.
🚀 Парадигма контрастивного обучения: Меньше реконструкции, больше смысла 0:00
Контрастивное обучение представляет собой изящный и лаконичный подход к обработке информации нейросетями, который сводится к фундаментальному вопросу: являются ли два сигнала одинаковыми или разными. Тим Скарфе подчеркивает, что способность алгоритма проводить различия между объектами оказывается гораздо важнее и эффективнее для формирования репрезентаций, чем полная попиксельная реконструкция исходных данных.
По мнению ведущего, эпоха жесткого контроля над обучением машин уходит в прошлое, поскольку ручное указание признаков искусственно ограничивает репрезентативную емкость моделей и мешает им эффективно усваивать как глобальные, так и локальные паттерны. Самообучение (self-supervised learning) снимает эти ограничения, открывая доступ к практически бесконечным объемам самостоятельно генерируемых данных.
В ретроспективе развития этой технологии Тим Скарфе выделяет модель Skip-gram, предложенную Томашем Миколовым в 2013 году для обработки естественного языка в рамках проекта Word2Vec. Первоначальная версия этого алгоритма использовала вычислительно ресурсоемкую функцию Softmax поверх всего словаря, однако Миколов применил изящный трюк — контрастивный вывод с негативным семплированием (negative sampling). В этой схеме положительным примером выступали слова, находящиеся в одном контексте, а негативным — случайные слова из корпуса, что позволило эффективно проецировать лексемы в геометрическое пространство сходства без ручной разметки.
Перенос этой концепции в сферу компьютерного зрения оказался более сложной задачей, где важными вехами стали несколько ключевых этапов:
- Использование функции Triplet Loss в архитектуре FaceNet, требовавшей одновременного вычисления расстояний между анкором, позитивным и негативным примерами.
- Разработка специальных стратегий майнинга примеров (mining strategy) для ускорения сходимости алгоритма за счет поиска максимально несхожих позитивных пар.
- Применение аугментации данных в качестве сложной задачи для самообучения, предложенное Девоном Хьелмом в работе по Deep Infomax.
Современные фреймворки SimCLR и MoCo развили эту идею до уровня дискриминации на уровне целых экземпляров (instance-level discrimination). Алгоритм получает множество случайно измененных фрагментов изображения и решает задачу самообучения: принадлежат ли эти вырезанные части одному и тому же исходному кадру. По мнению Тима Скарфе, поразительным результатом этих изысканий стало то, что беспрецедентные подходы без учителя начали давать репрезентации более высокого качества, чем классическое обучение с учителем.
🧠 Кризис эффективности данных и архитектура CURL 3:29
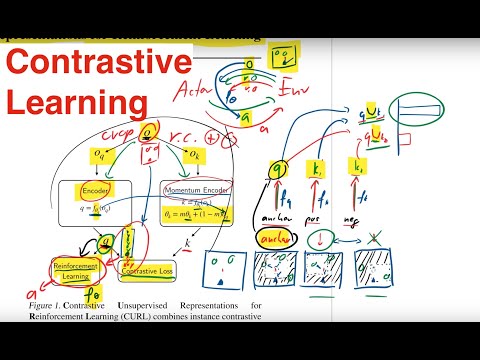
Главным предметом обсуждения стала научная работа Аравинда Сриниваса и его коллег под названием CURL (Contrastive Unsupervised Representations for Reinforcement Learning). Этот алгоритм демонстрирует передовые результаты (state-of-the-art) при игре в классические игры Atari, обучаясь исключительно на основе визуального потока пикселей. Ключевая ценность CURL заключается в радикальном решении проблемы эффективности выборки (sample efficiency). Вместо погони за асимптотической производительностью на рубеже в миллионы итераций, исследователи сфокусировались на метрике «anytime performance» на отметке всего в 100 тысяч шагов среды. По словам Тима Скарфе, именно низкая эффективность выборки — необходимость в миллионах симуляций для сходимости — до сих пор блокирует коммерческое развертывание систем обучения с подкреплением (RL) в реальном физическом мире.
Аравинд Сринивас, успевший поработать интерном в DeepMind, войти в технический штат OpenAI и пройти докторантуру в Беркли под руководством Питера Аббила, отмечает, что концепция CURL выросла из его предыдущих исследований. В составе команды DeepMind он работал над проектом CPC (Contrastive Predictive Coding), где удалось повысить эффективность распознавания изображений на ImageNet на 50–80% за счет предварительного обучения на неразмеченных данных с последующей тонкой настройкой. По мнению гостя, повышение эффективности выборки в 10 или 100 раз — это самый важный вызов для современного ИИ.
