Поиск
Найдено: 50
 1ч 01м
1ч 01м🔄 Эволюция Q-Learning: от уравнений Беллмана до алгоритмов DQN и Double DQN
 28 мин
28 мин🤖 Как система SayCan от Google объединяет нейросети и робототехнику
 1ч 03м
1ч 03м🔄 Эволюция алгоритмов Actor-Critic: как Стэнфорд обучает нейросети на ошибках
 1ч 20м
1ч 20м🛠 Профессор Стивен Бойд объяснил конструктивный анализ выпуклости в Стэнфорде
 1ч 36м
1ч 36м🧠 Илья Суцкевер: «Мы возвращаемся из эпохи масштабирования в эпоху исследований»
 1ч 20м
1ч 20м📉 Стивен Бойд: «Любой локальный оптимум выпуклой задачи является глобальным»
 1ч 19м
1ч 19м🛡 Стэнфорд о PPO: «Почему это самый полезный метод в RL»
 58 мин
58 мин🤖 Как Google SayCan объединяет языковые модели и робототехнику
 1ч 20м
1ч 20м🚀 Stanford CS336: секреты обучения reasoning-моделей DeepSeek-R1, Kimi и Qwen
 22 мин
22 мин🧱 Как научить робота крутить вентили за 10 кликов: разбор Dynamical Distance Learning
 2ч 34м
2ч 34м🧠 Алгоритмы внутри нас: как хакнуть мозг с помощью науки
 57 мин
57 мин🌐 Минчи Цзян: «Графики метрик скрывали реальные слепые зоны агента»
 1ч 47м
1ч 47м🛠 Тюнинг LLM: как методы PPO и DPO превращают нейросети из автодополнителей в полезных помощников
 2ч 44м
2ч 44м📸 Как победить технологических гигантов: правила игры Кевина Систрома
 13 мин
13 мин🔄 Дэвид Сильвер о Deep RL: «В нейросетях с миллиардом параметров нет локальных минимумов»
 50 мин
50 мин🎮 Как ошибка в медиане влияет на оценку ИИ
 28 мин
28 мин🤖 Как обучить робота-дворцкого? Новые подходы Стэнфорда к обобщению задач
🤖 Как проект RT-X объединил 34 лаборатории и ускорил обучение роботов
 1ч 49м
1ч 49м🧠 Как RAG, Tool Calling и агенты связывают LLM с реальным миром: лекция CME295 в Стэнфорде
 3ч 19м
3ч 19м🌐 Проклятие размерности: почему нейросети всегда занимаются экстраполяцией
 45 мин
45 мин🚀 Тони Джебара о будущем: «Алгоритмы должны мыслить долгосрочно»
 1ч 10м
1ч 10м🎯 Профессор Стэнфорда разобрал ключевые вызовы и методологию исследований Deep RL
 1ч 13м
1ч 13м🔄 Подход Model-Based RL: как Стэнфорд обучает сложных роботов за четыре часа
 35 мин
35 мин🌍 Как обучить робота без вознаграждений? Разбор алгоритма Plan2Explore
 54 мин
54 мин🎮 Мартин Шмид о Player of Games: „Универсальный алгоритм для любой игры“
1ч 47м🎯 Стэнфорд: «Ваша языковая модель — это на самом деле скрытая модель вознаграждения»
 1ч 20м
1ч 20мМетоды оценки политики: Монте-Карло против Temporal Difference
 1ч 51м
1ч 51м🧠 Теория всего от нейробиологии: как Карл Фристон связывает физику, разум и машинное обучение
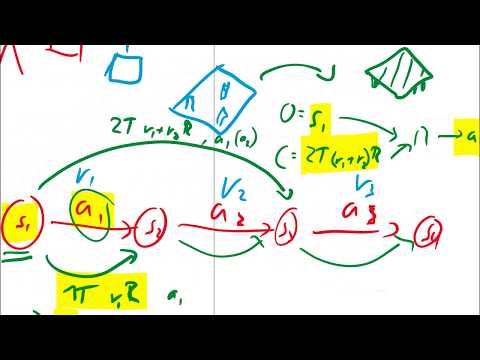 26 мин
26 мин🔄 Шмидхубер выворачивает ИИ наизнанку: детальный разбор концепции Upside-Down RL
 18 мин
18 мин🤖 Илья Суцкевер: «Возможно создать ИИ, желающий подчиняться человеку»
 1ч 01м
1ч 01м🎲 Янник Кильхер разобрал ИИ-агента CICERO от Meta AI, вошедшего в топ-10% игроков в „Дипломатию“
 52 мин
52 мин🧠 Профессор Челси Финн об основах глубокого обучения с подкреплением в Стэнфорде
 1ч 10м
1ч 10м🧱 Stanford CS224R Deep Reinforcement Learning | Spring 2025 | Lecture 10: RL for LLM Reasoning
 1ч 13м
1ч 13м🧩 Stanford CS234 Reinforcement Learning I Tabular MDP Planning I 2024 I Lecture 2
 50 мин
50 минАникайт из Стэнфорда: «Почему ваше Q-обучение нестабильно?»
 1ч 01м
1ч 01м📈 Даг Адамик: как сократить цикл сделки и почему скидки не работают
 1ч 23м
1ч 23м🎯 Профессор Ральф Кини: «Решения — единственный способ осознанно менять жизнь»
 1ч 47м
1ч 47м🧠 DeepSeek R1 против OpenAI o1: как алгоритм GRPO изменил правила игры в ИИ
1ч 47м🧠 Стэнфорд CME295: Как алгоритм GRPO и DeepSeek R1 изменили логику нейросетей
 1ч 15м
1ч 15м🧩 Лекция в Стэнфорде: приближенные offline-методы планирования в пространствах убеждений
 3ч 09м
3ч 09м🤖 Как RLHF превращает текстовые симуляторы в опасных агентов
 3ч 48м
3ч 48м🧠 Цена конца света: почему экзистенциальные риски — это экономика
 2ч 32м
2ч 32м🦈 Иллюзия реальности: Эндрю Хьюберман о скрытых механизмах мозга
 54 мин
54 мин🎭 Патологическая продуктивность: как распознать скрытую депрессию за внешней успешностью
 40 мин
40 мин📈 Построение функции SDR в стартапе: опыт Сэма Блонда из Brex
 2ч 38м
2ч 38м🛸 Кризис науки, калибровочная экономика и Геометрическое Единство Эрика Вайнштейна
 2ч 29м
2ч 29м💡 От блефа к доверию: как ИИ учится договариваться с людьми
 3ч 35м
3ч 35м🚀 Java для профи: от первого кода до архитектуры объектов
 6ч 27м
6ч 27м🌐 Цифровая трансформация с Google Cloud: архитектура, безопасность и экономика
 2ч 37м
2ч 37м🧠 Феномен AlphaGo: как сжать бесконечный поиск в нейросеть