Современные нейросети добились впечатляющих успехов во многих областях, но возникает фундаментальный вопрос: почему они должны быть именно «глубокими»? Эндрю Ын (Andrew Ng), основатель DeepLearning.AI и один из самых авторитетных экспертов в области ИИ, подробно объясняет, как иерархическая структура из множества скрытых слоев позволяет компьютерам понимать мир — от распознавания лиц до человеческой речи.
👁️ Иерархия визуальных образов: от линий к лицам 0:13
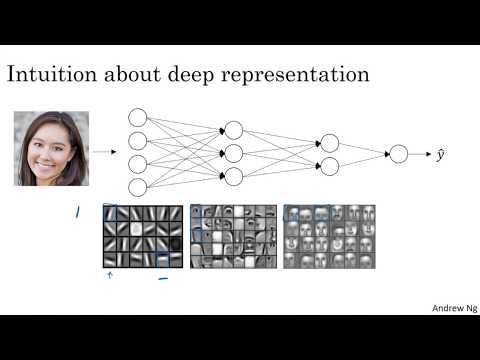
При построении системы распознавания или детекции лиц глубокая нейросеть выполняет последовательную декомпозицию изображения. Как утверждает Эндрю Ын, этот процесс можно представить как поэтапное усложнение визуальных функций :
- Первый уровень (Детектор краев): На входе нейросеть получает изображение лица. Первый скрытый слой работает как «детектор признаков» или «детектор краев». Если визуализировать работу первого слоя с 20 скрытыми юнитами (нейронами), можно увидеть, что каждый из них ищет на картинке края определенной ориентации — вертикальные, горизонтальные или наклонные линии .
- Второй уровень (Части лица): Группируя обнаруженные края, второй слой начинает формировать более сложные структуры. Здесь отдельные нейроны специализируются на поиске конкретных частей лица: глаз, носов, ушей или подбородков .
- Третий уровень (Целостные образы): Объединяя информацию о частях лица, последующие слои обучаются распознавать или определять различные типы лиц в целом .
Ын подчеркивает, что интуитивно это можно понимать так: ранние слои вычисляют простейшие функции, а более глубокие — компонуют их для обучения гораздо более сложным задачам . Важной технической деталью является то, что детекторы краев анализируют очень маленькие области изображения, в то время как детекторы лиц могут охватывать гораздо более обширные зоны .
🗣️ Распознавание речи: звуковая пирамида 3:05
Аналогичный принцип иерархического представления (композиционного представления) применим и к другим типам данных, например, к аудио. Хотя визуализировать звук сложнее, Ын описывает процесс распознавания речи следующим образом :
- Низкоуровневые признаки: Первый уровень нейросети может обучаться детектировать базовые характеристики аудиоволны: идет ли тон вверх или вниз, является ли звук белым шумом, свистящим или имеет определенную высоту тона.
- Фонемы: Группируя эти волновые признаки, сеть учится распознавать базовые единицы звука, которые в лингвистике называются фонемами. Например, в слове «cat» (кот) сеть выделяет звуки «к», «э» и «т» .
- Слова и фразы: На следующих уровнях нейросеть объединяет фонемы в слова, а слова — в целые фразы и предложения .
Таким образом, по словам лектора, глубокая сеть способна превращать простые входные данные в удивительно сложные результаты, такие как понимание человеческого языка .
🧠 Биологическая аналогия и ее опасности 4:39
В сообществе специалистов по ИИ часто проводят параллели между глубокими нейросетями и человеческим мозгом. Нейробиологи полагают, что мозг также начинает обработку визуальной информации с детектирования простых вещей, таких как края, и постепенно переходит к сложным объектам .
Однако Эндрю Ын призывает к осторожности в этом вопросе. По его мнению, аналогии между глубоким обучением и биологическим мозгом иногда могут быть «немного опасными» . Тем не менее он признает, что в этом сравнении есть большая доля правды, и именно принципы работы человеческого зрения послужили источником вдохновения для развития некоторых аспектов глубокого обучения .
🔢 Математическое обоснование: теория схем 5:31
Помимо интуитивного понимания иерархии, существует строгое математическое обоснование пользы глубоких представлений, пришедшее из теории схем. Эта теория изучает, какие типы функций можно вычислить с помощью логических вентилей (AND, OR, NOT) .
Как утверждает Эндрю Ын, существуют функции, которые можно вычислить с помощью относительно небольшой, но глубокой нейросети. Однако если попытаться вычислить ту же самую функцию с помощью «неглубокой» (shallow) сети, может потребоваться экспоненциально больше скрытых юнитов .
В качестве примера лектор приводит вычисление функции исключающего ИЛИ (XOR) или четности для входных признаков ($x_1, x_2, ... x_n$) :
- Глубокий подход: Если строить дерево XOR-операций, то глубина сети будет пропорциональна логарифму от количества входных данных ($\log N$) . Количество необходимых вентилей (узлов) при этом будет невелико.
- Неглубокий подход: Если же ограничить сеть всего одним скрытым слоем, то для вычисления четности потребуется экспоненциально большая структура. В таком случае скрытый слой должен будет содержать порядка $2^n$ (точнее $2^{n-1}$) скрытых юнитов, чтобы перечислить все возможные конфигурации входных битов .
Хотя Ын признается, что лично для него результаты теории схем менее полезны для развития интуиции, он отмечает, что на них часто ссылаются для объяснения ценности глубоких представлений .
🏷️ Глубокое обучение как удачный бренд 9:05
Интересным замечанием лектора стало обсуждение самого термина «глубокое обучение» (Deep Learning). Эндрю Ын честно признает, что одной из причин популярности этого направления является удачный брендинг .
Раньше такие системы называли просто «нейронными сетями с множеством скрытых слоев». Однако фраза «глубокое обучение» звучит гораздо эффектнее и помогла захватить воображение широкой публики . Тем не менее, Ын подчеркивает, что за этим PR-брендингом стоит реальная эффективность: глубокие сети действительно работают хорошо .
В практической работе Ын рекомендует придерживаться следующего подхода:
- Не впадать в крайности, настаивая на использовании десятков слоев сразу .
- Начинать решение новой задачи с простой логистической регрессии или сети с одним-двумя скрытыми слоями .
- Рассматривать количество слоев как гиперпараметр, который нужно настраивать в ходе экспериментов.
При этом он подтверждает текущий тренд: для некоторых современных приложений (например, в компьютерном зрении) использование очень глубоких сетей с десятками слоев действительно оказывается наилучшим решением .




