Поиск
Найдено: 50
 2ч 10м
2ч 10м🕵 Стратегический обман: как ИИ учится манипулировать разработчиками
 3ч 14м
3ч 14м📐 Иллюзия AGI: почему нейросети учатся обману, а не сонастройке
 52 мин
52 мин🧠 Как научить ИИ думать абстракциями: гид по непрерывному RL
 37 мин
37 мин🧠 Гокул Свами: «Многие маршруты в Google Maps рассчитываются через инверсное обучение с подкреплением»
2ч 10м🎭 ИИ научился обманывать: как модели саботируют тесты безопасности
 2ч 35м
2ч 35м🧠 Путь к безопасному ИИ: от имитации к объективной реальности
 25 мин
25 мин🚀 Илон Маск: «Colossus 2 и Grok 5 станут ключом к достижению AGI»
 2ч 37м
2ч 37м🧠 Феномен AlphaGo: как сжать бесконечный поиск в нейросеть
 53 мин
53 мин🧠 Марк Чен и Якуб Пахоцкий раскрыли долгосрочную стратегию OpenAI
 1ч 25м
1ч 25м🧠 Камьяр Азиззаденешели: интеграция LLM и алгоритмов AlphaGo определит будущее робототехники
 28 мин
28 мин🤖 Как система SayCan от Google объединяет нейросети и робототехнику
 1ч 09м
1ч 09м🧠 Как Meta-RL позволяет агентам адаптироваться к новым задачам „на лету“
 3ч 31м
3ч 31м🧠 Как устроены LLM: от «зип-файла интернета» до рассуждающих моделей
 3ч 18м
3ч 18м🚀 «Притворное выравнивание»: почему ИИ лжет, чтобы выжить, и как его остановить
 52 мин
52 мин🧠 Профессор Челси Финн об основах глубокого обучения с подкреплением в Стэнфорде
 34 мин
34 мин🤖 Уэс Рот: почему ИИ создает собственные «тайные» стратегии рассуждений
 9 мин
9 мин🧩 Илья Суцкевер: «Зрение и язык — это одна и та же задача для ИИ»
 2ч 01м
2ч 01м🚀 В тисках градиентного спуска: хроника захвата мира искусственным интеллектом
 58 мин
58 мин🛡 Мариус Хоббан: «У модели o1 есть базовые способности для стратегического обмана»
 1ч 10м
1ч 10м🧱 Stanford CS224R Deep Reinforcement Learning | Spring 2025 | Lecture 10: RL for LLM Reasoning
 24 мин
24 мин🎮 Почему ИИ учится неделями, а человек адаптируется мгновенно?
 1ч 07м
1ч 07м⚖ Методы Offline RL: от имитации к оптимизации стратегий
 2ч 05м
2ч 05м🤖 Как попасть в OpenAI без PhD за шесть недель
 42 мин
42 мин🚀 GPT-5 и эра агентов: Кристина Ким о том, почему «данные — это новая таблетка»
 44 мин
44 мин🤖 Как стартап Physical Intelligence создает универсальную модель для любых роботов
 45 мин
45 мин🚀 Опыт Cursor и Fireworks: распределенная инфраструктура для RL-обучения Composer 2
 2ч
2ч🧠 Почему искусственные нейросети пугающе похожи на мозг
 2ч 54м
2ч 54м🤖 Восемь лет до сингулярности: как ИИ построит «Потемкинскую деревню»
 1ч 25м
1ч 25м🧬 Том Захави: «Обучение с подкреплением — самый общий фреймворк для AGI»
 1ч 47м
1ч 47м🧠 Стэнфорд CME295: Как алгоритм GRPO и DeepSeek R1 изменили логику нейросетей
 34 мин
34 мин🚀 Дарио Амодеи о будущем ИИ: «Мы увидим страну гениев в одном дата-центре»
 58 мин
58 мин🧠 Джоэль Пино из Cohere: почему законы масштабирования работают и как ИИ повысит продуктивность в 10 раз
 2ч 53м
2ч 53м🚀 Цена мысли: почему инференс меняет правила игры в ИИ
 27 мин
27 мин🧠 a16z: Как DeepSeek R1 обрушил стоимость обучения ИИ и открыл новую эру рассуждающих моделей
 1ч 01м
1ч 01м🚀 Александр Ванг: «Будущее экономики — это управление роем агентов»
 1ч 14м
1ч 14м🧠 Техлид Gemini 2.5 Джек Рэй о цепочках мыслей, латентном пространстве и пути к AGI
 1ч 02м
1ч 02м🔄 Стэнфордский курс CS224R: математический вывод градиентов политики в RL
 2ч 04м
2ч 04м🤖 Почему мы — невыровненный ИИ: угрозы сверхразумного будущего
 1ч 33м
1ч 33м🌊 Йошуа Бенжио: «GFlowNets — это обучаемая замена методам Монте-Карло»
 55 мин
55 мин🧠 Как решать новые задачи в RL без переобучения: разбор Янника Килчера
 1ч
1ч🚨 Лирон Шапира об ИИ-гонке: «Вызвать демона легче, чем им управлять»
 17 мин
17 мин🤖 Джордж Хотц и Лекс Фридман: как программистские мемы объясняют устройство мира
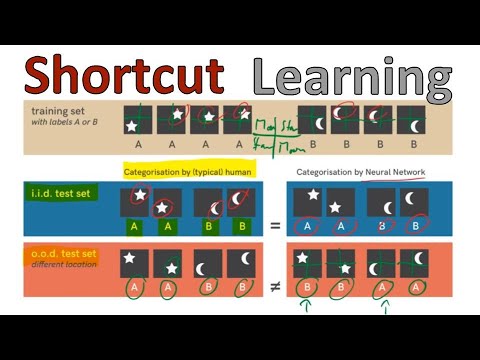 49 мин
49 мин🧠 Феномен Shortcut Learning: почему нейросети находят лазейки в данных вместо понимания
 1ч 22м
1ч 22м🛠 Как оптимизировать инференс языковых моделей: от архитектуры до vLLM
🛠 Кайл Корбитт из CoreWeave: «Мы уже находимся в петле рекурсивного самосовершенствования ИИ»
 50 мин
50 мин🎮 Как ошибка в медиане влияет на оценку ИИ
 30 мин
30 мин🧠 Ян Лекун и Рэндалл Балестриеро: «Обучение с подкреплением неэффективно»
 2ч 45м
2ч 45м🧠 Байесовская механика: как ИИ учится выживать и «мыслить»
 40 мин
40 мин🤖 Absolute Zero: как ИИ учится программировать без людей и почему ученых пугает «uh-oh момент»
 1ч 13м
1ч 13м🔄 От симуляции такси до ChatGPT: как максимизация энтропии и отзывы людей обучают современный ИИ