В рамках курса CS236 Стэнфордского университета рассматриваются сложнейшие концепции глубокого обучения, и шестнадцатая лекция посвящена одной из самых актуальных тем — диффузионным моделям на основе скоринговых функций. В ходе занятия подробно разбирается математическая связь между зашумлением данных, вариационными автокодировщиками (VAE) и стохастическими дифференциальными уравнениями, что позволяет взглянуть на генерацию изображений как на строгий физический процесс.
📊 Основы: Скоринговые функции и очистка от шума 0:05
Фундаментальная идея скоринговых моделей заключается в моделировании распределения вероятностей через так называемую «скоринговую функцию» (score function). Она представляет собой градиент логарифма плотности вероятности по отношению к входным данным: $\nabla_x \log p(x)$. Визуально это можно представить как векторное поле, которое указывает направление к областям с максимальной вероятностью.
Для обучения таких моделей используются лоссы сопоставления скоров (score-matching losses). Однако прямое вычисление градиента для сложных распределений данных затруднительно. Решением становится метод Denoising Score Matching. Вместо оценки скора исходного распределения, модель обучается на данных, возмущенных гауссовым шумом.
Механизм работы Denoising Score Matching:
- Берется чистый образец данных $x$.
- К нему добавляется гауссов шум, что создает новое распределение $q_\sigma$.
- Модель (нейросеть) обучается восстанавливать исходный вектор шума, который был добавлен к изображению.
Как утверждает лектор, решение задачи денойзинга эквивалентно изучению скоринговой функции зашумленного распределения данных. Это позволяет использовать динамику Ланжевена для генерации новых образцов, постепенно двигаясь от случайного шума к высоковероятным регионам данных.
🔄 Диффузия как иерархический вариационный автокодировщик (VAE) 9:31
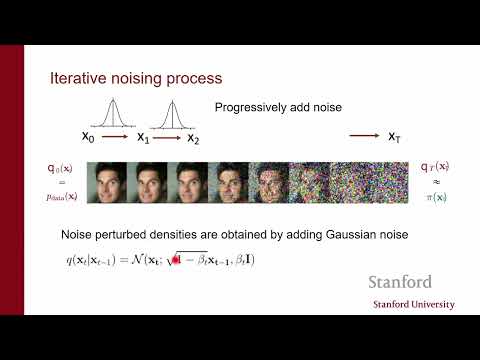
Процесс генерации в диффузионных моделях можно интерпретировать как работу иерархического вариационного автокодировщика (Hierarchical VAE). В этой парадигме мы имеем две цепочки:
- Прямой процесс (Encoder): Постепенное превращение структуры данных в чистый шум путем последовательного добавления небольших порций гауссова шума на каждом шаге $t$. Этот процесс является марковским — каждое следующее состояние зависит только от предыдущего.
- Обратный процесс (Decoder): Обучаемая нейросеть, которая пытается инвертировать зашумление, шаг за шагом восстанавливая структуру из хаоса.
Важной особенностью является то, что в диффузионных моделях энкодер фиксирован. В отличие от классического VAE, где параметры энкодера обучаются, здесь мы просто добавляем шум по заранее заданному расписанию (noise schedule). Декодер же представляет собой глубокий стек слоев (часто до 1000 шагов), где каждый шаг — это маленькая нейросеть, предсказывающая, как убрать шум.
📉 Эквивалентность функций потерь: ELBO против Score Matching 34:22
С математической точки зрения, обучение диффузионной модели через максимизацию нижней границы доказательства (ELBO — Evidence Lower Bound) эквивалентно минимизации лосса сопоставления скоров.
Ключевые выводы математического сравнения:
- Если параметризовать среднее значение гауссианы в декодере через нейросеть $\epsilon_\theta$, которая предсказывает шум, то целевая функция ELBO превращается в стандартный лосс денойзинга.
- Хотя модель выводится из принципов VAE, на практике она оптимизирует скоры зашумленных распределений.
- Лектор отмечает интересный парадокс: теоретически обучение энкодера вместе с декодером должно давать лучшие результаты (более высокое значение ELBO), но на практике фиксированный «шумовой» энкодер дает гораздо более высокое качество визуальных сэмплов. При обучении обоих компонентов изображения часто получаются размытыми, что является классической проблемой VAE.
⚡ Техническая реализация: Шаги и Инструменты 44:57
Для реализации эффективной диффузии необходимо учитывать ряд параметров и архитектурных решений.
Инструментарий и параметры:
- Архитектура: Чаще всего используется U-Net из-за его способности эффективно предсказывать данные той же размерности, что и входные (image-to-image). В последнее время также применяются трансформеры (Transformers).
- Количество шагов (T): Стандартное значение в индустрии — около 1000 шагов.
- Расписание шума (Noise Schedule): Параметры $\beta_t$ и $\alpha_t$, которые определяют скорость разрушения структуры данных.
- Обучение: Модель получает на вход шумное изображение $x_t$ и индекс шага $t$, чтобы предсказать шум $\epsilon$.
По словам спикера, задача разбивается на 1000 маленьких подзадач. Вместо того чтобы пытаться создать изображение из шума за один проход, модель учится делать крошечные исправления. Это делает задачу обучения гораздо более стабильной и эффективной.
🕒 Непрерывное время: Стохастические дифференциальные уравнения (SDE) 55:19
Если представить, что количество шагов зашумления стремится к бесконечности, а временные интервалы становятся бесконечно малыми, мы переходим в область непрерывного времени. В этом случае процесс диффузии описывается стохастическим дифференциальным уравнением (SDE).
SDE описывает изменение состояния $x$ как комбинацию детерминированного дрейфа (drift) и случайного шума (diffusion term). Удивительным открытием является то, что для любого такого уравнения существует «обратное SDE» в закрытой форме, которое позволяет двигаться от шума к данным. Единственным неизвестным компонентом в этом уравнении является всё та же скоринговая функция.
Это позволяет использовать продвинутые численные методы (солверы) для генерации. Существует два типа подходов:
- Predictor (Предсказатель): Прямое решение SDE (например, метод Эйлера-Маруямы).
- Corrector (Корректор): Использование динамики Ланжевена для исправления ошибок численного интегрирования на каждом шаге.
🏎️ Обыкновенные дифференциальные уравнения и точное правдоподобие 1:06:37
Одним из самых мощных расширений теории является возможность конвертации SDE в обыкновенное дифференциальное уравнение (ODE). Это называется Probability Flow ODE.
Преимущества перехода к ODE:
- Детерминизм: Путь от шума к конкретному изображению становится уникальным и обратимым.
- Эффективность: Можно использовать адаптивные солверы ODE, которые требуют гораздо меньше шагов для генерации без потери качества.
- Точное правдоподобие (Exact Likelihood): Поскольку ODE задает обратимое отображение (как нормализующие потоки), мы можем точно вычислить вероятность $p(x)$ для любого входного объекта, используя формулу замены переменных.
[Image comparing jaggy SDE paths with smooth, non-intersecting ODE trajectories]
Таким образом, диффузионная модель, изначально похожая на VAE, легким движением математической руки превращается в нормализующий поток (Normalizing Flow). Это объединяет три главных семейства генеративных моделей в единую теоретическую структуру.




