Лекция из курса Стэнфордского университета CS236 посвящена глубоким генеративным моделям, а именно развитию концепции моделей на основе скоринга (score-based models) и их эволюции в диффузионные модели. В рамках занятия подробно разбираются проблемы практического применения динамики Ланжевена в пространствах высокой размерности и предлагается элегантное решение через добавление многоуровневого шума. Автор рассматривает как дискретные подходы с контролируемым отжигом, так и фундаментальный непрерывный предел, связывающий генерацию данных со стохастическими дифференциальными уравнениями.
📊 Масштабирование скоринговых моделей и вычислительные барьеры 0:05
Базовая идея моделей на основе скоринга заключается в представлении распределения вероятностей через векторное поле градиентов логарифма правдоподобия, параметризованное нейросетью. Обучение методом сопоставления скоров (score matching) эффективно использует аналитические подходы энергетических моделей, избавляя исследователей от необходимости вычисления сложной нормировочной константы.
Однако лектор подчеркивает, что классический метод сопоставления скоров становится абсолютно нежизнеспособным в многомерных пространствах. Главным вычислительным барьером является необходимость расчета следа Якобиана (trace of the Jacobian), требующего чрезмерного количества шагов обратного распространения ошибки. При попытке моделировать изображения высокого разрешения этот компонент делает вычисления нереализуемыми на практике.
Для обхода этого ограничения в современной практике применяются две масштабируемые альтернативы:
- Denoising score matching (сопоставление скоров с шумоподавлением). Вместо оценки скора чистого распределения данных модель обучается оценивать скор распределения, искаженного шумом через ядро возмущения (например, путем добавления гауссовского шума). По словам спикера, эта задача математически эквивалентна классической регрессии (L2-loss) для предсказания вектора шума, добавленного к чистым данным. Данный подход избавляет от вычисления следа Якобиана и позволяет эффективно использовать стандартные нейросетевые архитектуры денойзеров.
- Sliced score matching (срезанное сопоставление скоров). Вместо выравнивания полных многомерных векторов градиента на каждом шаге алгоритм сопоставляет их проекции вдоль случайных направлений, задаваемых вектором $v$. По утверждению лектора, этот метод позволяет оценивать скор исходной чистой плотности данных и опирается на направленные производные. Тем не менее, он работает несколько медленнее, чем метод с шумоподавлением, так как все еще требует дифференцирования в процессе оптимизации.
Главный компромисс denoising-подхода, как отмечает лектор, заключается в смещении целевой функции: даже при идеальном обучении модель выучивает скор зашумленного распределения, а не исходной чистой плотности.
🧱 Геометрия реальных данных и тупики динамики Ланжевена 7:09
На этапе инференса генерация новых объектов из обученного векторного поля традиционно опирается на динамику Ланжевена (Langevin dynamics), где частицы смещаются по направлению стрелок градиента, чтобы найти области максимальной вероятности. На практике базовый вариант этого алгоритма полностью проваливается при генерации сложных структур вроде изображений. Лектор выделяет три фундаментальные причины этого сбоя:
- Гипотеза многообразия. По мнению лектора, реальные данные в высокомерном пространстве сосредоточены на низкоразмерных многообразиях (low-dimensional manifolds). Пиксели в изображениях линейно зависимы: зная часть из них, можно предсказать остальные. Вне этого узкого многообразия плотность распределения и вероятность равны нулю, из-за чего значение скора математически не определено или испытывает взрывные разрывы.
- Неточность в пустых зонах. Поскольку функция потерь при обучении зависит от сэмплов из обучающей выборки, нейросеть видит только зоны высокой плотности реальных данных. Вдали от них, в пустых пространствах, модель выдает хаотичные градиенты. Попадая туда, динамика Ланжевена теряет направление и не может привести частицы к целевому распределению.
- Низкая скорость смешивания. Процесс Ланжевена стационарен и может бесконечно долго застревать в изолированных модах, не имея возможности преодолеть зоны с нулевой вероятностью и корректно распределить частицы между кластерами данных.
