Поиск
Найдено: 50
 22 мин
22 мин🤖 Заменяет ли простая аугментация годы исследований в сфере RL?
 26 мин
26 мин🔄 Шмидхубер выворачивает ИИ наизнанку: детальный разбор концепции Upside-Down RL
 17 мин
17 мин🚀 Уэс Рот о новой революции в RL: «Эра компактных и дешевых учителей ИИ настала»
 49 мин
49 мин⚖ Лекция в Стэнфорде: развитие интеллекта роботов через RL
 28 мин
28 минCURL: обучение ИИ на «сырых» пикселях без учителя
 37 мин
37 мин🧠 Гокул Свами: «Многие маршруты в Google Maps рассчитываются через инверсное обучение с подкреплением»
 1ч 07м
1ч 07м🤖 Сергей Левин об эволюции обучения с подкреплением: от «бандитов» в ChatGPT до роботов-трансформеров
 2ч 45м
2ч 45м🧠 Байесовская механика: как ИИ учится выживать и «мыслить»
 1ч 20м
1ч 20м🧠 Стэнфордский курс CS234: принципы офлайн-RL и преодоление неопределенности
 1ч 12м
1ч 12мDREAM: как научить ИИ исследовать и обучаться эффективнее
 34 мин
34 мин🌍 Дарио Амодеи: «К 2027 году ИИ превзойдет большинство людей»
 17 мин
17 мин🥇 Математический триумф ИИ: детали победы Gemini DeepThink и OpenAI на IMO
 1ч 25м
1ч 25м🧠 Камьяр Азиззаденешели: интеграция LLM и алгоритмов AlphaGo определит будущее робототехники
 1ч 03м
1ч 03м🤖 Пирамида данных для манипуляций: как Stanford обучает роботов сложному поведению
 38 мин
38 мин🤖 Абхишек Гупта: «Мы должны выпустить роботов из лабораторий в наши дома»
 1ч 18м
1ч 18м🛠 От PPO до Dagger: современные методы обучения агентов
 24 мин
24 мин🎮 Почему ИИ учится неделями, а человек адаптируется мгновенно?
 1ч 18м
1ч 18м🤖 От случайного блуждания до Q-Learning: как ИИ учится на своих ошибках
 29 мин
29 минЯнник Килчер: как заставить роботов «думать на ходу»?
 24 мин
24 мин🧠 Сэм Альтман: «Сверхчеловеческий ИИ-кодер появится к концу 2025 года»
 3ч 14м
3ч 14м📐 Иллюзия AGI: почему нейросети учатся обману, а не сонастройке
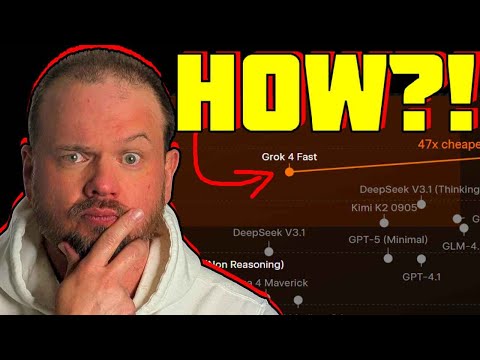 29 мин
29 мин🚀 Почему Grok 4 Fast в 47 раз дешевле конкурентов: разбор стратегии xAI
 54 мин
54 мин🚀 Эван Рейзер (Poolside): «Обучение на исполнении кода — это путь к созданию AGI»
 20 мин
20 мин🧠 Вес Рот о Grok 4.20: «Четыре агента спорят друг с другом перед ответом»
 50 мин
50 мин🤝 Скотт Ву (Cognition) о сделке с Windsurf и будущем ИИ-агентов
 1ч 08м
1ч 08м🤖 Санбэ Ким: «Языковые модели не решат проблемы робототехники»
 1ч 05м
1ч 05м🎓 Анджни Мидха: «Чипы сегодня — это не товар, а дефицит, цена которого только растет»
 39 мин
39 мин🎙 Уэс Рот и экс-директора Google: как самообучение ИИ без участия человека изменит индустрию
 3ч 31м
3ч 31м🧠 Как устроены LLM: от «зип-файла интернета» до рассуждающих моделей
 1ч 16м
1ч 16мМеханика обучения моделей: лектор Стэнфорда о GRPO
 13 мин
13 мин🚀 Технический разбор DeepSeek: почему китайская модель R1 стоит в разы дешевле аналогов
🛠 Кайл Корбитт из CoreWeave: «Мы уже находимся в петле рекурсивного самосовершенствования ИИ»
 45 мин
45 мин🚀 Опыт Cursor и Fireworks: распределенная инфраструктура для RL-обучения Composer 2
 25 мин
25 мин🚀 Уэс Рот о DeepSeek R1: китайский прорыв к сильному ИИ через самоэволюцию
 5ч 06м
5ч 06м🧠 DeepSeek: Как китайский хедж-фонд взломал монополию Кремниевой долины
 17 мин
17 мин🧠 Янник Килчер: «Эджлорды из Discord обошли техногигантов в демократизации ИИ»
 1ч 36м
1ч 36м🛑 Эйсо Кант: «Вы не придете к AGI с помощью файн-тюнинга»
 53 мин
53 мин🧠 Марк Чен и Якуб Пахоцкий раскрыли долгосрочную стратегию OpenAI
 2ч 13м
2ч 13м🚀 Экономика кремния: как физика памяти ограничивает развитие ИИ
 12 мин
12 мин🤖 Прорыв из Беркли: как языковые модели обучаются без внешней оценки через метод Intuititor
 1ч 13м
1ч 13м🧠 Лекция Stanford CS221: От табличных методов к Actor-Critic
53 мин🧠 Эра Vibe Coding: как лидеры OpenAI Марк Чен и Якуб Пахоцкий меняют разработку ИИ
 2ч 52м
2ч 52м🚀 Тираны эффективности: как ИИ перекраивает экономику и жизнь
 2ч 35м
2ч 35м🧠 Путь к безопасному ИИ: от имитации к объективной реальности
 59 мин
59 мин🧠 Педро Домингос: «Современный успех ИИ — это локальный оптимум, а не финал»
 51 мин
51 мин🚀 Ричард Сохер: «Мы строим поисковик, который понимает ваши намерения»
 58 мин
58 мин🎓 Гурдип Полл из Microsoft: «Мы строим Windows для автономных систем»
 47 мин
47 мин🕹 Как классическая игра NetHack помогает обучать нейросети будущего
 1ч 15м
1ч 15м🤖 Как алгоритмы Стэнфорда находят скрытые уязвимости в критических системах
 10 мин
10 мин🧩 Обучение с подкреплением от Google: как вспомогательные задачи решают проблему редких наград