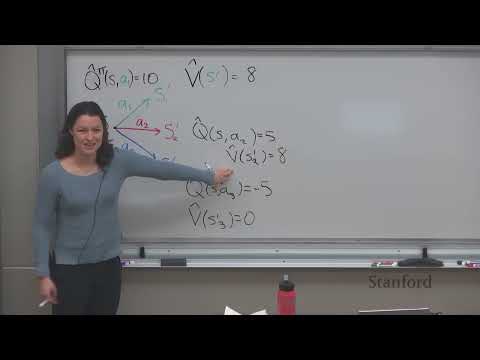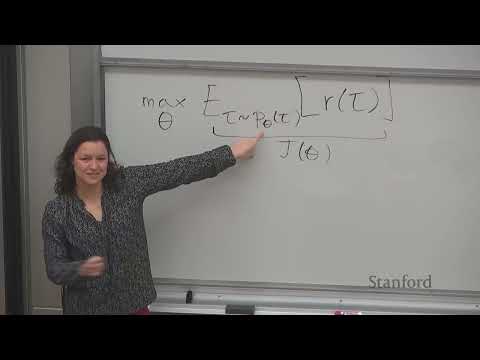
Курс Стэнфордского университета CS224R предлагает глубокое погружение в обучение с подкреплением, и третья лекция цикла посвящена фундаментальному методу — градиентам стратегии (Policy Gradients). Преподаватель подробно разбирает математический вывод алгоритма REINFORCE, исследует проблему высокой дисперсии и предлагает практические подходы для оптимизации траекторий агентов. Рассматриваемый подход подготавливает теоретическую базу для понимания современных систем управления роботами и дообучения больших языковых моделей.
🤖 От подражания к самостоятельному опыту: введение в онлайн-RL 0:05
В рамках обучения с подкреплением классическая задача формулируется через состояния, действия и траектории — последовательности шагов, за которые агент получает определенные награды. Ранее рассмотренное обучение подражанию (Imitation Learning) эффективно и отлично масштабируется, однако оно имеет принципиальное ограничение: агент не может превзойти эксперта, предоставившего демонстрационные данные, и лишен возможности учиться на собственных ошибках. Чтобы преодолеть этот барьер, разработчики используют онлайн-алгоритмы, которые собирают новый опыт непосредственно в процессе взаимодействия с изменяемой средой.
Базовый цикл онлайн-RL включает следующие шаги:
- Инициализация параметров стратегии (политики) случайными весами, методами подражания или с помощью заданных эвристик.
- Активный запуск текущей стратегии в симуляции или реальном мире для сбора пакета актуальных траекторий.
- Использование полученного массива данных для направленного обновления весов нейронной сети.
- Повторение процесса: сбор новых данных уже обновленной моделью и следующий шаг оптимизации.
Этот циклический процесс проб и ошибок лежит в основе градиентов стратегии (Policy Gradients). Подобные методы находят широкое применение на практике: от обучения моторике многоногих роботов до выравнивания ответов современных языковых моделей (LLM).
📐 Математическая магия: выводим ванильный градиент стратегии 4:38
Главная математическая цель в обучении с подкреплением — максимизировать ожидаемую сумму наград. Мы можем записать целевую функцию как целевой функционал $J(\theta) = \mathbb{E}{\tau \sim p\theta(\tau)} [R(\tau)]$, где $\tau$ — траектория, а $R(\tau)$ — кумулятивная награда вдоль нее. Чтобы обучать нейросеть стандартным градиентным спуском, необходимо вычислить градиент $J(\theta)$ по параметрам сети $\theta$. Напрямую дифференцировать операцию взятия выборки (sampling) нельзя, к тому же распределение траекторий зависит от динамики переходов среды, которая алгоритму изначально неизвестна.