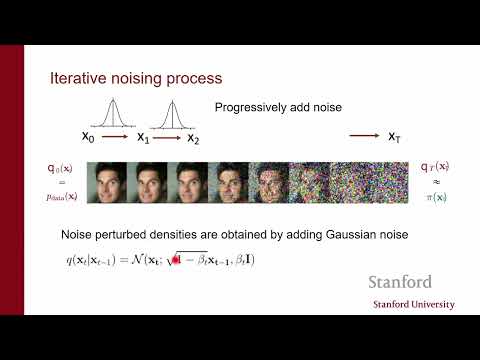
Решением этих проблем становится искусственное добавление гауссовского шума к данным. Даже минимальный шум выталкивает точки за пределы узкого многообразия, распределяя плотность по всему пространству и сглаживая ландшафт. Эксперименты на датасете CIFAR-10 показывают, что сопоставление скоров на чистых изображениях дает крайне нестабильную, «горлышковую» кривую потерь, в то время как добавление минимального шума мгновенно обеспечивает гладкую сходимость.
Тем не менее, возникает жесткая дилемма: при малом шуме модель не справляется с проблемой пустых зон распределения, а при избыточном шуме структура данных полностью уничтожается, и алгоритм генерирует хаотичный шум вместо качественных картинок.
🔄 Метод отжига и единая нейросеть для тысячи задач 22:38
Чтобы обойти дилемму выбора уровня шума, была разработана концепция диффузионных моделей. Лектор указывает, что вместо фиксации одного уровня шума эффективнее использовать целый ансамбль масштабов — от масштабного шума $\sigma_1$ до едва заметного $\sigma_L$. Процесс генерации в такой системе реализуется через динамику Ланжевена с отжигом (annealed Langevin dynamics).
Процедура начинается в области максимального шума, где геометрическая структура данных полностью разрушена, но векторное поле градиентов легко оценивается в любой точке пространства. Частицы делают несколько шагов по грубым стрелкам градиента, формируя базовые очертания. Полученные сэмплы затем используются в качестве начальной инициализации для следующего этапа, где уровень шума снижается. Шаг за шагом алгоритм продвигает частицы в зоны все более высокой плотности, где модель способна оперировать тонкими структурами чистых данных. В финальной точке, при минимальном шуме $\sigma_L$, сэмплы получаются чистыми и детализированными. На вопрос слушателя о количестве шагов лектор ответил, что в современной практике «магическим числом» является использование 1000 дискретных уровней шума.
Для оптимизации вычислений исследователи отказались от идеи обучать 1000 отдельных нейросетей для каждого уровня шума. Вместо этого создается единая условная сеть — Noise-Conditional Score Network. Она принимает на вход как саму зашумленную координату $x$, так и текущий параметр шума $\sigma$. Обучение проводится через комбинированный функционал потерь, где задачи взвешиваются специальным коэффициентом:
$$\mathcal{L}{total} = \sum{i=1}^L \lambda(\sigma_i) \mathbb{E}{q{\sigma_i}(x|x_{clean})} \left[ | s_\theta(x, \sigma_i) - \nabla_x \log q_{\sigma_i}(x|x_{clean}) |^2 \right]$$
Спикер поясняет, что выбор весовой функции $\lambda(\sigma_i)$, пропорциональной самому значению шума $\sigma_i$, является важной практической эвристикой. Благодаря компенсации внутренних масштабирующих факторов градиента, этот шаг позволяет нейросети уделять одинаковое внимание как грубой макроструктуре на больших шумах, так и микродеталям на минимальных масштабах возмущения.
📈 Непрерывный предел: стохастические дифференциальные уравнения 1:00:50
Естественным развитием дискретного отжига становится переход к непрерывному пределу, где количество уровней шума стремится к бесконечности. В этой парадигме индекс уровня шума заменяется непрерывной временной переменной $t \in [0, T]$. В момент времени $t=0$ мы имеем чистое распределение данных $p_0$, а к моменту $t=T$ под воздействием нарастающего шума распределение $p_T$ трансформируется в белый гауссовский шум, полностью теряя исходную информацию.
