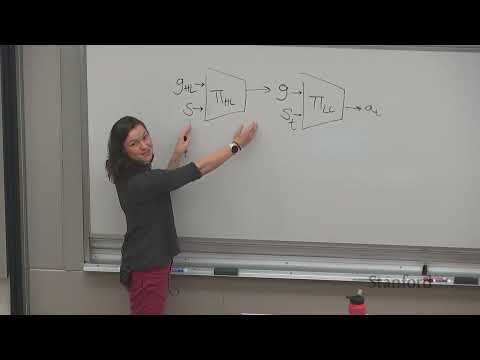Мета-обучение в подкреплении: как агенты учатся адаптироваться 🧠 2:35
Лекция посвящена концепции мета-обучения с подкреплением (Meta-RL), которое позволяет агентам переносить опыт из предыдущих задач для быстрого решения новых. В отличие от обычного обучения с подкреплением (RL), где агент начинает обучение с нуля, Meta-RL стремится сократить разрыв между эффективностью обучения человека и медлительностью классических RL-систем.
🔄 Проблема переноса опыта и few-shot обучение 5:56
В основе Meta-RL лежит идея передачи знаний от прошлых задач к будущим. Спикер выделяет несколько подходов:
- Fine-tuning (дообучение): Стандартный метод, при котором модель, обученная на одной задаче, адаптируется под новую. Эффективен, если задачи очень похожи.
- Multi-task learning: Попытка решить несколько задач одновременно. Если у задач есть общая структура (например, команды «подними бутылку», «подними телефон»), возможен «zero-shot» перенос — решение новой задачи без дополнительного опыта.
- Meta-learning: Ориентирован на «few-shot» адаптацию, когда модель обучается адаптироваться к новой задаче, используя всего несколько проб или примеров.
Мета-обучение в RL отличается от supervised-вариантов необходимостью решать проблему исследования (exploration): агент должен самостоятельно построить обучающий набор данных, взаимодействуя со средой.
🏗️ Архитектура и «черный ящик» Meta-RL 20:35
Концептуально Meta-RL можно реализовать с помощью моделей последовательностей (трансформеров или рекуррентных нейронных сетей).
- Принцип работы: Политика агента обусловливается (conditions) накопленным опытом — набором данных из предыдущих состояний, действий и полученных наград в текущем MDP (Марковском процессе принятия решений).
- Отличия от стандартного RL: Агент «запоминает» контекст задачи, активно использует вознаграждение как входной сигнал и обучается сразу на распределении задач, а не на одном MDP.
В процессе обучения агент пробует свои силы в серии задач, сохраняя память через несколько эпизодов (обычно $N$ эпизодов). Оптимизация происходит по сумме наград для всех задач в обучающем распределении. На этапе тестирования модель, обученная эффективно исследовать, может адаптироваться к новой задаче всего за один эпизод.
🔍 Исследование против эксплуатации 54:08
Главный вызов Meta-RL — баланс между исследованием (поиском информации о новой среде) и эксплуатацией (извлечением награды).
- Конец-в-конец (End-to-end): Прямая оптимизация награды теоретически идеальна, но на практике сложна. Агент может получить награду случайно, не научившись стратегии исследования, или столкнуться с «проблемой курицы и яйца»: чтобы научиться решать задачу, нужно её исследовать, а чтобы исследовать, нужно понимать, что искать.
- Альтернатива (Thompson Sampling): Использование апостериорного распределения над задачами. Агент строит скрытое представление (latent representation) задачи и действует согласно ему.
- Риски: Подобные стратегии могут быть крайне неэффективны, если цена «ошибочного» исследования велика (например, если агенту нужно потратить дни, чтобы пройти по ложному коридору в лабиринте).
В заключение отмечается, что хотя Meta-RL дает мощные инструменты для быстрой адаптации в робототехнике и лингвистических моделях, выбор метода (конец-в-конец или вспомогательные цели для исследования) сильно зависит от конкретной доменной области.