По словам Аравинда Сриниваса, если оптимизировать только функцию вознаграждения или предсказывать метки классов, модель не узнает о структуре данных практически ничего по сравнению со сценарием, когда она пытается осмыслить raw-пиксели или сырые наблюдения.
Исторически попытки внедрить вспомогательные задачи (auxiliary tasks) для ускорения RL уже предпринимались. Примером служит архитектура UNREAL (Unsupervised Reinforcement and Auxiliary Tasks), представленная Максом Джадербергом из DeepMind несколько лет назад. Однако UNREAL полагалась на автоэнкодеры и усложненные механизмы попиксельного предсказания будущих кадров. Архитектура CURL полностью отказывается от ресурсоемкой реконструкции пикселей в пользу контрастивного лосса, что делает ее внедрение весьма простым. Для интеграции CURL в любой существующий RL-пайплайн требуется написать всего несколько строчек кода.
⚖️ Модели без модели против World Models: Дискуссия о честности бенчмарков 10:24
В ходе дискуссии Тим Скарфе затронул исторический аспект тестирования алгоритмов, отметив, что первые публикации DeepMind не содержали прямого сравнения эффективности обучения на сырых пикселях и на чистых физических состояниях среды. Аравинд Сринивас пояснил, что во времена создания UNREAL эталонных сред вроде DeepMind Control Suite еще не существовало. Исследователи прошлого оперировали в парадигме обучения длиною в 200 миллионов шагов, стремясь к максимальным итоговым показателям производительности, а не к скоростному обучению за 100 тысяч шагов.
Участник беседы Коннор выразил сомнение в методологической корректности сравнения алгоритмов на жестком лимите в 100 тысяч шагов. По его мнению, когда в системе присутствуют модели мира (World Models) со скрытыми вариационными автоэнкодерами (как в алгоритмах PlaNet или Dreamer), они могут генерировать и прокручивать виртуальные траектории внутри латентного пространства. Коннор считает, что прямое сопоставление таких подходов со строго безмодельными (model-free) алгоритмами вроде CURL, где каждый шаг взаимодействия происходит в реальной среде, выглядит не совсем честным.
Аравинд Сринивас частично согласился с этим аргументом, признав, что от моделей на основе структуры мира ожидается более высокая базовая эффективность. Однако он указал на фундаментальные недостатки таких систем:
- Модели мира вносят колоссальный уровень архитектурной сложности в рабочий пайплайн.
- Инженеру приходится эмпирически определять глубину горизонта планирования и предсказания будущего в латентном пространстве.
- Несмотря на отсутствие прокрутки траекторий во времени, безмодельный CURL демонстрирует результаты лучше, чем PlaNet или Dreamer.
По прогнозам Аравинда, как только в CURL будут интегрированы механизмы временного прогнозирования, этот алгоритм продемонстрирует еще более впечатляющий отрыв по скорости и качеству обучения.
🧩 Секрет бесконфликтного градиента в мультизадачной оптимизации 13:56
Коннор поднял важную проблему многоцелевой оптимизации, поинтересовавшись, не возникает ли в CURL деструктивного конфликта градиентов. В процессе работы алгоритма энкодер одновременно получает обновления от градиентов RL (например, алгоритма Soft Actor-Critic) и от лосс-функции импульсного контрастивного кодировщика (MoCo) — не тянут ли эти задачи общие веса сети в противоположные стороны?
Аравинд Сринивас дал развернутый ответ, объяснив стабильность CURL математической природой контрастивного лосса. По его словам, этот лосс эквивалентен задаче классификации со множеством классов (cross-entropy), где функция потерь строго ограничена, предсказуема и ведет себя крайне стабильно. Она органично сосуществует с лоссом обучения с подкреплением. Совершенно иная картина наблюдается при попиксельной реконструкции среды:
- При среднеквадратичном лоссе (MSE) на высоких разрешениях (например, кадрах 84x84) количество деталей становится огромным.
- Лосс реконструкции пикселей начинает полностью доминировать над градиентами обучения с подкреплением.
- Инженерам приходится вводить сложные мета-гиперпараметры для ручной балансировки этих сил, как это сделано в SAC+AE, PlaNet или Dreamer.
В CURL какие-либо коэффициенты балансировки отсутствуют в принципе; задачи гармонично дополняют друг друга без ручной настройки. Аравинд Сринивас вывел общее правило для проектирования ИИ-систем: чем ближе вспомогательная функция потерь к классической контролируемой классификации, тем проще и стабильнее становится жизнь инженера при многоцелевой оптимизации.