Для обхода этого препятствия лектор использует классический статистический трюк с логарифмической производной (log-derivative trick). Представив математическое ожидание в виде интеграла по пространству траекторий, мы можем внести оператор градиента внутрь, поскольку интегрирование является линейной операцией. Базовое равенство из исчисления $\nabla_\theta p_\theta(\tau) = p_\theta(\tau) \nabla_\theta \log p_\theta(\tau)$ позволяет изящно вернуть выражение к форме математического ожидания:
$$\nabla_\theta J(\theta) = \mathbb{E}{\tau \sim p\theta(\tau)} [\nabla_\theta \log p_\theta(\tau) R(\tau)]$$
Это ключевой сдвиг в вычислениях, поскольку дифференцируемые параметры $\theta$ теперь находятся внутри знака ожидания, и выражение можно аппроксимировать по конечной выборке. Расписав вероятность траектории $p_\theta(\tau)$ через произведение начального распределения, условных вероятностей действий стратегии $\pi_\theta(a_t|s_t)$ и динамики среды, мы берем от него логарифм. При переходе к градиенту все компоненты, описывающие физику среды и начальные условия, зануляются, так как они вообще не зависят от параметров модели $\theta$.
В итоге мы получаем строгую формулу ванильного градиента стратегии (Vanilla Policy Gradient), лежащую в основе алгоритма REINFORCE:
$$\nabla_\theta J(\theta) = \mathbb{E}{\tau \sim p\theta(\tau)} \left[ \sum_{t=1}^T \nabla_\theta \log \pi_\theta(a_t | s_t) R(\tau) \right]$$
Смысл этой формулы интуитивно понятен: это градиент обучения подражанию, но масштабированный на величину полученной награды. Алгоритм подталкивает нейросеть увеличивать логарифмическую вероятность тех действий, которые в итоге привели к высокому положительному результату, и снижать вероятность шагов, замеченных в провальных сессиях.
🏃♂️ Проблема дисперсии на примере «падающего» гуманоида 26:59
Несмотря на математическую стройность, алгоритм REINFORCE страдает от колоссального уровня шума и высокой дисперсии градиентных оценок. Преподаватель иллюстрирует уязвимость подхода наглядным примером: обучением робота-гуманоида ходьбе в симуляторе, где награда привязана к скорости движения вперед. Предположим, на первой итерации необученная модель генерирует 5 случайных траекторий:
- Робот сразу заваливается и падает назад (отрицательная награда).
- Робот падает плашмя вперед (технически продвигается вперед, получая небольшую положительную награду).
- Робот замирает и неподвижно стоит на месте (нулевая награда).
- Робот делает один хороший шаг вперед, но затем теряет баланс и падает назад (суммарная награда становится отрицательной).
- Робот делает резкий шаг назад, а затем слегка дергается вперед (итоговая награда отрицательна).
Если загрузить этот пакет данных в ванильный алгоритм REINFORCE, вычисленный градиент заставит робота целенаправленно падать вперед или стоять на месте. Траектории 1, 4 и 5 получат отрицательные веса, из-за чего алгоритм начнет подавлять абсолютно все действия внутри них. Тот факт, что в четвертой попытке робот вначале совершил прекрасное и правильное движение, полностью игнорируется, так как финальный штраф за падение «замазал» промежуточный успех. Модель оказывается чрезвычайно чувствительной к случайному шуму в собранных выборках.
⏳ Укрощение шума: причинно-следственные связи и награда за будущее 30:58
Первый шаг к снижению дисперсии заключается в интеграции фундаментального принципа причинности (causality). В базовом уравнении REINFORCE вероятность действия на условном 100-м шаге умножается на общую награду всей траектории, включая то, что произошло на шагах с 1 по 99. Однако очевидно, что текущее решение агента никак не могло повлиять на события и награды из прошлого.
Для оптимизации уравнения кумулятивная награда всей траектории $R(\tau)$ заменяется более точечным показателем — «наградой к получению» (reward-to-go). Теперь для каждого конкретного временного шага $t$ суммируются только будущие награды, начиная с текущего моментов и до конца сессии:
$$\sum_{t'=t}^T R(s_{t'}, a_{t'})$$
Это изолирует влияние прошлых шагов от оценки текущего действия. Рассмотрим измененный сценарий: стратегия агента улучшилась, робот совершает 4 новые попытки — падение вперед, медленное ковыляние, уверенная ходьба и быстрый бег. Во всех этих случаях итоговая награда окажется строго положительной. Без учета причинности алгоритм продолжал бы активно поощрять даже неуклюжее ковыляние, замедляя сходимость к идеалу. Использование награды за будущее позволяет модели быстрее отсекать неэффективные паттерны движений и фокусироваться на максимизации скорости.
