В лекции курса CS236 Стэнфордского университета рассматривается фундаментальный сдвиг в разработке генеративных моделей: переход от моделирования функции плотности вероятности к моделированию её градиента — функции оценки (score function). Этот подход лежит в основе современных диффузионных нейросетей, которые сегодня доминируют в генерации изображений, видео и аудио.
🎯 От правдоподобия к функции оценки 3:39
Долгое время в машинном обучении доминировали модели на основе правдоподобия (likelihood-based models), такие как авторегрессионные модели, VAE или потоки (flows). Главный объект в них — функция плотности вероятности $p(x)$, которая сопоставляет входным данным $x$ скаляр, определяющий их «правдоподобность». Однако у этого подхода есть существенный недостаток: функция плотности должна быть нормализована, то есть интеграл по всему пространству должен быть равен единице.
Это требование накладывает жесткие ограничения на архитектуру нейросетей:
- Необходимость использовать специфические слои в нормализующих потоках.
- Вычислительная сложность оценки константы нормализации (Z) в энергетических моделях (EBM).
- Нестабильность обучения в неявных моделях типа GAN, где приходится решать задачу минимаксной оптимизации.
Альтернативой выступают модели на основе оценки (score-based models). По словам лектора, вместо того чтобы работать с самой плотностью $p(x)$, эффективнее работать с градиентом её логарифма по входным данным: $\nabla_x \log p(x)$. Этот вектор указывает направление, в котором нужно изменять данные, чтобы максимально быстро увеличить их правдоподобность.
🔌 Преимущества «безбилетной» нормализации 5:30
Главное преимущество использования функции оценки — избавление от константы нормализации. В физике это аналогично переходу от электрического потенциала к напряженности электрического поля.
Когда мы берем логарифм плотности вероятности в энергетической модели, мы получаем сумму энергии и логарифма константы нормализации $Z_\theta$. Поскольку $Z_\theta$ не зависит от входных данных $x$, её градиент по $x$ равен нулю. Это означает, что для обучения модели нам больше не нужно вычислять площадь под кривой распределения. Мы можем использовать любую гибкую нейросеть, которая на выходе выдает вектор той же размерности, что и входные данные.
📉 Проблема «ванильного» сопоставления оценок 26:43
Обучение такой модели происходит через минимизацию расхождения Фишера (Fisher divergence). Мы стремимся к тому, чтобы векторное поле градиентов нашей модели максимально соответствовало векторному полю реального распределения данных.
Однако прямое вычисление функции потерь сталкивается с вычислительным барьером: необходимо вычислять след матрицы Якобиана (trace of the Jacobian). Это требует суммы частных производных каждого выхода нейросети по каждому входу. В современных задачах с изображениями высокой четкости (тысячи и миллионы измерений) количество операций обратного распространения ошибки начинает расти линейно с размерностью данных, что делает обучение практически невозможным.
🛠 Масштабируемые решения: Денойзинг 31:52
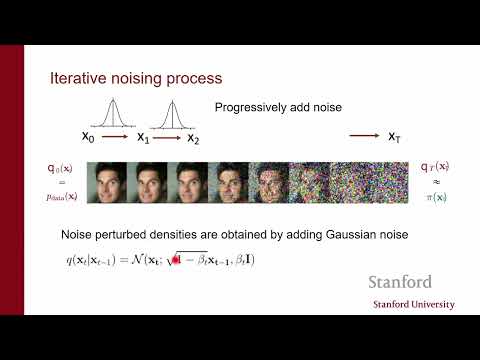
Для решения проблемы размерности лектор выделяет два основных метода. Первый — Denoising Score Matching (сопоставление оценок через шумоподавление).
Вместо того чтобы искать градиенты «чистых» данных, мы добавляем к ним небольшой объем гауссова шума. Оказывается, что задача оценки градиента зашумленного распределения математически эквивалентна задаче очистки изображения от шума (denoising).
Алгоритм работы выглядит следующим образом:
- Берется чистый объект из обучающей выборки.
- К нему добавляется шум с дисперсией $\sigma^2$.
- Нейросеть (модель оценки) получает на вход зашумленный объект и пытается предсказать вектор шума, который был добавлен.
По мнению лектора, это превращает сложную задачу генеративного моделирования в одну из самых простых и понятных задач для нейросетей — денойзинг. Если шум достаточно мал, полученная функция оценки будет очень близка к реальной.
🗡 Метод проекций: Sliced Score Matching 59:32
Второй метод — Sliced Score Matching (сегментированное сопоставление оценок). Вместо того чтобы сравнивать многомерные векторы целиком, мы проецируем их на случайное направление $v$ и сравниваем полученные скаляры.
Это позволяет заменить вычисление следа Якобиана на вычисление производной по направлению. По словам лектора, такая операция выполняется всего за один проход обратного распространения ошибки, независимо от размерности данных. Хотя метод вносит дополнительную дисперсию (variance) из-за случайного выбора направлений, на практике он оказывается крайне эффективным и стабильным.
🌀 Генерация через динамику Ланжевена 1:09:54
Когда модель обучена выдавать правильные векторы «оценок», возникает вопрос: как создать новое изображение? Поскольку у нас нет формулы плотности, мы используем итеративный процесс — динамику Ланжевена (Langevin MCMC).
Процесс генерации:
- Начинаем с абсолютно случайного шума.
- Делаем шаг в направлении, которое указывает наша модель оценки (двигаемся к максимуму плотности).
- Добавляем немного случайного шума на каждом шаге, чтобы не застрять в локальном оптимуме и правильно исследовать распределение.
Если повторять этот процесс достаточно долго с очень маленькими шагами, теоретически мы получим идеальный образец из искомого распределения.
⚠️ Почему это не работает «из коробки»? 1:14:07
Несмотря на красивую теорию, простые модели на основе оценок часто терпят неудачу на реальных данных типа MNIST или CIFAR-10. Лектор выделяет три критические проблемы:
- Проблема многообразий (Manifold Hypothesis): Реальные данные часто лежат на низкоразмерных подмножествах (многообразиях). Вне этих подмножеств оценка градиента не определена или стремится к бесконечности.
- Низкая плотность данных: В областях, где нет обучающих примеров, нейросеть выдает случайные векторы. Если процесс генерации (MCMC) попадет в такую «пустыню», он никогда не найдет дорогу обратно к реальным данным.
- Проблема весов мод: Функция оценки (градиент) не содержит информации о том, какая «гора» на ландшафте вероятности выше. Если распределение состоит из двух изолированных кластеров, модель может распределить плотность между ними поровну (50/50), даже если в реальности один кластер встречается в 10 раз чаще другого.
Как утверждает лектор, решение этих проблем привело к созданию современных диффузионных моделей, которые будут подробно разобраны на следующей лекции.