🎨 Информационная избыточность против прагматизма: Почему пиксели врут 17:46
Тим Скарфе выдвинул концептуальное возражение: лосс классификации по своей сути содержит на порядки меньше информации, чем детальная реконструкция каждого пикселя кадра. Логично предположить, что восстановление картинки целиком должно давать более богатые и насыщенные репрезентации для агента.
Аравинд Сринивас опроверг это предположение, заявив, что ценность репрезентации определяется не количеством битов, поскольку не все биты в физическом мире равны между собой. В симуляциях Atari или задачах контроля MuJoCo (например, Walker или HalfCheetah) присутствует огромное количество визуального шума — текстура пола, узоры заднего фона, цвет неба. Эти элементы никак не помогают агенту решить конкретную задачу управления.
По словам исследователя, задача попиксельного предсказания не знает, что важно, а что нет, поэтому она будет тратить колоссальную емкость сети на то, чтобы идеально воссоздать каждый пиксель бэкграунда.
Контрастивное обучение, по мнению Аравинда, успешно обошло эту фундаментальную проблему, став главным достижением в области Unsupervised Learning. Оно заставляет сеть естественным образом фокусироваться на высокоуровневых семантических объектах — например, на конечностях робота или геометрии препятствий, игнорируя фоновую структуру.
В ответ на вопрос Тима о роли аугментаций (таких как случайное кадрирование — random crop) Аравинд согласился, что без закладывания базовых инвариантов в данные добиться эффективности выборки невозможно. Случайный кроп является локомотивом успеха в ImageNet или задачах сегментации COCO. Однако этот метод жестко привязан к домену компьютерного зрения; в обработке текста (NLP) адекватные аугментации подобрать крайне сложно, поэтому там до сих пор доминируют подходы пространственно-временного предсказания в стиле CPC.
⏱️ Временная связность и преодоление «мошенничества» моделей 23:51
Участник дискуссии Коннор напомнил шутку Тима Скарфе о том, что текстовый контрастивный лосс можно было бы создать, вырезая случайные абзацы из статьи и проверяя, принадлежат ли они одному документу. В связи с этим он спросил, какова роль временных последовательностей в формировании пар (например, когда кадры $t-1$ и $t+1$ объявляются позитивными, а все остальные кадры из истории — негативными) по сравнению с обычной пространственной аугментацией.
Аравинд Сринивас твердо убежден, что для достижения передовых результатов необходимо сочетать оба подхода. В их совместном с DeepMind исследовании по CPC v2 пространственно-временное предсказание (когда верхние паттерны изображения предсказывали нижние) работало эффективно только при параллельном включении жесткой аугментации данных. Гость объясняет этот феномен следующими причинами:
- Если использовать исключительно временную последовательность соседних кадров, объем разделяемой информации между ними окажется слишком высоким.
- Модель мгновенно находит лазейки и начинает «жульничать» (cheating), сопоставляя тривиальные признаки вроде общей освещенности или статического шума.
- Сеть перестает извлекать глубокие концептуальные признаки объектов.
Поэтому даже в потенциальных временных модификациях CURL аугментация останется критически важным элементом, барьером, не позволяющим нейросети скатываться в тривиальное запоминание. Тим Скарфе добавил, что в задачах RL классическое допущение о независимости и одинаковой распределенности данных (IID) полностью нарушается из-за жесткой корреляции между последовательными кадрами среды.
📊 Парадокс разметки: Почему беспилотники и роботы отказываются от человеческих лейблов 30:26
Тим Скарфе попросил гостя раскрыть интуитивные причины того, почему фреймворки типа SimCLR внезапно начали демонстрировать выдающиеся результаты на ImageNet. Аравинд Сринивас разложил эволюцию успеха самообучения по трем академическим метрикам:
- Линейная классификация (Linear Classification): веса предобученной модели замораживаются, а сверху обучается простой линейный слой. Всего за один год точность на этом тесте взлетела с 55% до 77%. Проект CPC v2 достиг 71% в декабре, после чего MoCo и SimCLR подняли планку еще выше.
- Перенос обучения (Transfer Learning): проверка качества репрезентаций на сторонних задачах с дефицитом данных, например, детекции объектов Pascal VOC. Исторически считалось, что обучение без учителя всегда уступает обучению со стопроцентной разметкой. Профессор Беркли Алексей Эфрос даже заключил знаменитое пари («Gelato bet») с пионером компьютерного зрения Джитендрой Маликом, утверждая, что самообучение никогда не догонит классический supervised-подход. Выход MoCo и CPC v2 окончательно закрыл этот спор — обучение без учителя впервые превзошло результаты человеческой разметки.