⚖️ Метод базовой линии: как вычитание среднего спасает обучение 41:44
Другая серьезная проблема градиентов стратегии — уязвимость к абсолютному масштабу функции наград. Если среда возвращает только положительные значения, градиент будет увеличивать вероятность абсолютно всех действий, которые агент совершил за сессию, независимо от их реального качества. Для устранения этого перекоса применяется метод базовой линии (baseline). Из расчетной награды вычитается константа $b$, в роли которой чаще всего выступает математическое ожидание (среднее значение) награды по всему текущему пакету данных:
$$\nabla_\theta J(\theta) = \mathbb{E}{\tau \sim p\theta(\tau)} \left[ \sum_{t=1}^T \nabla_\theta \log \pi_\theta(a_t | s_t) (R(\tau) - b) \right]$$
Лектор математически доказывает строгость этого приема: при развертывании интеграла ожидание градиента логарифма, умноженного на константу $b$, в точности равняется нулю. Следовательно, введение базовой линии не вносит никаких искажений в финальное решение (остается несмещенным — unbiased), но радикально снижает дисперсию градиента. Действия, показавшие результат выше среднего по больнице, поощряются, а отработавшие хуже среднего — эффективно подавляются.
Тем не менее, градиент стратегии по-прежнему требует непрерывных, плотных (dense) сигналов обратной связи. Преподаватель демонстрирует это на задаче, где робот должен сложить куртку (награда 1 за идеальный результат, 0.5 за складки и 0, если задача провалена). Если робот успешно разровнял рукава, но бросил вещь на пол, суммарная награда будет нулевой. С базовой линией эта частично успешная попытка получит такой же отрицательный вес, как если бы робот вообще не прикоснулся к куртке, и ценный промежуточный навык будет безвозвратно стерт из памяти модели.
🔄 Смена парадигмы: от On-Policy к Importance Sampling 55:08
Главный экономический и вычислительный минус классических градиентов стратегии заключается в их on-policy природе. Математическое ожидание в формуле REINFORCE жестко завязано на распределение траекторий, генерируемых исключительно текущей версией стратегии $\pi_\theta$. Стоит инженерам сделать хотя бы один шаг градиентного спуска и минимально обновить веса нейросети, как весь накопленный массив траекторий мгновенно обесценивается. Сбор гигантского объема данных для каждого одиночного шага оптимизации делает обучение запредельно долгим.
Чтобы перейти к off-policy режиму и получить возможность совершать множество шагов оптимизации на одном и том же пакете данных, исследователи привлекают метод выборки по значимости (Importance Sampling). Этот статистический подход позволяет корректно оценить ожидание функции по целевому распределению $p(x)$, имея на руках выборку из другого, «предлагающего» распределения $q(x)$:
$$\mathbb{E}{x \sim p}[f(x)] = \mathbb{E}{x \sim q}\left[\frac{p(x)}{q(x)} f(x)\right]$$
Интегрируя этот метод в RL, мы можем использовать стабильные данные, собранные старой версией стратегии $\pi_{\theta_{old}}$, умножая награду на отношение вероятностей действий в новой и старой моделях. На практике вычисление этого веса для протяженных траекторий наталкивается на перемножение сотен дробей, из-за чего итоговый коэффициент может мгновенно обнулиться или уйти в бесконечность.
Чтобы стабилизировать расчеты, разработчики идут на осознанное допущение: они принимают отношение распределений состояний среды за единицу, ограничиваясь лишь дробью вероятностей конкретных действий $\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}$. Хотя данный шаг математически не является абсолютно точным, он открывает возможность многократно прогонять бэкпроп по одной выборке. Именно этот подход лег в основу современных продвинутых алгоритмов Actor-Critic и популярного метода PPO, разбор которых запланирован на следующую лекцию.