Поиск
Найдено: 50
 2ч 55м
2ч 55м🤖 Почему ИИ обманывает: инженерный подход к безопасности алгоритмов
 2ч 44м
2ч 44м📸 Как победить технологических гигантов: правила игры Кевина Систрома
 49 мин
49 мин🔄 От слепого робопса до Tesla Optimus: как алгоритмы Reinforcement Learning меняют робототехнику
 1ч 10м
1ч 10м🎮 Профессор Эмма Бранскилл об эволюции алгоритмов исследования в обучении с подкреплением
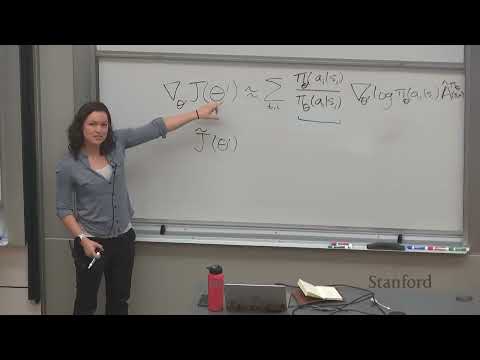 1ч 09м
1ч 09м⚖ Stanford CS224R: PPO и SAC как стандарты обучения с подкреплением
 37 мин
37 мин🧠 Гокул Свами: «Многие маршруты в Google Maps рассчитываются через инверсное обучение с подкреплением»
 1ч 19м
1ч 19м🚀 Профессор Бранскилл: «Обучение с подкреплением — это ключ к интеллекту»
 1ч 36м
1ч 36м🚀 Эйсо Кант: «Вы не сможете дообучить свой путь к AGI»
 29 мин
29 мин🚀 Почему Grok 4 Fast в 47 раз дешевле конкурентов: разбор стратегии xAI
 26 мин
26 мин🎮 NVIDIA GTC'21, открытый симулятор MuJoCo и нейросети в Google Sheets
 34 мин
34 мин🧠 AMP: как обучить ИИ-персонажей двигаться естественно?
 45 мин
45 мин🤖 Янник Килчер о Q-Learning: как ИИ учится принимать решения
 2ч 51м
2ч 51м🛸 Эго как промпт: сооснователь OpenAI о природе сильного интеллекта
 3ч 28м
3ч 28м🧠 Андрей Карпатый: ИИ как инопланетный артефакт и конец биологии
 51 мин
51 мин🛠 Питер Чен: «Мы строим фундаментальный мозг для роботов»
 52 мин
52 мин🧠 Профессор Челси Финн об основах глубокого обучения с подкреплением в Стэнфорде
 1ч 56м
1ч 56м🤖 Майкл Литтман: будущее ИИ и уроки обучения с подкреплением
 10 мин
10 мин🧩 Обучение с подкреплением от Google: как вспомогательные задачи решают проблему редких наград
 1ч 18м
1ч 18м🤖 От случайного блуждания до Q-Learning: как ИИ учится на своих ошибках
 2ч 45м
2ч 45м🧠 Байесовская механика: как ИИ учится выживать и «мыслить»
 2ч 45м
2ч 45м🧠 Ян Лекун: почему модели мира важнее языковых способностей
 24 мин
24 мин🎮 Почему ИИ учится неделями, а человек адаптируется мгновенно?
 47 мин
47 мин🕹 Как классическая игра NetHack помогает обучать нейросети будущего
 1ч 07м
1ч 07м🤖 Сергей Левин об эволюции обучения с подкреплением: от «бандитов» в ChatGPT до роботов-трансформеров
 24 мин
24 минЯнник Килчер о PCGRL: «Дизайн уровня как игра»
 35 мин
35 мин🌍 Как обучить робота без вознаграждений? Разбор алгоритма Plan2Explore
 1ч 44м
1ч 44м🎮 От Atari до ChatGPT: как ИИ учится на своих ошибках?
 24 мин
24 мин🧠 Сэм Альтман: «Сверхчеловеческий ИИ-кодер появится к концу 2025 года»
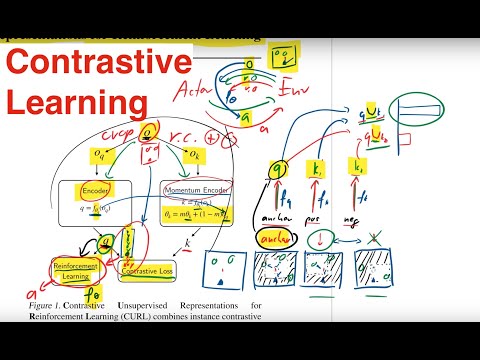 28 мин
28 минCURL: обучение ИИ на «сырых» пикселях без учителя
 1ч 18м
1ч 18м🛠 От PPO до Dagger: современные методы обучения агентов
 1ч 19м
1ч 19м💻 Мария Ша о будущем программирования и обучении нейросетей
 1ч 22м
1ч 22м🤖 Как глубокое обучение с подкреплением меняет робототехнику и теорию управления
 1ч 11м
1ч 11м🚀 Как создавался OpenAI: Грег Брокман о 72 часах хаоса и пути к AGI
 42 мин
42 мин🧩 Янник Килчер: «Язык как ключ к эффективному обучению агентов»
 44 мин
44 мин🚀 Янник Кильчер о Searchformer: «Обучение модели мышлению действительно работает»
 19 мин
19 мин🤖 Обучение на чужих ошибках: Янник Кильхер разбирает бенчмарк D4RL для Offline RL
1ч 36м🛑 Эйсо Кант: «Вы не придете к AGI с помощью файн-тюнинга»
 18 мин
18 мин🎓 Стэнфордский ИИ-путеводитель: как выбрать подходящие курсы и построить карьеру в Deep Learning
 43 мин
43 мин🍔 Гэри Рен из DoorDash: «ML предсказывает хаос, а математика находит из него выход»
 29 мин
29 мин🌍 Как заставить ИИ планировать только там, где он знает?
 39 мин
39 мин🕹 Как ИИ от DeepMind научился играть в Atari: разбор классической статьи от Янника Килчера
 2ч 04м
2ч 04м🧠 Парадокс интеллекта: почему модели o3 меняют правила игры
 59 мин
59 мин🧠 Педро Домингос: «Современный успех ИИ — это локальный оптимум, а не финал»
 30 мин
30 мин🌍 Братья Бенджио: история пионеров глубокого обучения, хрупкость нейросетей и будущее ИИ
 1ч 13м
1ч 13м🧩 Stanford CS234 Reinforcement Learning I Tabular MDP Planning I 2024 I Lecture 2
 1ч 18м
1ч 18м🧠 Эмма Бранскилл о DQN: «Реплей-буфер — ключ к прогрессу»
 1ч 15м
1ч 15м🏛 Эд Трикер из Graham Capital: как управлять $18 млрд с помощью адаптивных квант-моделей
 32 мин
32 мин👨 Как Google DeepMind создает универсальный ИИ-мозг для роботов
 35 мин
35 мин🚀 Почему будущее ИИ за логикой (Reasoning), а не просто масштабом
 38 мин
38 мин🧠 Как предобучение трансформеров на Википедии помогает в обучении роботов