- Тонкая настройка (Fine-tuning): модель сначала обучается без учителя на всем массиве картинок, а затем дообучается с использованием меток классов. Пайплайн «предобучение + fine-tuning» из статьи CPC v2 показал точность 83,2% Top-1 на ImageNet, сокрушив стандартное обучение с учителем, показавшее лишь 80%.
По мнению Аравинда, для коммерческих компаний и стартапов это открывает колоссальные горизонты, ведь объем неразмеченных данных в реальном бизнесе (например, в Facebook или Google) часто в 100 раз превышает объемы того, что физически способна разметить команда людей. Платой за такой прорыв становится время вычислений: модели вроде SimCLR требуют обучения в течение 1000 эпох (против 90 эпох у классических сетей), а также экстремального масштабирования ширины и глубины слоев (например, четырехкратное увеличение ширины ResNet-50).
🤖 Пиксельный универсализм: Конец эпохи ручного проектирования роботов 42:31
Коннор задал вопрос о целесообразности ухода от векторов физического состояния среды (таких как угловые скорости суставов или позиции конечностей в симуляторах OpenAI Gym) в сторону сырых картинок. По его мнению, инженеру зачастую не составляет труда повесить несколько дополнительных датчиков на реального робота, чтобы получить чистые телеметрические данные.
Аравинд Сринивас решительно не согласился с такой позицией, выдвинув два сильных контраргумента. Во-первых, сырые пиксели с камер представляют собой универсальный, простой интерфейс ввода, одинаковый для сотен совершенно разных роботов, выполняющих разнородные задачи в различных средах. Камера позволяет обучать единую, глобальную визуальную репрезентацию для всего парка устройств. Во-вторых, сверточные нейросети (CNN) структурно намного эффективнее поддаются оптимизации, чем многослойные перцептроны (MLP), работающие с векторами состояний. CURL, оперирующий пикселями, на ряде бенчмарков превосходит по эффективности алгоритмы, имеющие прямой доступ к физическим координатам среды.
Гость подчеркнул, что ручное проектирование признаков (domain engineering) делает системы хрупкими и зависимыми от конкретных условий:
«Если в задаче Reacher вы передадите относительные расстояния вместо абсолютных или синусоиды углов суставов вместо самих углов, MLP заработает гораздо быстрее. Но мы не хотим заниматься этим ручным инжинирингом для каждой новой задачи. Дайте модели пиксели — она сама найдет всю необходимую информацию».
При этом Аравинд честно обозначил текущие лимиты CURL: на сверхсложных динамических задачах вроде HalfCheetah, Humanoid или Acrobot алгоритм пока отстает от state-based аналогов. Причина кроется в банальном ограничении текущей архитектуры — стек из 4 кадров и компактная CNN физически не могут восстановить скрытые производные динамики (скорости и ускорения). Переход на обработку условных 100 кадров вглубь истории должен полностью снять эту проблему.
📐 Пределы сверток и будущее трансформеров в управлении 49:31
Тим Скарфе перевел дискуссию в русло фундаментальной критики сверточных сетей. По его мнению, CNN обладают врожденными ограничениями: они осуществляют исключительно локальную обработку информации, поддерживают только плоские многообразия и не способны улавливать долгосрочные иерархические зависимости в данных, с чем великолепно справляются архитектуры трансформеров.
Аравинд Сринивас разделил это беспокойство, пояснив, что для распространения глобального контекста в CNN требуется нагромождать колоссальное количество слоев. Кроме того, свертки лишены механизмов мультипликативного взаимодействия, которые лежат в основе связок Query-Key-Value в трансформерах и создают репрезентации высшего порядка. Однако лобовое внедрение трансформеров в компьютерное зрение упирается в непреодолимый барьер вычислительной сложности $O(L^2)$ — сеть невозможно заставить обсчитывать внимание каждого пикселя ко всем остальным на длинных видеозаписях.
Коннор привел в пример архитектуры Self-Attention GAN (SAGAN) и BigGAN, где слои self-attention успешно внедряются между сверточными картами признаков. Аравинд детализировал этот пример, отметив, что в BigGAN внимание включается только после того, как сверточные слои жестко понизят разрешение картинки (даунсемплинг) с исходных высоких разрешений до уровня 64x64 или 32x32 пикселей. Работать со сгенерированной сеткой токенов напрямую из разрешений 512x512 современное железо не способно.