Математическим каркасом для описания такой плавной деградации структуры выступает стохастическое дифференциальное уравнение (SDE). Прямой процесс зашумления можно представить как непрерывное случайное блуждание (random walk) частиц. Фундаментальный теоретический прорыв состоит в том, что любой такой диффузионный процесс можно развернуть во времени вспять. Как заявляет лектор, существует точное SDE обратного времени (reverse-time SDE), описывающее движение от хаотичного шума обратно к чистым данным:
$$dx = \left[ f(x, t) - g(t)^2 \nabla_x \log p_t(x) \right] dt + g(t) d\bar{w}$$
Единственным неизвестным компонентом в данном уравнении является функция скора $\nabla_x \log p_t(x)$ для каждого промежуточного зашумленного распределения. Подставляя вместо нее обученную нейросеть $s_\theta(x, t)$, исследователи получают полностью определенную генеративную систему.
Для сэмплинга применяются развитые численные методы решения стохастических уравнений, например, дискретизация по методу Эйлера. На каждом шаге вспять по времени алгоритм вычисляет детерминированный сдвиг по вектору скора от нейросети и добавляет строго выверенную компенсирующую порцию случайного шума. Спикер подчеркивает, что этот подход дает исследователям гибкость: на этапе инференса они больше не привязаны к жесткой сетке из 1000 шагов обучения и могут использовать любые продвинутые SDE-солверы для ускорения генерации.
⚖️ Сравнительный анализ с GAN и переход к детерминированным потокам 1:17:47
Комментируя причины, по которым диффузионные скоринговые модели вытеснили генеративно-состязательные сети (GAN) и заняли доминирующее положение в индустрии, лектор отмечает, что строгих теоретических доказательств их фундаментального превосходства не существует. Их успех обусловлен чисто прагматическими и архитектурными факторами:
- Глубина вычислительного графа. Процесс решения обратного SDE на этапе инференса фактически формирует бесконечно глубокий вычислительный граф за счет тысяч последовательных шагов денойзинга. При этом во время обучения этот граф не нужно разворачивать в память, в отличие от глубоких рекуррентных или состязательных сетей.
- Стабильность оптимизации. Диффузионные модели обучаются через среднеквадратичное отклонение в рамках сопоставления скоров. Здесь нет нестабильного минимаксного противостояния (minimax) генератора и дискриминатора, что исключает коллапс мод и делает обучение предсказуемым.
- Инкрементальные улучшения. Модель обучается решать простую локальную задачу — как немного улучшить зашумленное изображение на микроскопическом шаге, а итоговое качество складывается из суммы этих малых шагов.
В финальной части лекции спикер раскрывает глубинную математическую связь между диффузией и нормализующими потоками (normalizing flows). Согласно уравнению Фоккера — Планка, для любого стохастического процесса (SDE) существует эквивалентный ему абсолютно детерминированный процесс, описываемый обыкновенным дифференциальным уравнением (Probability Flow ODE). Этот детерминированный ландшафт обладает в точности теми же маргинальными распределениями плотности $p_t(x)$ в каждый момент времени и так же полностью управляется векторным полем скора.
Интегрирование Probability Flow ODE позволяет трансформировать диффузионную модель в непрерывный нормализующий поток (continuous-time normalizing flow). Траектории движения разных объектов в таком уравнении никогда не пересекаются. Это обеспечивает строго обратимое и взаимно однозначное отображение между пространством реальных изображений и скрытым пространством латентных векторов шума одинаковой размерности. Лектор подводит итог: данный холистический взгляд позволяет не только генерировать реалистичные сэмплы, но и использовать диффузионные модели для точного вычисления точечного правдоподобия (likelihood) объектов, объединяя лучшие свойства разных семейств генеративного ИИ.