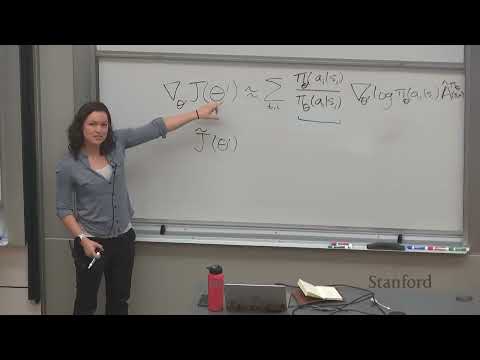
Продвинутые методы обучения с подкреплением: от PPO до SAC 5:59
Современные методы обучения с подкреплением (Reinforcement Learning, RL) эволюционировали от простых градиентов политики к более эффективным подходам, позволяющим переиспользовать данные и ускорять обучение. В лекции Стэнфордского университета (Stanford CS224R) рассматриваются два фундаментальных алгоритма: PPO (Proximal Policy Optimization) и SAC (Soft Actor-Critic), которые решают проблему нестабильности и эффективности обучения.
⚖️ Проблема стабильности и проксимальная оптимизация (PPO) 6:12
Основная проблема при обучении с подкреплением заключается в том, что данные, собранные старой политикой, теряют актуальность после обновления параметров нейронной сети. Если обновлять политику слишком агрессивно, возникает риск переобучения и краха процесса обучения.
Для решения этой задачи PPO вводит несколько ключевых механизмов:
- Важность весов (Importance Weights): Позволяет использовать данные, собранные предыдущими версиями политики, для выполнения нескольких шагов градиентного спуска.
- Ограничение отклонений (Surrogate Objective): Использование суррогатной целевой функции помогает контролировать шаг обновления.
- Клиппинг (Clipping): В PPO используется ограничение коэффициента вероятности (отношения новой политики к старой) в диапазоне от
1 - epsilonдо1 + epsilon(обычно 0.2). Это снимает стимул у модели слишком сильно менять политику на одном шаге. - Нижняя оценка (Lower Bound): PPO максимизирует нижнюю границу оригинальной целевой функции, что гарантирует стабильность и предотвращает резкие падения качества.
Для оценки преимущества (Advantage) в PPO часто применяют метод GAE (Generalized Advantage Estimate), который позволяет варьировать горизонт планирования, балансируя между смещением и дисперсией.
🔄 Переиспользование опыта: Replay Buffer и SAC 46:44
В то время как PPO оптимизирует использование данных внутри одного батча, алгоритмы вроде SAC (Soft Actor-Critic) стремятся быть максимально off-policy, используя «буфер воспроизведения» (replay buffer) — хранилище всего опыта, накопленного в ходе обучения.
- Replay Buffer: Позволяет обновлять политику на основе мини-батчей, случайно выбранных из всех предыдущих взаимодействий, что значительно повышает эффективность использования данных.
- Проблема Q-функции: При использовании данных из буфера от прошлых политик возникает вопрос, для какой именно политики мы оцениваем ценность состояния. SAC решает это через рекурсивное определение Q-функции, где для оценки следующего шага используется текущая политика.
- Преимущество SAC: Алгоритм позволяет быть гораздо более эффективным по данным, чем PPO, что делает его предпочтительным для задач, где получение нового опыта «дорого» (например, управление реальными роботами).
🏁 Сравнение и выводы 1:07:11
Выбор между PPO и SAC зависит от конкретной задачи:
- PPO — стандарт выбора для задач, где важна стабильность. Он отлично показывает себя в симуляциях (где данных много) и в обучении языковых моделей.
- SAC — более data-efficient алгоритм, идеально подходящий для сложных манипуляций в реальном мире или на физических роботах, но требующий более тщательной настройки гиперпараметров.
Несмотря на различия, оба метода объединяет общая цель — сделать процесс обучения предсказуемым и способным к масштабированию на сложные, высокоразмерные среды.




