PPO
9 статей
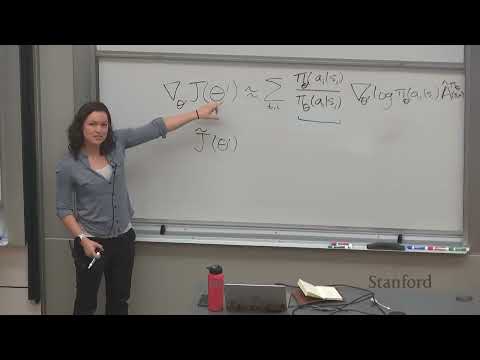 1ч 09м
1ч 09м⚖ Stanford CS224R: PPO и SAC как стандарты обучения с подкреплением
 1ч 47м
1ч 47м🛠 Тюнинг LLM: как методы PPO и DPO превращают нейросети из автодополнителей в полезных помощников
1ч 47м🎯 Стэнфорд: «Ваша языковая модель — это на самом деле скрытая модель вознаграждения»
 1ч 08м
1ч 08м🧬 Нейтан Ламберт о жизни после DPO: почему PPO все еще лучше, но сложнее
 1ч 18м
1ч 18м📉 Direct Preference Optimization: почему исследователи переходят на DPO
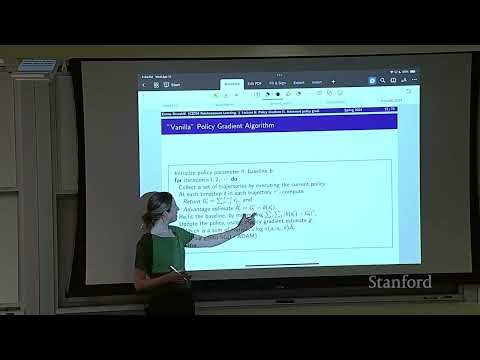 1ч 19м
1ч 19м🛡 Стэнфорд о PPO: «Почему это самый полезный метод в RL»
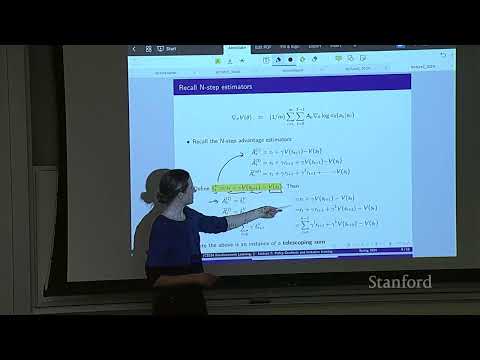 1ч 18м
1ч 18м🛠 От PPO до Dagger: современные методы обучения агентов
 53 мин
53 мин🔄 Янник Кильчер разобрал метод Reinforced Self-Training от Google DeepMind
 38 мин
38 мин📊 Исследование Google Brain: как правильно настроить on-policy RL-агента