Гость подытожил, что на данный момент в индустрии ИИ попросту не создано канонического, ультраэффективного сочетания внимания и сверток (аналога ResNet или DenseNet), из-за чего применение трансформеров в робототехнике и RL пока остается слабо изученным полем.
🎂 Метафора торта ЛеКуна: Обучение с подкреплением как вишенка на десерте 1:04:04
Ближе к финалу интервью Тим Скарфе процитировал недавние заявления Яна ЛеКуна о том, что самообучение является главным фронтиром машинного обучения на ближайшие годы. Аравинд Сринивас напомнил присутствующим знаменитую кулинарную метафору ЛеКуна («The LeCun Cake»), сформулированную еще в 2016 году:
- Если представить человеческий интеллект в виде роскошного торта, то его основой и самим тестом является контрастивное самообучение (Unsupervised Learning).
- Сладкая глазурь поверх торта — это обучение с учителем (Supervised Learning).
- Маленькая вишенка на самой вершине десерта — это обучение с подкреплением (Reinforcement Learning).
Аравинд полностью разделяет эту концепцию, подчеркивая, что объем полезной информации, извлекаемый моделью из плотного контрастивного лосса, несопоставим со скудным, разреженным сигналом классического вознаграждения в RL. По его убеждению, парадигма «предобучи торт, затем добавь вишенку» станет доминирующей в управлении роботами, независимо от того, сколько наград или экспертных траекторий доступно инженеру.
В качестве идеального полигона для обкатки этих идей Аравинд видит индустрию беспилотного вождения. Коммерческие компании обладают терабайтами видеозаписей с дорог, на которых можно провести масштабное предварительное видео-контрастивное обучение, а затем точечно дообучить сеть распознавать пешеходов, знаки и выбирать оптимальные траектории движения. Такой подход будет на голову выше классического supervised-подхода.
В завершение Тим Скарфе со смехом вспомнил, как на одной из вечеринок Facebook в рамках конференции NeurIPS в Ванкувере организаторы выставили на десертный стол реальный, физический торт, в точности повторяющий схему ЛеКуна. Аравинд добавил, что Нью-Йоркский университет (NYU) заказывал аналогичный торт на празднование вручения ЛеКуну престижнейшей премии Тьюринга. По мнению собеседников, несмотря на элемент поп-науки, эта метафора идеально отражает фундаментальное устройство систем ИИ будущего.
🎓 От Дели до Беркли: Путь Аравинда Сриниваса в авангард ИИ 1:08:47
Тим Скарфе поинтересовался личной историей Аравинда и тем, как ему удалось накопить столь глубокую экспертизу в относительно молодом возрасте. Путь Аравинда в Machine Learning стартовал примерно в 2016 году во время учебы в Индийском институте технологий в Мадрасе (IIT Madras) — одном из ведущих инженерных вузов страны. Его университетский профессор оказался учеником Эндрю Барто, легендарного ученого, считающегося одним из отцов-основателей теории обучения с подкреплением.
Именно он направил молодого студента заниматься RL в тот самый момент, когда DeepMind взрывала заголовки своими первыми статьями по глубокому обучению. Аравинд признается, что сутками напролет разбирал и воспроизводил архитектуры DQN, DDQN и Dueling DQN.
Этот мощный задел позволил ему поступить в аспирантуру Калифорнийского университета в Беркли к Питеру Аббилу — признанному мировому авторитету в области робототехники. В Беркли Аравинд вместе с коллегами создал и на протяжении нескольких лет вел специализированный курс «Глубокое обучение без учителя» (CS 294-158). Исследователь делится главным лайфхаком:
«Лучший способ по-настоящему освоить сложную тему — это попытаться обучить ей других. Вы просто физически не сможете читать лекции, пока сами досконально не разберетесь в математике и не имплементируете каждую генеративную модель своими руками».
За годы докторантуры Аравинд прошел серию знаковых стажировок. В OpenAI он работал плечом к плечу с Джоном Шульманом над алгоритмами PPO, параллельно наблюдая за тем, как Алек Рэдфорд создавал первую версию революционной текстовой модели GPT-1. Именно успехи OpenAI окончательно убедили Аравинда переключиться из классического RL в сторону Unsupervised Learning.
Позже, стажируясь в DeepMind, он работал с Аароном ван ден Оордом (изобретателем CPC, WaveNet и VQ-VAE), став соавтором фундаментальной статьи CPC v2. В планах исследователя на ближайшее будущее — полная концентрация на генеративных моделях и самообучении, чтобы превратить теоретический «торт» ЛеКуна в надежную рабочую технологию для роботов реального мира.