В истории глубокого обучения существуют архитектуры, которые не просто показали хорошие результаты, а определили вектор развития всей индустрии. В рамках обучающего курса от DeepLearning.AI основатель компании Эндрю Ын (Andrew Ng) разбирает три фундаментальные сверточные нейронные сети: LeNet-5, AlexNet и VGG-16. Эти модели демонстрируют переход от простых систем распознавания рукописных цифр к гигантским сетям, способным классифицировать тысячи объектов на реальных фотографиях.
🏛️ LeNet-5: Классика распознавания образов 0:00
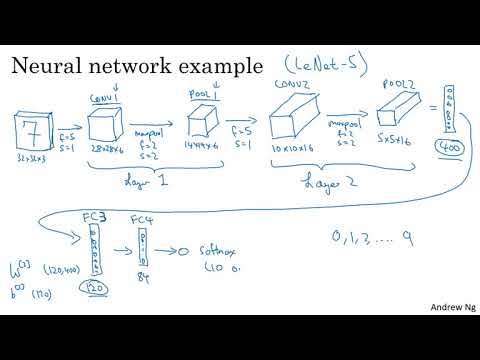
Разработанная в 1998 году, LeNet-5 была создана для распознавания рукописных цифр в чеках и почтовых отправлениях . На входе сеть принимает серое (одноканальное) изображение размером 32x32 пикселя. По современным меркам это крошечная модель, содержащая всего около 60 000 параметров, тогда как современные сети часто оперируют десятками и сотнями миллионов .
Архитектура LeNet-5 строится по следующей схеме:
- Первый этап: 6 фильтров размером 5x5 со страйдом (шагом) 1. Это дает на выходе объем 28x28x6 .
- Пулинг: Использование Average Pooling (усредняющее объединение) с фильтром 2x2 и страйдом 2, что сокращает размерность вдвое до 14x14x6 . Эндрю Ын отмечает, что в современных реализациях вместо усредняющего пулинга чаще используется Max Pooling (максимальное объединение) .
- Второй этап: Слой свертки с 16 фильтрами 5x5, уменьшающий размерность до 10x10x16, за которым следует еще один слой пулинга, доводящий результат до 5x5x16 .
- Полносвязные слои: На выходе сверточных слоев получается 400 узлов (5x5x16), которые подключаются к полносвязному слою из 120 нейронов, затем к слою из 84 нейронов и, наконец, к выходному слою с 10 значениями (от 0 до 9) .
Эндрю Ын обращает внимание на исторический контекст: в оригинальной статье 1998 года использовались нелинейности Sigmoid и Tanh вместо современного ReLU . Кроме того, из-за ограниченных вычислительных мощностей авторы применяли сложные схемы, где разные фильтры смотрели на разные каналы входного блока, что сегодня считается излишним усложнением .
🚀 AlexNet: Прорыв в компьютерном зрении 7:04
Архитектура AlexNet, названная в честь первого автора Алекса Крижевского (также соавторами выступили Илья Суцкевер и Джеффри Хинтон), стала поворотным моментом для всей индустрии . Именно эта работа убедила сообщество компьютерного зрения в том, что глубокое обучение действительно эффективно работает.
Основные характеристики AlexNet:
- Масштаб: Сеть имеет около 60 миллионов параметров, что в 1000 раз больше, чем у LeNet-5 .
- Входные данные: Цветные изображения 227x227x3 (хотя в статье упоминается 224x224, расчеты Эндрю Ына показывают, что логичнее использовать 227) .
- Инновации: Использование функции активации ReLU, которая значительно ускорила обучение по сравнению с сигмоидами .
Структура сети включает свертки с крупными фильтрами (11x11 в первом слое со страйдом 4), несколько слоев Max Pooling и глубокие полносвязные слои, завершающиеся Softmax-выходом на 1000 классов ImageNet .
В статье об AlexNet упоминаются два специфических аспекта, которые сегодня редко применяются:
- Обучение на двух GPU: В 2012 году графические процессоры имели мало памяти, поэтому сеть буквально разделяли пополам между двумя видеокартами с хитрой схемой коммуникации между ними .
- Local Response Normalization (LRN): Слой локальной нормализации ответа, который должен был ограничивать слишком сильные активации нейронов. По словам Эндрю Ына, последующие исследования показали, что LRN мало влияет на результат, и сам лектор не использует его в своей практике .
📐 VGG-16: Триумф простоты и единообразия 12:35
Если AlexNet была сложной сетью с множеством гиперпараметров, то VGG-16 (авторы Карен Симонян и Эндрю Циссерман) поразила мир своей простотой и логичностью . Основная идея заключалась в использовании только одного типа свертки и одного типа пулинга на протяжении всей сети.
Архитектурные принципы VGG-16:
- Свертка (CONV): Всегда фильтры 3x3, страйд 1, использование padding='same' (сохранение размера) .
- Пулинг (POOL): Всегда Max Pooling с фильтром 2x2 и страйдом 2 .
- Рост глубины: Количество фильтров удваивается после каждого пулинга: 64 -> 128 -> 256 -> 512 .
Число «16» в названии указывает на количество слоев с весами (сверточные и полносвязные) . VGG-16 — это массивная сеть даже по сегодняшним меркам, содержащая около 138 миллионов параметров . Несмотря на большой объем и медлительность, архитектура стала популярной благодаря своей унифицированной структуре: высота и ширина изображения уменьшаются ровно в два раза на каждом этапе пулинга, а количество каналов предсказуемо растет .
📊 Общие закономерности классических сетей 3:42
Эндрю Ын выделяет общие паттерны, которые прослеживаются во всех трех архитектурах и сохраняются в современном дизайне нейросетей:
- Изменение размерности: По мере продвижения вглубь сети (слева направо) высота ($H$) и ширина ($W$) изображения постепенно уменьшаются .
- Увеличение каналов: Одновременно с уменьшением пространственных размеров растет количество каналов (глубина) — например, от 1 до 6, а затем до 16 в LeNet-5, или от 64 до 512 в VGG-16 .
- Типовая последовательность: Почти всегда используется паттерн
[CONV -> POOL], повторяющийся несколько раз, за которым следуют полносвязные слои (FC) и финальныйSoftmax.
Для тех, кто хочет глубже изучить первоисточники, Эндрю Ын рекомендует начинать чтение с работы по AlexNet как самой доступной, затем переходить к VGG, а статью по LeNet-5 оставить напоследок из-за её сложности и устаревшей терминологии .