Лекция Стэнфордского университета по генеративным моделям: Скоринговые модели и диффузия
Лекция 13 курса CS236 «Глубинные генеративные модели» посвящена score-based моделям (скоринговым моделям) и диффузионным процессам. Ведущий курса объясняет, почему этот класс моделей стал современным стандартом (SOTA) для генерации изображений, видео и аудио, а также разбирает фундаментальные математические подходы к их обучению и проблемам, с которыми сталкиваются исследователи.
🧬 Переход от плотностей к скоринговым функциям 3:26
В классических генеративных моделях основной задачей является моделирование вероятностной плотности $p(x)$ или функции массы вероятности. Основная сложность здесь заключается в необходимости нормализации функции, чтобы интеграл по всему пространству был равен 1.
- Модели на основе правдоподобия (Likelihood-based): Использование авторегрессионных моделей или нормализующих потоков (normalizing flows) ограничивает архитектуру нейронных сетей.
- Energy-based модели (EBM): Позволяют использовать гибкие архитектуры, но требуют вычисления сложной константы нормализации, что затрудняет обучение.
Score-based модели предлагают альтернативный подход: моделировать не саму плотность, а её градиент — скоринговую функцию (score function), определяемую как $\nabla_x \log p(x)$.
- Преимущество: Скоринговая функция — это векторное поле, где каждый вектор указывает направление наиболее быстрого возрастания логарифмического правдоподобия.
- Упрощение: В отличие от плотностей, скоринговая функция не требует соблюдения условий нормализации (интегрирования в 1), что делает архитектуры более гибкими.
📊 Математика обучения: Fisher Divergence 8:27
Для обучения скоринговых моделей используется минимизация дивергенции Фишера (Fisher divergence) — разности между истинным векторным полем градиентов данных и векторным полем, предсказываемым моделью.
Главная техническая проблема при попытке оптимизации такой модели — наличие следа Якобиана (trace of the Jacobian) в целевой функции. Прямое вычисление производных в больших размерностях оказывается крайне затратным, так как требует количества операций обратного распространения ошибки, масштабирующегося линейно с размерностью входных данных.
🛠 Масштабируемые методы: Denoising Score Matching 31:52
Для обхода вычислительных сложностей предлагаются методы, которые позволяют обучать модели в условиях высокой размерности.
Denoising Score Matching (Denoising-скоринг)
Основная идея — оценивать градиент не самих данных, а данных, возмущенных шумом.
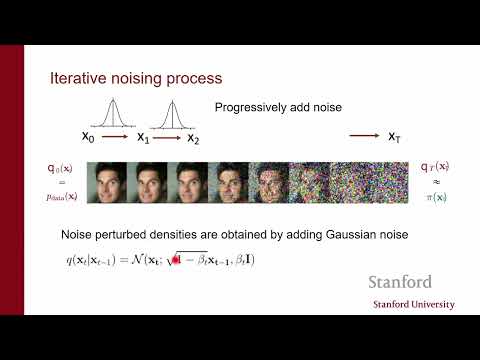
- Процесс: К данным добавляется гауссовский шум. Оказывается, что задача оценки скоринга для такой «размытой» плотности математически эквивалентна классической задаче шумоподавления (denoising).
- Преимущество: Этот подход избавляет от необходимости вычислять след Якобиана, превращая обучение в задачу оптимизации L2-потери между предсказанием сети и фактически добавленным шумом.
- Интерпретация: Модель обучается «угадывать» шум, который нужно вычесть из картинки, чтобы вернуть её в состояние чистых данных.
Sliced Score Matching (Слайсинговый скоринг)
Альтернативный метод для эффективного обучения без шума заключается в использовании случайных проекций.
- Вместо сравнения векторов в полном пространстве, они проецируются на случайные направления $v$.
- Это сводит задачу к одномерной, где производные по направлению могут быть вычислены за один шаг обратного распространения ошибки (backprop).
🧪 Генерация образцов: Langevin Dynamics 1:09:54
После того как модель обучена, возникает вопрос: как генерировать данные, если у нас нет явного правдоподобия?
Лектор объясняет, что можно использовать процедуру Ланжевена (Langevin MCMC). Идея заключается в следующем:
- Инициализировать частицы случайным шумом.
- Итеративно обновлять частицы, следуя направлению градиента скоринговой функции.
- Добавлять небольшое количество шума на каждом шаге (для перемешивания).
Однако, по словам автора, этот базовый подход сталкивается с проблемами:
- Данные лежат на низкоразмерных многообразиях, где скоринговая функция может быть плохо определена.
- Модели плохо обучаются в регионах с низкой плотностью данных, что делает генерацию нестабильной.
- Процесс перемешивания (mixing) между разными модами распределения происходит слишком медленно.
Лектор заключает, что именно эти трудности с «застреванием» Ланжевена в локальных модах привели к созданию диффузионных моделей (diffusion models), которые в следующей лекции будут представлены как решение для корректного оценивания скоринга во всем пространстве.