В современной индустрии искусственного интеллекта диффузионные модели стали золотым стандартом генерации изображений и видео. В рамках курса CS236 в Стэнфордском университете профессор Стефано Эрмон подробно разбирает теоретический фундамент этих технологий, объясняя, как математика «зашумления» данных позволила совершить качественный скачок от классических энергетических моделей к современным генераторам уровня DALL-E и Stable Diffusion.
🧱 Проблема размерности и «масштабируемое» сопоставление оценок 0:05
В основе современных генеративных систем лежит идея обучения нейросети предсказывать градиент логарифма плотности распределения данных — так называемую «оценку» (score). Вместо того чтобы пытаться вычислить саму вероятность (что математически сложно), модель учится строить векторное поле, где каждая стрелка указывает направление к областям с более высокой плотностью данных.
Однако на практике исследователи столкнулись с серьезным препятствием. Как отмечает профессор Эрмон, стандартные методы обучения таких моделей (score matching) требуют вычисления следа матрицы Якобиана (Jacobian), что крайне затратно при работе с изображениями высокого разрешения. Для решения этой проблемы были разработаны два ключевых подхода:
- Denoising Score Matching: Вместо работы с чистыми данными модель обучается восстанавливать оценку зашумленного распределения.
- Sliced Score Matching: Метод, использующий случайные проекции векторов для сопоставления градиентов, что избавляет от необходимости вычислять полные матрицы производных.
🌪️ Почему шум — это решение, а не помеха 9:12
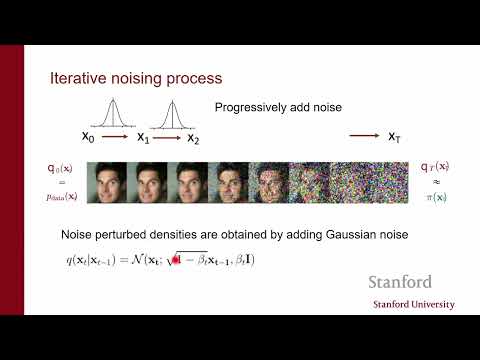
Одной из главных теоретических проблем генеративных моделей является «гипотеза многообразия» (manifold hypothesis). По словам Эрмона, реальные данные (например, фотографии лиц) занимают лишь крошечную долю в пространстве всех возможных комбинаций пикселей. Это приводит к тому, что в регионах с низкой плотностью данных градиенты становятся неопределенными или «взрываются», а алгоритм семплирования (динамика Ланжевена) просто теряется.
Профессор Эрмон утверждает, что добавление гауссова шума магическим образом исправляет эту ситуацию. Как только к изображению добавляется шум, оно «слетает» с узкого многообразия и распределяется по всему пространству. Это делает оценку градиентов устойчивой и позволяет модели обучаться гораздо эффективнее.
Тем не менее, здесь возникает классический компромисс:
- Мало шума: Мы получаем точные данные, но модель плохо обучается в «пустых» зонах.
- Много шума: Обучение идет идеально, но структура данных полностью разрушается, и на выходе мы получаем лишь «среднестатистическое пятно».
🪜 Метод «отжига» и 1000 уровней сложности 23:29
Решением стал метод Annealed Langevin Dynamics (динамика Ланжевена с «отжигом»). Вместо того чтобы выбирать один уровень шума, исследователи предложили использовать целую иерархию — от экстремально высокого зашумления до едва заметного.
Процесс генерации в такой системе напоминает постепенную проявку фотографии:
- Сначала модель работает с чистым шумом, используя градиенты самого грубого уровня.
- Затем полученный результат передается на следующий этап, где уровень шума чуть ниже.
- Шаг за шагом структура изображения уточняется, пока не получится чистая картинка.
В современной практике, как упоминает Эрмон, «магическим числом» часто считается 1000 уровней шума. Чтобы не обучать тысячу отдельных нейросетей, используется одна модель, которая принимает уровень шума $\sigma$ как дополнительный входной параметр.
🌊 Непрерывное время и стохастические дифференциальные уравнения (SDE) 1:01:25
Вершиной развития этой концепции стал переход от дискретных шагов к непрерывному времени. Профессор Эрмон объясняет, что процесс постепенного превращения данных в шум можно описать с помощью стохастических дифференциальных уравнений (SDE).
Если мы можем описать, как данные разрушаются под действием шума (прямой процесс), то, зная «оценку» (градиенты), мы можем обратить время вспять. Это позволяет превратить чистый шум обратно в данные, решая обратное SDE.
Преимущества подхода SDE:
- Гибкость семплирования: Можно использовать продвинутые численные методы решения уравнений, выбирая оптимальное количество шагов уже после обучения модели.
- Связь с потоками (Normalizing Flows): Профессор отмечает, что любое SDE можно превратить в детерминированное обыкновенное дифференциальное уравнение (ODE), которое по сути является «нормализующим потоком» бесконечной глубины.
📊 Диффузия против GAN: кто победил? 57:06
На вопрос студентов о том, почему диффузионные модели вытеснили некогда популярные GAN (генеративно-состязательные сети), Эрмон дает прагматичный ответ. Хотя теоретического доказательства превосходства нет, на практике диффузия гораздо стабильнее в обучении.
В GAN обучение — это игра с нулевой суммой (minimax), которая часто приводит к коллапсу моды. Диффузионные же модели обучаются через простое сопоставление оценок (score matching), что технически является обычной задачей регрессии. Кроме того, диффузия позволяет использовать огромные вычислительные мощности во время генерации (инференса), что дает более детализированные результаты, хотя и делает процесс медленнее.
Интересное замечание из аудитории коснулось «проблемы пальцев»: генеративные модели часто ошибаются в анатомии рук. Профессор Эрмон полагает, что это решается просто увеличением объема обучающих данных, а не фундаментальными изменениями в архитектуре.